※ 본 글은 딥러닝 강의를 정리한 부분입니다.
DNN의 문제의식
DNN에서 우리는 Hidden Layer를 여러 개 만들어서 더 나은 학습을 시도했었습니다.
하지만 이는 자연계 이미지의 일반적인 특성을 잘 반영하진 못했습니다.
1. 인접 변수간의 높은 상관관계를 갖고 있음
- Spatially - local correlation을 고려해야 합니다.
예컨대 동물의 눈, 코, 입 등의 요소들은 가까운 pixel안에서는 유사한
rgb값을 갖고 있습니다.

다크아칸 군을 다시 데려왔습니다.
다크아칸의 얼굴을 계속 확대해보면 가까운 머리 이미지는
유사한 RGB값을 갖고있다는 점을 알 수 있습니다.
(실제 색상입니다)
* 그렇다면 공간적으로 인접한 곳에서 feature를 추측해 보는 것은 어떨까요?
이것이 인접 변수간의 높은 상관관계를 고려한 아이디어 입니다.

2. 이미지의 부분적 특성은 고정된 위치에 등장하지 않음
- Invariant feature(변하지 않는 속성)이 자연계에서 볼 수 있다는 정의.
동식물, 사물의 각 범주에는 부분적인 특성이 존재하는데, 이것은
항상 고정된 위치에만 등장하지 않습니다.
인간에게 있어서 네 개의 팔다리, 얼굴, 머리카락 등이 그렇습니다.
outlier 이외에는 모든 인간이 팔다리와 얼굴, 머리카락을 갖고 있습니다.
모든 인간이 동일한 위치에 팔다리, 얼굴, 머리카락을 지니고 있지는 않지요.

