
쥬피터 노트북 관련 아나콘다가 설치된 경로
C:\Anaconda3\Lib\site-packages\joblib\externals\loky\backend
에서 resorce_tracker의 'ascii' → 'utf-8'로 수정
오늘의 에러 해결을 요약하면 위와 같습니다.
당연히 바로 수정하기엔 어려울테니, 천천히 한번 보겠습니다.
stackoverflow에 올라온 해결책으로 빠르게 보실 분들은
링크를 보셔도 빠르게 해결할 수 있습니다.
에러 해결 참조원본
한글 버전 해결은 아래로🏃♀️
gs_model은 이렇게 지정.
gs_model = GridSearchCV(model, parameter, n_jobs=-1, scoring ='f1',
cv = 3)gs_model.fit(X_train, y_train)
오늘의 에러 발단은 필자가 쥬피터 노트북을 통해 어떤 csv 데이터로 XGBoostClassifier 모델을 사용하여
분류 문제를 보는 상황이었습니다. 여기서 하이퍼 패러미터를 하려고 GridSearchCV를 사용하는 상황이었습니다.
이부분에서 멈추게 되네요.
C:\Anaconda3\lib\site-packages\joblib\externals\loky\backend\resource_tracker.py in _send(self, cmd, name, rtype)
202
203 def _send(self, cmd, name, rtype):
--> 204 msg = '{0}:{1}:{2}\n'.format(cmd, name, rtype).encode('ascii')
205 if len(name) > 512:
206 # posix guarantees that writes to a pipe of less than PIPE_BUF
UnicodeEncodeError: 'ascii' codec can't encode characters in position 18-23: ordinal not in range(128)
에러 본문
위와 같이 장문의 에러가 반환되었습니다.
원인은 에러 코드를 살펴봤을때 알 수 있듯이 'ASCII' 코덱을 인코딩할 수 없었기 때문에 중간에
