서론

무한한 것과 랜덤한 것은 많은 의미를 갖고 있습니다
무한을 품고 있는 것은 어떤 것들이 있을까요?
무한히 늘어나는 우주와 별, 항성들도 있구요.
무한히 멀어지는 은하와 은하 사이의 거리, 우주의 시작점에서부터
멀어지는 시간들도 있습니다.
무한히 빵을 먹어도 줄지 않는 제 식욕도 있을 겁니다.
무작위성을 품고 있는 것들은 어떤 것이 있을까요?
무작위로 쏟아지는 카지노 칩과 카드게임의 결과,
바둑에서의 수만가지 경우의 수들도 있습니다.
비가 오면 사방으로 떨어지는 물방을이 내 옷에 튀는 위치,
번개가 떨어지는 지면의 위치, 로또 복권의 당첨자 등
랜덤한 것들은 일상에서도 쉽게 찾아볼 수 있습니다.
무한히 커지는 것과 랜덤한 것의 공통점이 있다면
그것이 인간의 상상력을 자극하고, 계속 도전하게 만든다는
점이 있답니다.
무한한 우주로 인간은 나가고 싶어하고
무작위의 카지노 판에서 인간은 도파민을 뿜으며 도전합니다.
그러한 것들에는 어떤 참을 수 없는 매력이 있는 것일지도 모르겠습니다.
이번시간에는 무한한 것 즉 inf와 무작위를 가진 empty가 등장하기에
잠깐 소개해봤습니다.
그 외에도 다양한 배열의 변형을 확인하게 됫리겁니다.
배열의 생성과 변형
numpy의 배열 즉, ndarray의 클래스는 값들이 모두 같은
자료형이어야 합니다.
np.array로 배열을 만들 때 자료형을 설정하지 않으면 컴퓨터는
자료형을 자동으로 지정하구요. 명시적으로 적용하고 싶을 때는
dtype 속성을 사용합니다.
만들어진 배열의 자료형을 알고 싶으면 dtype
항상 시작할때는 설치부터 시작합니다.
import numpy as np
x라는 배열을 생성합니다.
x = np.array([1,2,3])
x
일단 int라고 추측해볼까요?
x.dtypedtype('int64')
x = np.array([1.0,2.0,3.0])
x.dtypedtype('float64')
float는 소숫점이 포함되는 숫자의 경우입니다.
정수 (int) < 실수(float) < ... < object...이러한 순서 입니다.
dtype으로 자료형 지정
x = np.array([1,2,3,4], dtype = 'f')
x.dtypedtype('float32')
아래는 dtype을 통해 볼 수 있는 다양한 인수들입니다.
dtype 접두사로 시작하는 문자열로, 그 뒤에 오는 숫자는
byte 수 혹은 글자 수 입니다.
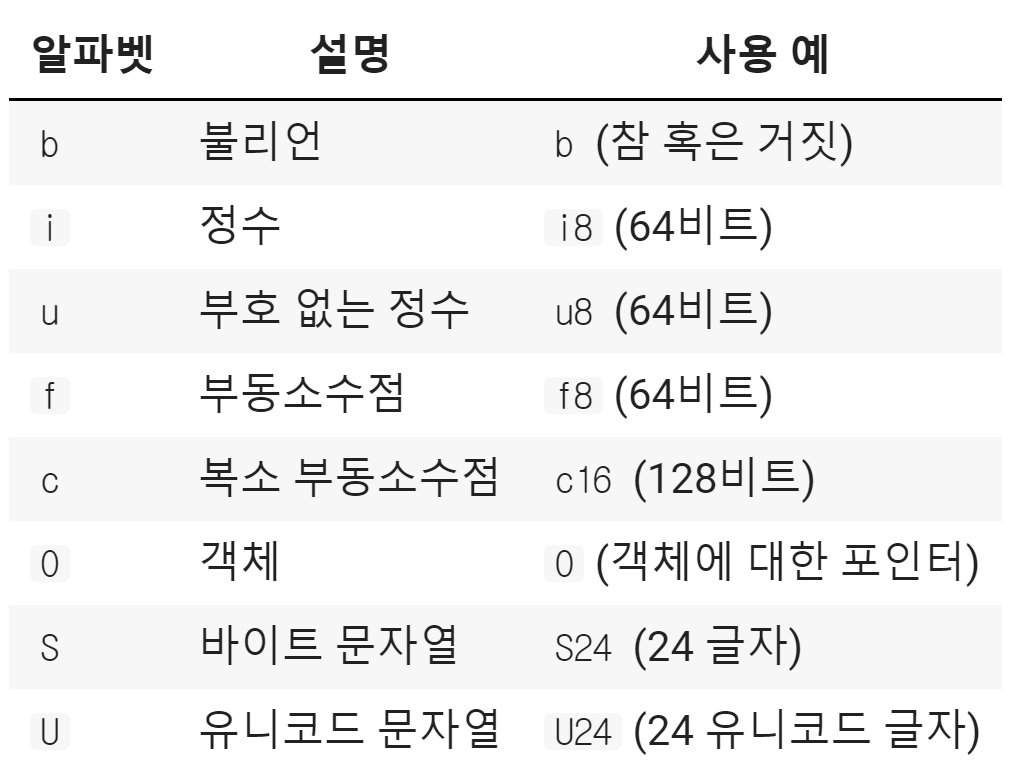
숫자 생략 시 운영체제에 따라 알맞은 크기를 지정합니다.
x = np.array([1,2,3], dtype ='f')
x.dtypedtype('float32')
부호 없는 정수의 경우
x = np.array([1,2,3], dtype ='U')
x.dtypedtype('<U1')
이렇게 까지 표현됩니다.