원본의 다크아칸 이미지와 좌우 반전을 진행한 다크아칸의 손 위치를 구한다고
생각해봅시다. 원본과 좌우반전한 이미지의 위치가 바뀔까요? 혹은 그대로 일까요?
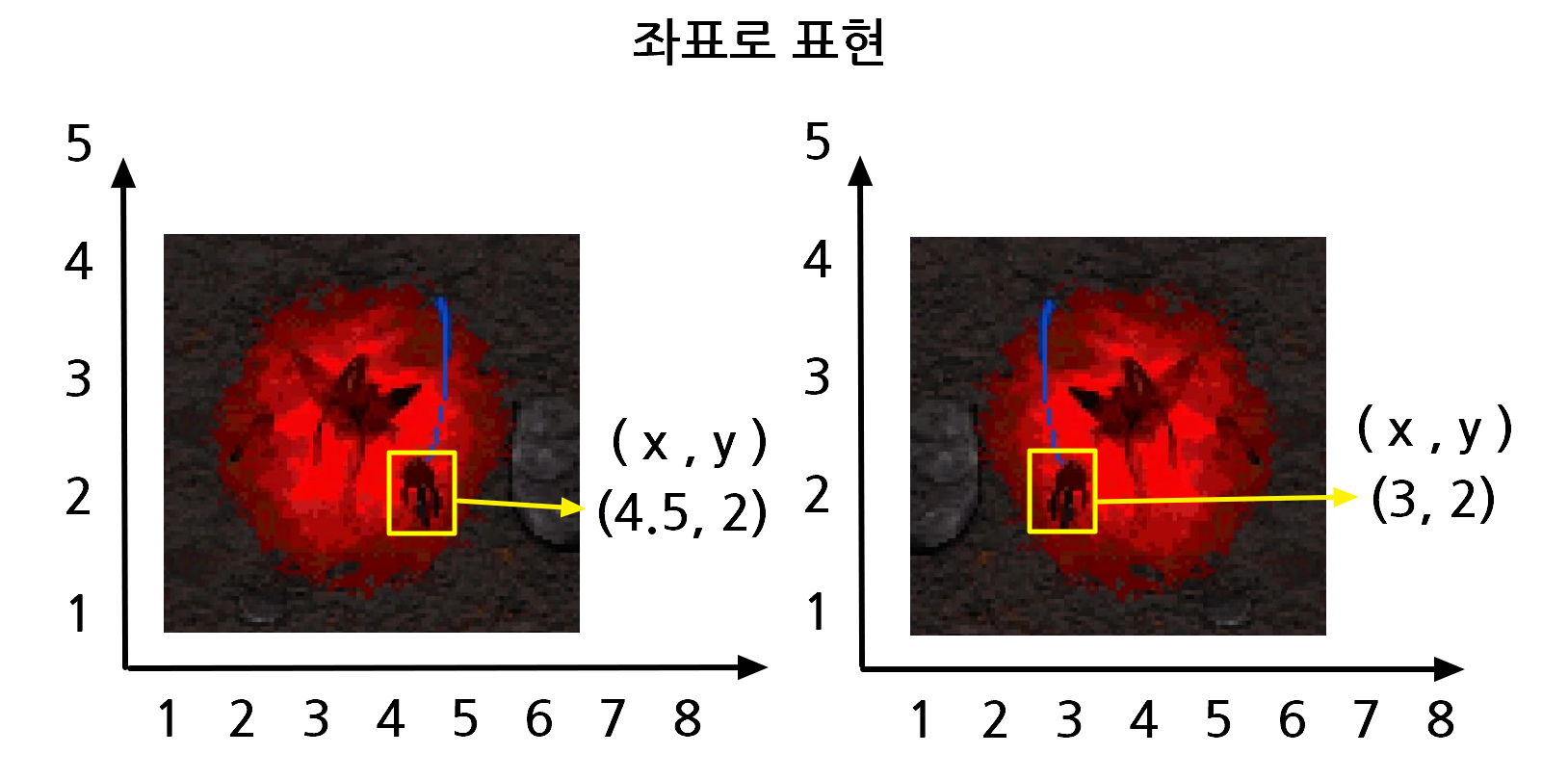
이미지에 따라 고정되있지 않고 이렇게 좌표값이 달라지게 됩니다.
즉, feature는 고정된 위치에 등장하질 않습니다.
그럼 부분적인 특성을 정해서 고정된 feature map을 사용하는 것은 어떨까요?
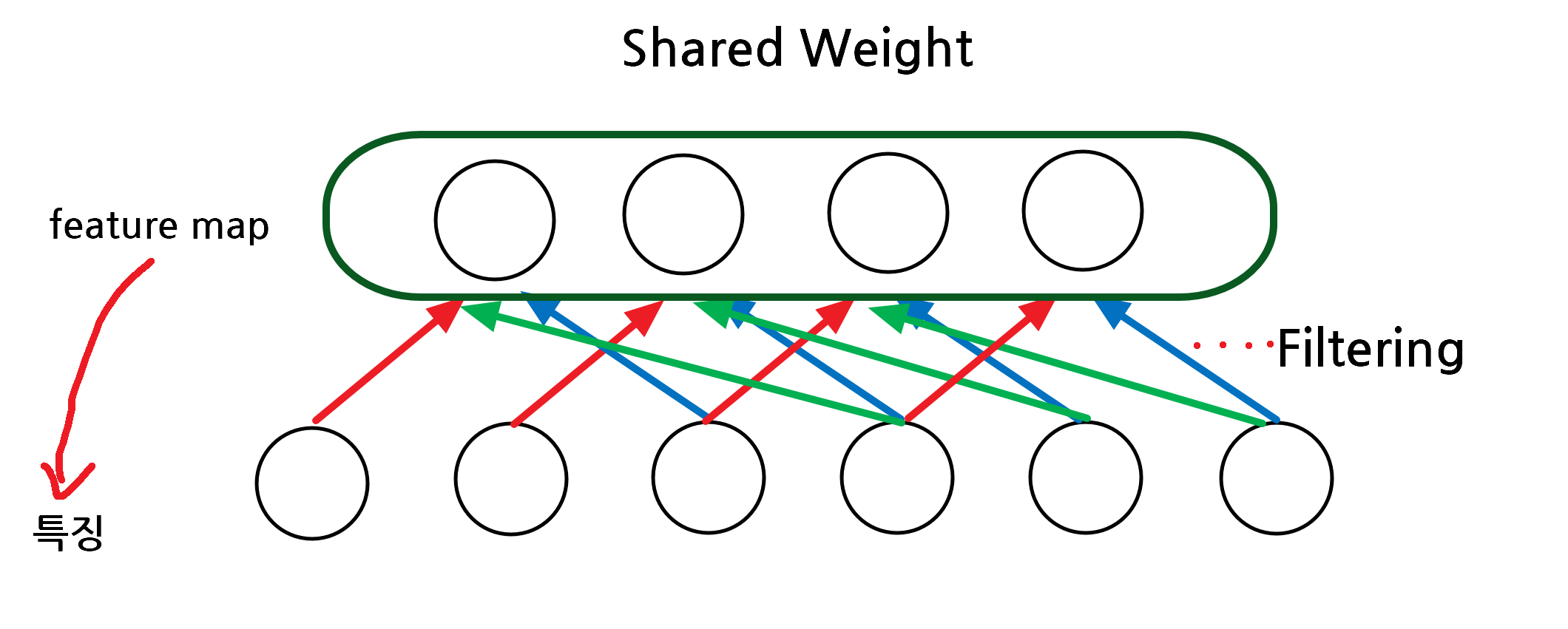
이것이 shared weight, 이미지의 부분적 특성을 고려한 대안입니다.
CNN 정의
Convolution을 사용해서 신경망을 학습시키는 형태가 곧 CNN입니다.
여기에는 Convolution 연산, Activation 연산, Pooling연산이 모두 반복되서 합쳐지고
이 필터를 적용하는 과정이 포함됩니다.
심지어 이 Filter도 머신이 알아서 학습하기도 합니다.
Convolution(합성공) 개념 자체는 혁펜하임님의 강의를 추천합니다.
정확하게 과정을 보여줍니다.
[딥러닝] 7-1강. 합성곱 신경망 (CNN: Convolutional Neural Network) | 뇌 벌려! CNN 들어간다! - YouTube
Fashion MNIST로 만들었던 사례