막힌 것으로 추정 됩니다.
일단 몇가지 구글링을 해보고, solution을 찾아서 정리했습니다만
결론부터 말하자면 한가지 해결책이 아니라 두 가지 해결책이 뒤섞여 있는 문제입니다.
먼저, 아래 경로로 들어갑니다.
필자는 C:에 Anaconda3를 바로 설치했기 때문에 아래 파일 탐색기가 보입니다.
C:\Anaconda3\Lib\site-packages\joblib\externals\loky\backend
보시는 분께서 다른 경로에 설치했다면, 아마 다른 경로로 들어가셔야 할겁니다.

위 파일 탐색기에서 resource_tracker를 수정해야 합니다.
여기선 죄송하지만 미리 파이썬 실행기가 설치되어 있어야 합니다.
(대부분 설치 됬을것이라 믿습니다)
일단 필자는 EDLE로 열었습니다.

여기로 들어오시고, 아래 코드를 검색해 주시면 됩니다(ctrl+f)
def _send(self, cmd, name, rtype):
그럼 아까 봤던 에러와 비슷한 문구가 보입니다!
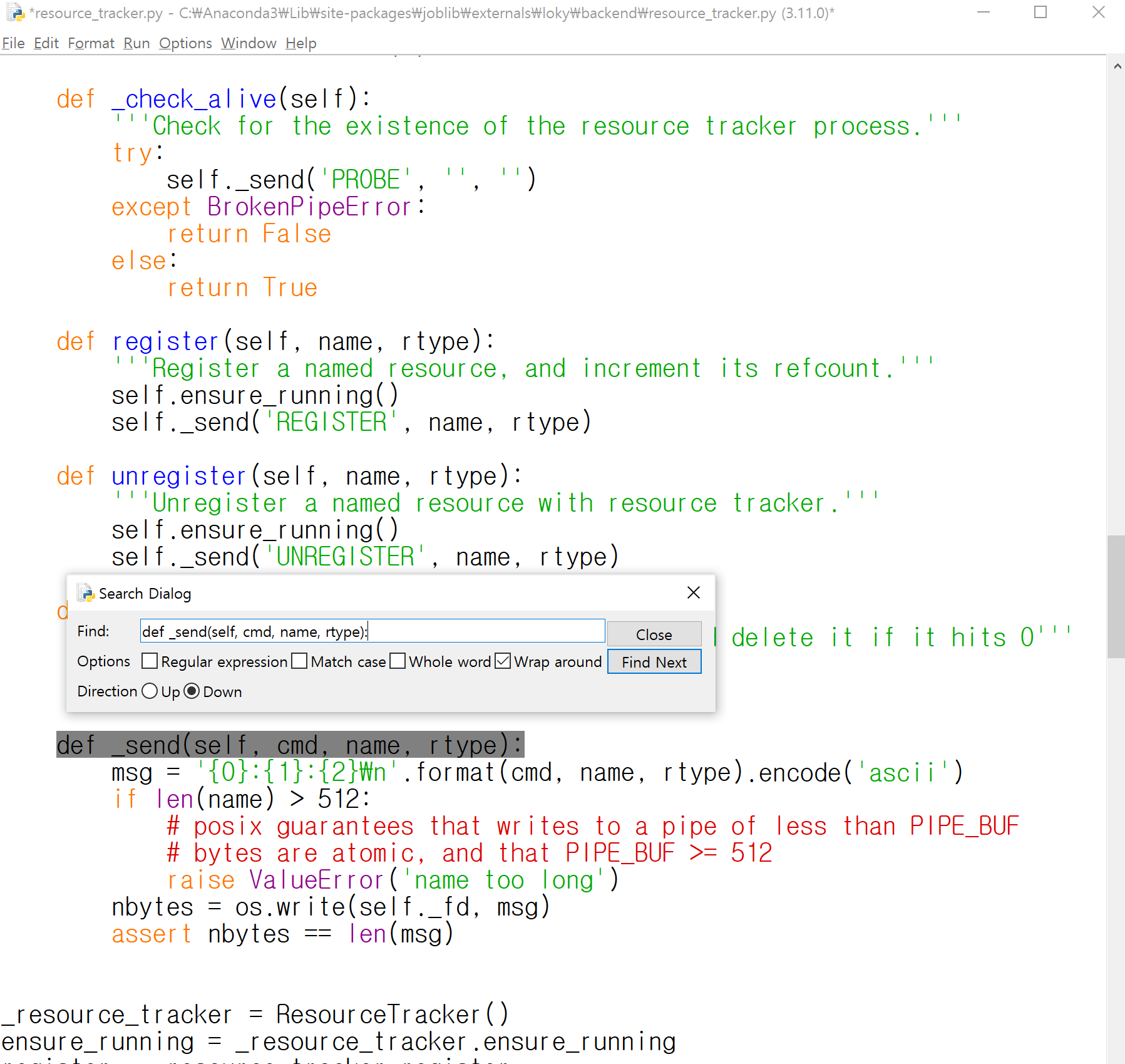
좋습니다.
여기서 바로 .encode('utf-8')로 바꿔줍시다.
msg = '{0}:{1}:{2}\n'.format(cmd, name, rtype).encode('utf-8')
그리고 저장

자 어떤가요?
저장이 잘 되면 끝입니다만, 필자는 안타깝게도 다시 오류창이 떴습니다.
이제부터 두번째 문제입니다. 아까 언급했었죠?
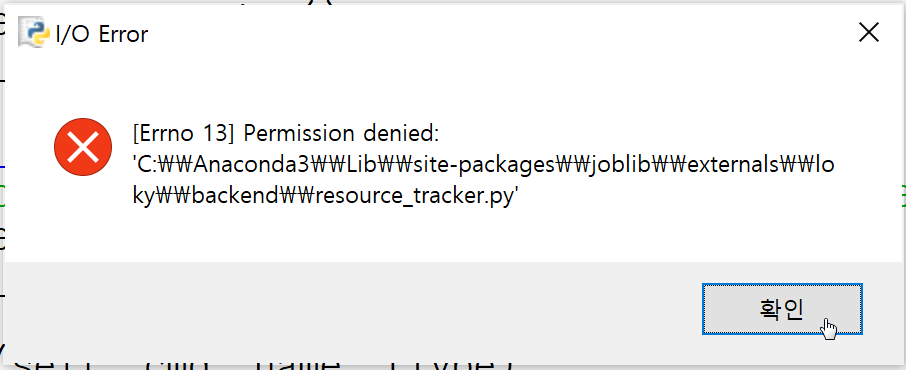
다시 찾아보니, 파일 경로가 잘못된 상태에서 수정하거나 수정 권한이 없을때,
혹은 \, ₩ 문자가 혼동이 되었을때 반출되는 에러 메시지라고 합니다.
직접 검색해보실 분들을 위해 텍스트도 추출했습니다.
[Errno 13] Permission denied: 'C:WWAnaconda3WWLibWWsite-packagesWWjoblibWWexternalsWWlo kyWWbackendWWresource_tracker.py'
좋습니다! 👼
권한이 없다면 권한을 만들어 줍시다!