자 이번에는 inf와 NaN에 대해서 분석해보겠습니다.
inf 와 NaN
앞서 말한 무한한 우주처럼,
numpy에서는 무한대를 표현하기 위한 np.inf라는 값이 있습니다.
infinity ; (미, 영) 무한성, 아득히 먼곳
반대로 정의할 수 없는 숫자도 있습니다.
np.nan(NaN)이라는 값입니다.
not a noumber ; 결측치
우리가 중간고사를 봤다고 생각해볼까요?
중간고사 성적을 정리한 데이터가 있는 경우,
시험을 안본 것도 아니고, 시험을 마킹하긴 했는데 도저히 확인할 수 없는
그러한 경우, 무응답의 경우를 결측치 라고 합니다.
np.array([0, 1, -1, 0]) / np.array([1,0,0,0])
대표적으로는 0 나누기 1과 0 나누기 0이 있습니다.
위와 같이 실행하면 divide by zero encountered가 포함된 오류문구와
함께, inf와 nan이 뜨게 되는데요.
<ipython-input-9-51805f2f4ef0>:1: RuntimeWarning: divide by zero encountered in true_divide
np.array([0, 1, -1, 0]) / np.array([1,0,0,0])
<ipython-input-9-51805f2f4ef0>:1: RuntimeWarning: invalid value encountered in true_divide
np.array([0, 1, -1, 0]) / np.array([1,0,0,0])
array([ 0., inf, -inf, nan])0 나누기 1은 근본적으로 무한한 값이 뜨게 되고,
0 나누기 0은 계산할 수 없습니다.
궁금하신 분들은 지금 바로 네이버 계산기를 켜고
0 / 0 을 계산해보는 것도 추천합니다.
아마 한번도 본적 없는 계산기의 반응이 나올 텐데요?
아무튼 Nan은 추후 pandas에서도 자주 반환되는 값이기에
기억해두면 좋겠습니다.
수학적 개념에서는 log 0 이라는 숫자도 무한대를 띕니다.
np.log(0)<ipython-input-23-f6e7c0610b57>:1: RuntimeWarning: divide by zero encountered in log
np.log(0)
-inf
이 부분도 inf가 뜨게 됩니다.
이제는 배열을 쉽게 생성해 보겠습니다!
배열 생성
먼저 오직 테스트만을 위해 임시로 값을 설정하는
방법을 알아봅니다.
np.zeros( n )
크기가 정해져 있고, 모든 값이 0인 배열을 생성합니다.
갯수는 n개 만큼 생성합니다.
a = np.zeros(5)
aarray([0., 0., 0., 0., 0.])
쉽죠? 2차원 배열도 가능합니다.
튜플로 (행, 열)을 넣어주세요.
# 튜플을 넣으면 해당 크기의 0으로 채워진 다차원 배열을 생성합니다
b = np.zeros((2,3))
barray([[0., 0., 0.],
[0., 0., 0.]])
c = np.zeros((5,2),dtype= 'i')
carray([[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0]], dtype=int32)
d = np.zeros(5, dtype='U4')
darray(['', '', '', '', ''], dtype='<U4')
d[0] = 'abc'
d[1] = 'abcd'
d[2] = 'abcde' # 크기가 U4라서 한글자 잘림
darray(['abc', 'abcd', 'abcd', '', ''], dtype='<U4')
앞에서부터 abc, abcd, abcde가 입력된 것을 볼 수 있죠?
3차원 배열
b = np.zeros((2,3,5))
barray([[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]]])모두 가능하네요.
ones(n)
1로 초기화된 배열을 생성합니다.
np.ones(4)array([1., 1., 1., 1.])
2차원 배열
e = np.ones((2,3),dtype ='i8')
earray([[1, 1, 1],
[1, 1, 1]])
zeros와 구문은 유사합니다.
3차원 배열입니다.
e = np.ones((3,2,2),dtype ='i8')
earray([[[1, 1],
[1, 1]],
[[1, 1],
[1, 1]],
[[1, 1],
[1, 1]]])
np.empty(n)
완전히 랜덤한 수로 뽑아내는 배열입니다.
시간도 절약하고 메모리를 절약할 수 있도록
초기화를 하지 않고 뽑아냅니다.