convolution neural network 모델 : 커널 크기는 5x5로 설정할 예정. convolution layer 는 2개로 사용할 예정임
- nn.Conv2d 모듈 : x입력을 받는 함수로 제작할 예정입니다.
- self.conv1, self.conv2는 CNN 모델 내부의 변수들은 함수로 취급할 것입니다.

위와 동일한 코드로 돌아가는 부분입니다.
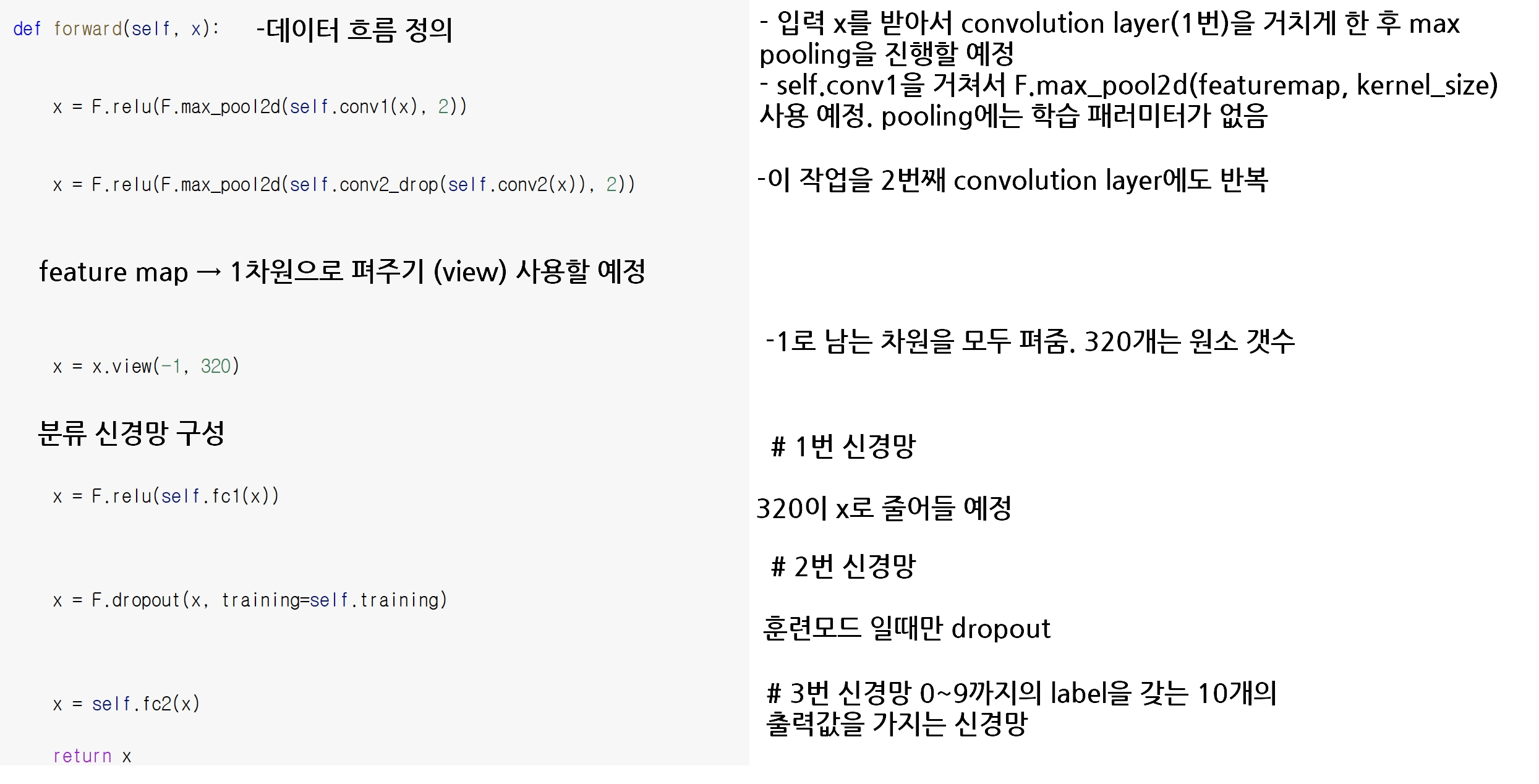

이제 정의했던 모델을 꺼내서 잠깐 확인해보겠습니다.

conv1 에서 입력채널 1, 출력채널 10, 커널 사이즈 5x5, stride 한 칸씩
두번째 층도 입력채널 10, 출력채널 20에 나머지는 동일
dropout을 한번 해주었구요.
첫번째 linear로 인풋되는 feature 크기 320, 아웃풋은 50 잘 되었습니다.
두번째 linear로 인풋되는 것은 첫번째 linear의 아웃풋 크기 50이 되고, 10이 아웃풋 됩니다.
torchsummary 기능으로 확인
from torchsummary import summary as summary_
summary_(model, (1,28,28), batch_size=64)----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [64, 10, 24, 24] 260
Conv2d-2 [64, 20, 8, 8] 5,020
Dropout2d-3 [64, 20, 8, 8] 0
Linear-4 [64, 50] 16,050
Linear-5 [64, 10] 510
================================================================
Total params: 21,840
Trainable params: 21,840
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 4.09
Params size (MB): 0.08
Estimated Total Size (MB): 4.37
train함수는 모델, train dataset, 최적화 함수, epoch를 받아서 epoch와 loss를
반환하는 함수로 이루어집니다.
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % 200 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
evaluate(평가용) 함수는 모델과 test dataset을 받아서 (기울기가 0인 상태로)
cross entropy를 사용해서 batch 오차를 합하고 예측값을 배출합니다.
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += F.cross_entropy(output, target,
reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuracy
결론적으로 epoch를 돌리겠습니다.
DNN으로 구현했던 모델을 Convolution neural network로 개선한 것입니다.
epoch는 40번으로 진행하면서, 모델, train dataset, 최적화 함수, epoch를 학습하고
evaluate 모드에서 모델의 loss, accuracy를 가져옵니다.
GPU성능에 따라 20~22분 정도가 소요됬습니다.
EPOCHS = 40
for epoch in range(1, EPOCHS+1):
train(model, train_loader, optimizer, epoch)
test_loss, test_accuracy = evaluate(model, test_loader)
print('[{}] Test Loss: {:.4f}, Accuracy: {:.2f}%'.format(
epoch, test_loss, test_accuracy))
22분 경과 후 EPOCH종료시 값
Train Epoch: 40 [0/60000 (0%)] Loss: 0.406845
Train Epoch: 40 [12800/60000 (21%)] Loss: 0.345638
Train Epoch: 40 [25600/60000 (43%)] Loss: 0.379269
Train Epoch: 40 [38400/60000 (64%)] Loss: 0.444115
Train Epoch: 40 [51200/60000 (85%)] Loss: 0.558653
[40] Test Loss: 0.3145, Accuracy: 88.68%
'필기정리' 카테고리의 다른 글
| [Web crawling] 구글에서 자동으로 원하는 이미지 다운받기 (0) | 2023.02.17 |
|---|---|
| [DeepLearning] DNN(Deep Neural Net) 강의 필기 (0) | 2023.01.12 |
| [DeepLearning] NN(Neural Net) 강의 필기 (0) | 2023.01.09 |