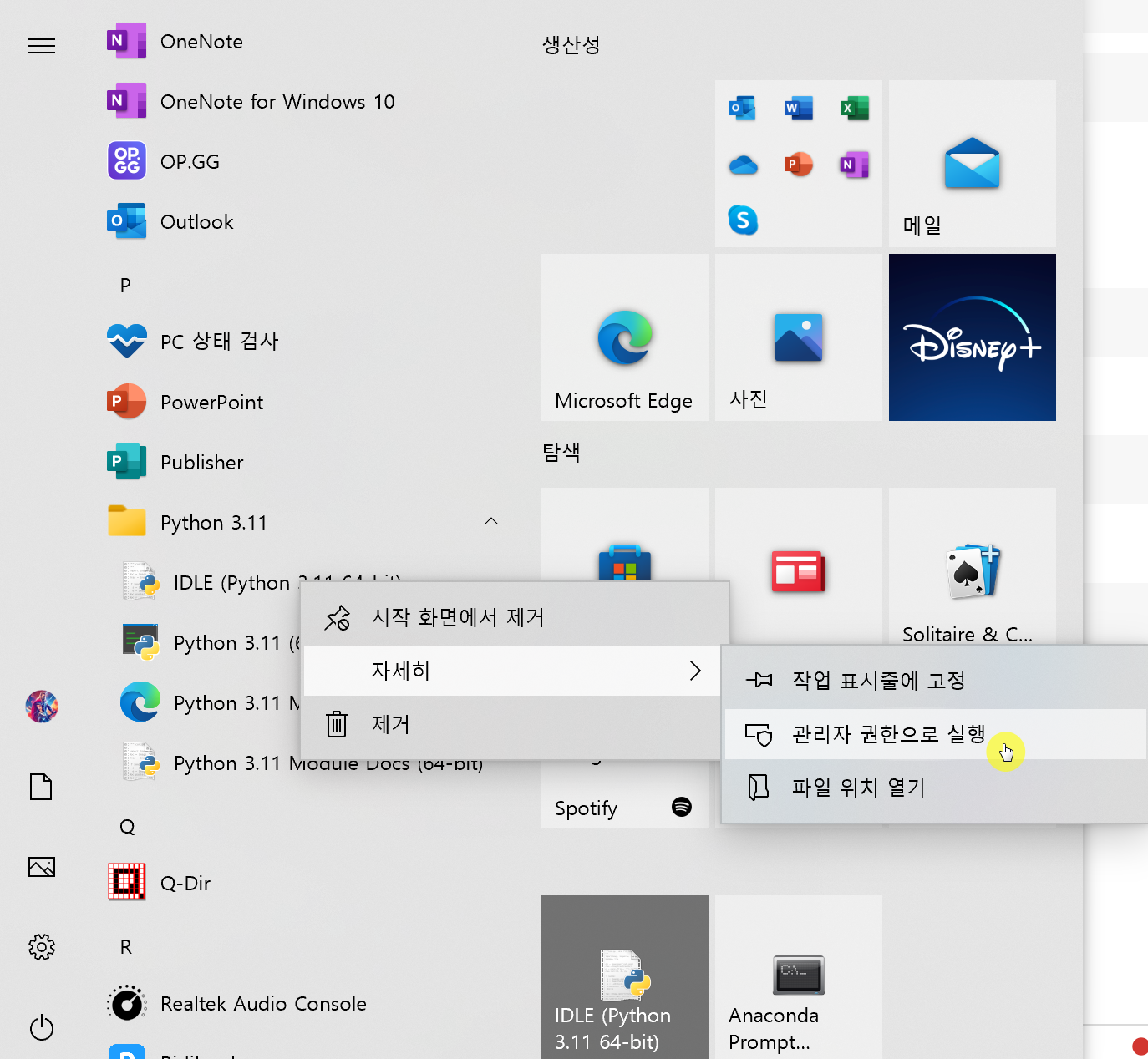
IDLE을 관리자 권한으로 실행시켜 줍니다.