즉, 식당에 가서 자리만 잡고, 테이블은 치우지 않은
상태라고 볼 수 있습니다.
g = np.empty((4, 3))
garray([[1.2515592e-316, 0.0000000e+000, 0.0000000e+000],
[0.0000000e+000, 0.0000000e+000, 0.0000000e+000],
[0.0000000e+000, 0.0000000e+000, 0.0000000e+000],
[0.0000000e+000, 0.0000000e+000, 0.0000000e+000]])
차원 수와 타입도 확인해볼까요?
g.shape, g.dtype((4, 3), dtype('float64'))
4행 3열, 타입은 실수형을 가진것을 알 수 있습니다.
좋습니다!
np.arrange (n)
필자가 개인적으로 자주 쓰는 함수입니다.
아주 빠르게 숫자가 하나씩 상승하는 배열을 만들어줍니다.
np.arange(10)array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arange(시작점, 끝점, 스텝단계) 입니다.
다시 볼까요?
np.arange(3,21,2)array([ 3, 5, 7, 9, 11, 13, 15, 17, 19])
np.linspace
lin(linear)가 포함. 선형구간을 지정한 구간의 수만큼
분할합니다.
linspace(시작, 끝, 구간수)
np.linspace(0,100,5)array([ 0., 25., 50., 75., 100.])
np.logspace(log)
logspace는 로그 구간을 지정한 구간의 수만큼
분할합니다.
np.logspace(0.1, 1, 10)array([ 1.25892541, 1.58489319, 1.99526231, 2.51188643, 3.16227766,
3.98107171, 5.01187234, 6.30957344, 7.94328235, 10. ])
전치 연산 (transpose)
전치, 흔히 보던 용어는 아닌데요?
오히려 영어로 번역하면 익숙해집니다.

뒤바꾸는 것이죠.
전치연산은 2차원 배열의 행과 열을 뒤바꿉니다.
구조
Array.T
A = np.array([[1,2,3],[4,5,6]])
2 X 3의 행렬을 만들었습니다.
A, A.shape(array([[1, 2, 3],
[4, 5, 6]]), (2, 3))
이를 transpose 해줍니다.
A.Tarray([[1, 4],
[2, 5],
[3, 6]])
전치는 이렇게 해서 완료되었습니다.
특별히 어려울 것은 없습니다.
배열의 크기 변형
크기 변형은 "reshape"로 다차원 배열간의 차원을
변경할 때 사용합니다.
a = np.arange(12)
aarray([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
a르 만들었습니다.
현재 12개인 배열을 3행 4열짜리 2차원 배열로 바꿀 수 있습니다.
b = a.reshape(3,4)
barray([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
자, -1열을 설정해서 만드는 것도 가능합니다.
b = a.reshape(3,-1)
barray([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
3차원 배열로도 가능할까요?
c = a.reshape(2,3,2)
carray([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]]])
가능합니다.
배열 평탄화
평탄화 (flatten, ravel)
2차원, 3차원 배열을 1차원으로 변환하는 것입니다.
아까 전의 b 배열을 한번 봐볼까요?
barray([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
이를 1차원으로 압축합니다.
flatten( ) 을 사용합니다.
b.flatten()array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
평탄화하는 방법은 flatten과 ravel 두 가지가 있습니다.
flatten과 ravel이 갖는 차이는 원본 배열에 수정이 가해진다는 점 입니다.
flatten은 원본에 수정이 가해지진 않습니다. 원본을 copy 하기 때문이죠!
단, 더 많은 메모리를 필요로 하기 때문에, 시간이 ravel보다 더 걸릴 수 있습니다.
ravel은 딱히 copy를 하지 않기 때문에 원본에 수정이 가해집니다.
d = b.ravel()
darray([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
이러한 차이점을 잘 인지하고 쓰는 것이 좋겠습니다.
반대로 다시 차원을 증가시키는 것도 가능합니다.
한 차원 증가
newaxis ( ) 함수를 사용합니다.
axis는 배열에서의 축 이라고 언급했죠? 축을 잡아서 늘리면
차원이 늘어나는 것입니다.
배열을 봐보겠습니다.
x = np.arange(5)
xarray([0, 1, 2, 3, 4])
같은 배열에 대해 차원만 1차원 증가합니다.
x[:,np.newaxis]array([[0],
[1],
[2],
[3],
[4]])
4행 1열짜리 배열이 되었습니다.
이렇게하여, 배열의 여러가지 형태로 생성하고 변형하며,
전치하는 방법을 알아 보았습니다😁
다음 시간에는 배열의 연결과 몇가지 인덱서, 배열 분할을
알아보겠습니다!💥
'Programming Language > Python_library' 카테고리의 다른 글
| 파이썬_응용단계 ep.6 배열의 연산 (0) | 2022.12.11 |
|---|---|
| 파이썬_응용단계 ep.5 배열의 연결과 분할 (2) | 2022.12.09 |
| 파이썬_응용단계 ep.3 배열 깎는 조각가 (0) | 2022.12.08 |
| 파이썬_응용단계 ep.2 Numpy 튜토리얼 (2) | 2022.12.07 |
| 파이썬_응용단계 ep1. Numpy와 함께 딥러닝의 세계로 (0) | 2022.12.06 |