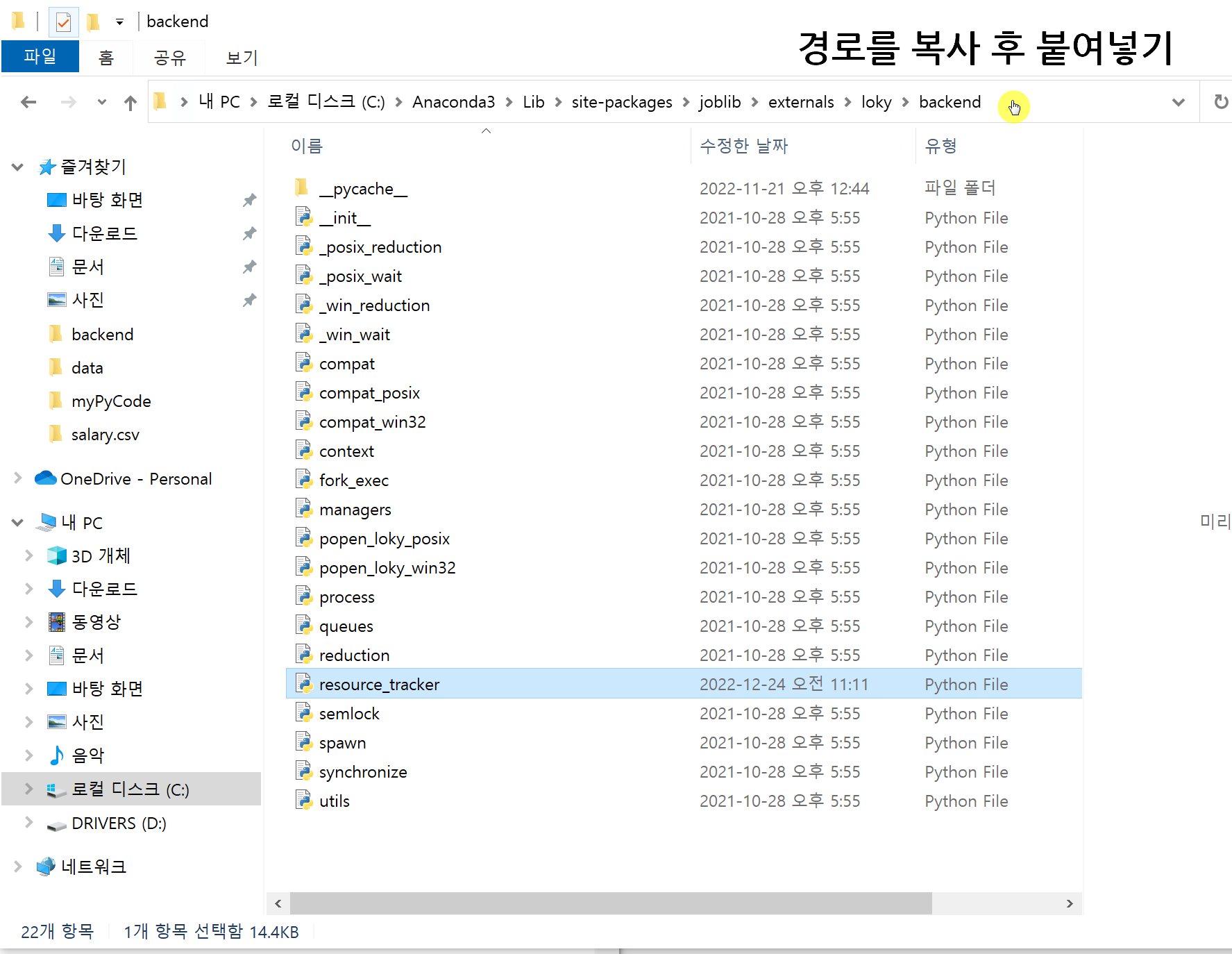
빨리 불러오기 위해서, 일단 해당 파일의 경로를 복사 했었습니다.
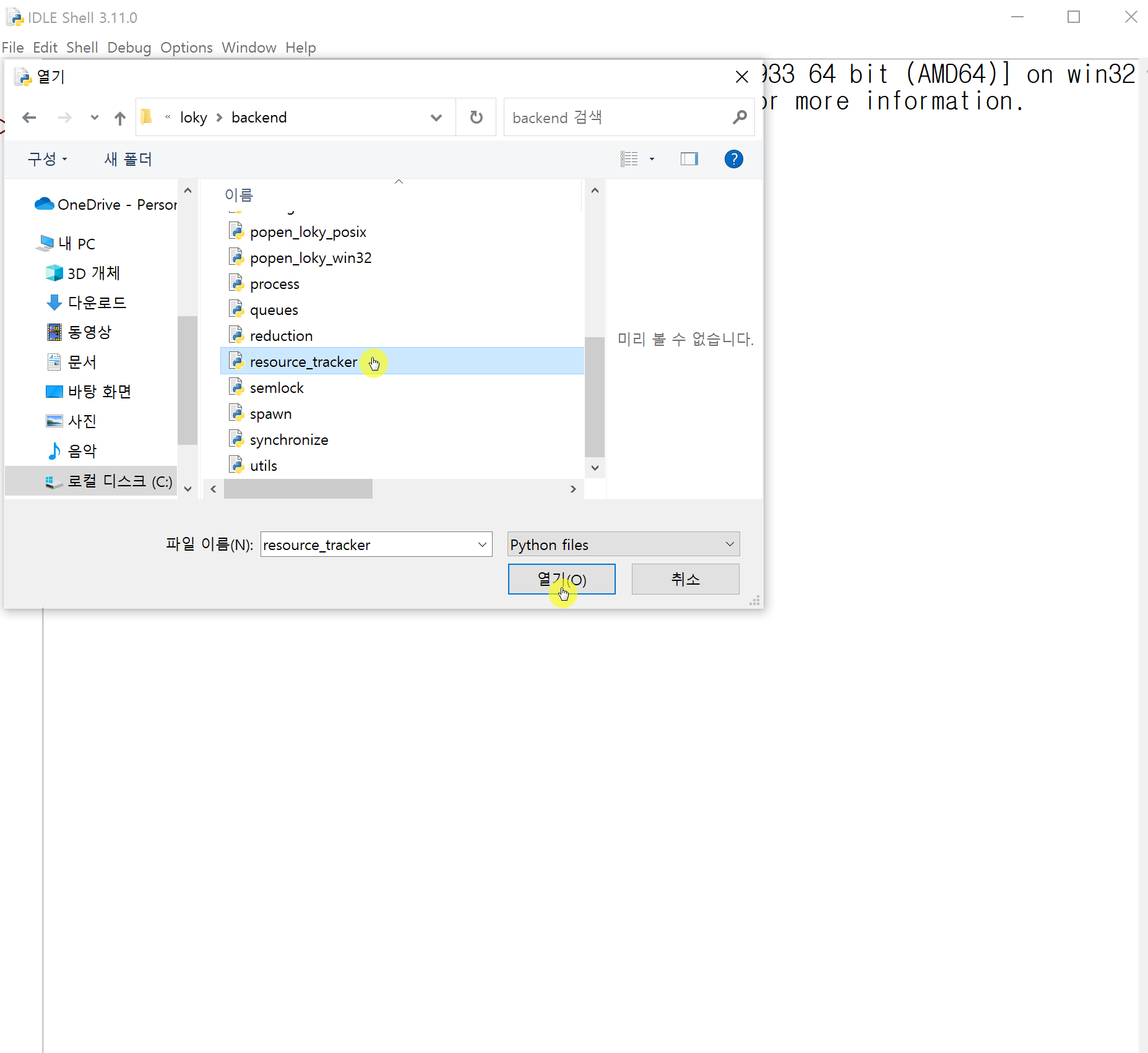
얼마 남지 않았습니다. 아까 실패했던 resource_tracker를 다시 열어줍니다.

아까 처럼 해당 문자열을 찾아서
def _send(self, cmd, name, rtype):
encode를 'utf-8'로 바꿔줍니다.
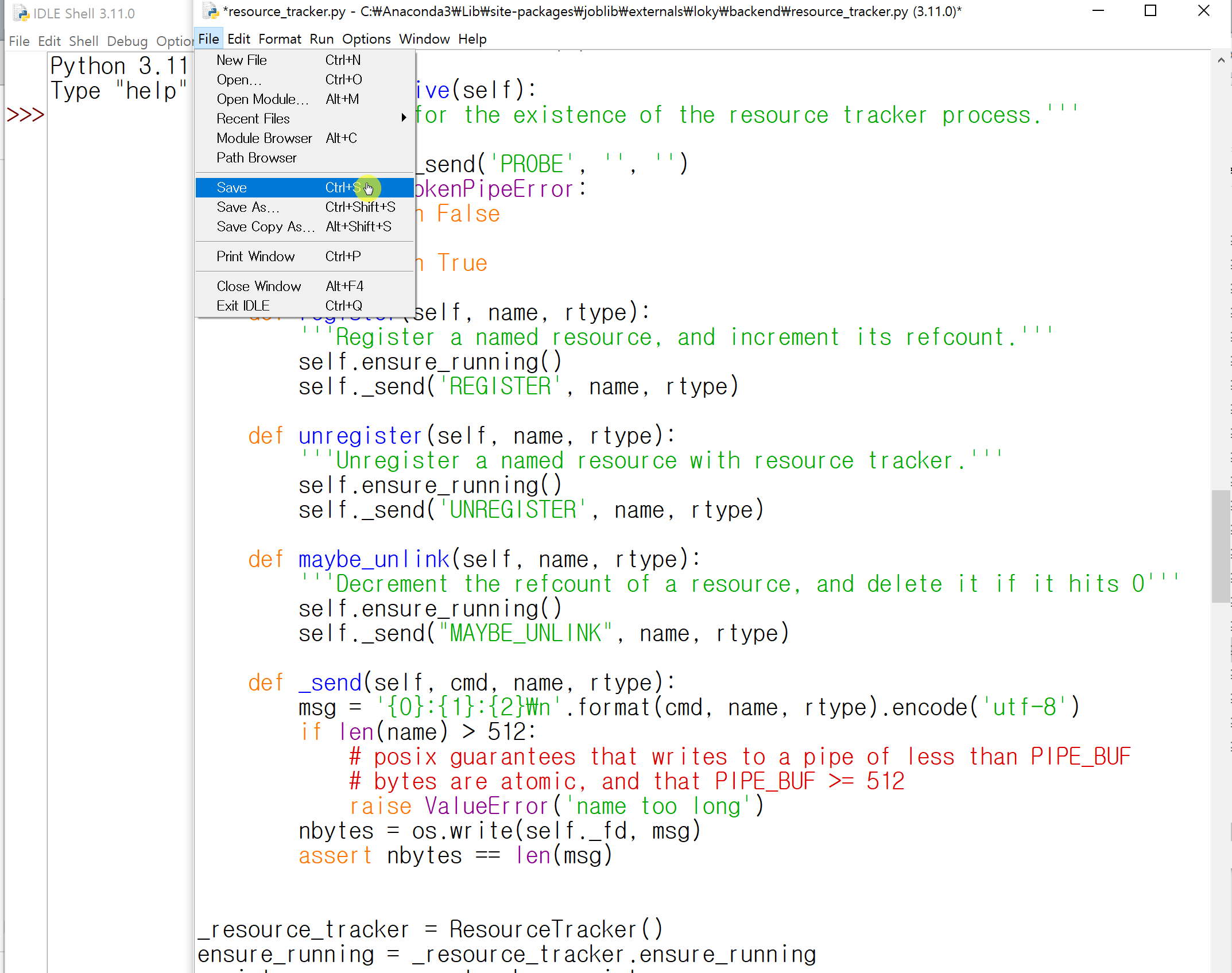
바로 저장해줍니다.
불안하신 분들은 Save As로 해서, 카피본을 만들어보셔도 됩니다.
이제 실행했던 jupyter 를 껐다가 다시 켜줍니다.
막혔던 GridSearchCV를 다시 모델링 시작해봅니다.
GridSearchCV(cv=3,
estimator=XGBClassifier(base_score=None, booster=None,
callbacks=None, colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None,
early_stopping_rounds=None,
enable_categorical=False, eval_metric=None,
feature_types=None, gamma=None,
gpu_id=None, grow_policy=None,
importance_type=None,
interaction_constraints=None,
learning_rate=None,...
max_cat_threshold=None,
max_cat_to_onehot=None,
max_delta_step=None, max_depth=None,
max_leaves=None, min_child_weight=None,
missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None,
num_parallel_tree=None, predictor=None,
random_state=None, ...),
n_jobs=-1,
param_grid={'learning_rate': [0.3], 'max_depth': [5],
'n_estimators': [200], 'subsample': [0.5]},
scoring='f1')좋습니다. 이렇게 해서 에러는 사라졌습니다.
2022_12_24
'오류로그' 카테고리의 다른 글
| [Error log] Google cloud code minikube를 VSC에서 사용할 때 Deploy 오류 (0) | 2023.07.11 |
|---|---|
| [flask/ github] flask 프로젝트 설치와 해결과정 (0) | 2023.04.18 |
| [django/docker 오류] error : subprocess-exited-with-error (0) | 2023.03.21 |
| [Amazon AWS EC2 & colab] EC2를 열고 jupyter 세팅 (0) | 2023.02.18 |
| 오류 로그 "REQUEST_DENIED (This API project is not authorized to use this API.)" (2) | 2022.12.10 |



