서론


pandas는 왜 쓰일까요?
numpy와 pandas를 배운 순간 실질적으로 데이터 분석 작업에
한 걸음 가까워지게 됩니다.
마치 판다들이 대나무를 이용하는 것처럼 자유롭게 사용하는 것이 중요합니다.
자, numpy는 여러분이 다차원 배열 데이터를 다루는 라이브러리로
각종 행렬과 계산에 특성화했었죠? 이는 수학, 분석, 모델링 등에서
다양하게 활용됩니다.
우리가 다르는 데이터는 시계열(Series)와 표(Table)가 대부분으로,
pandas에서는 이 series와 행, 인덱스, 열로 구분되어 있는
DataFrame을 다룹니다.
실제로 데이터를 다룬다는 느낌이 강할 것입니다.
준비
기본적으로 jupyter notebook을 쓰시는 경우 아래 명령어로
설치합니다.
pip install pandas
그리고 나서 임포트 해주면 이제 pandas를 쓸수 있게 됩니다.
import pandas as pd
축약어로는 pd를 사용합니다.
import numpy as np
numpy도 함께 사용되는 경우가 있으므로, 같이 불러와주세요.
구글 colab을 쓰시는 경우, import pandas as pd 만 실행시켜도
자동으로 됩니다.
표와 그래프를 위한 첫 단추
시리즈(Series)와 데이터프레임(Dataframe)을
알아봅니다🐬
1. 시리즈 (Series)
시리즈는 일종의 값과 인덱스 모음입니다.
이전의 numpy에서 제공한 1차원 배열과도 유사합니다.
1차원 배열이 type과 length가 고정된 리스트로, 정수 인덱스를 가진다면
series는 일종의 딕셔너리에 가깝습니다.
+정수 인덱스와 label을 가집니다.
Series = 값(value) + 인덱스(index)
이번 시간에는 생성에만 중점을 두고, 다음 게시물부터
본격적으로 다뤄보겠습니다.
2. 생성
여러분이 데이터를 list 또는 1차원 배열 형식으로 Series 클래스 생성자에
넣어주면 시리즈 객체를 생성할 수 있습니다.
이때, 인덱스를 넣으면 길이는 데이터의 길이와 일치해야 합니다.
눈으로 보겠습니다.
s = pd.Series([9904312, 3448737, 2890451, 2466052],
index=["서울", "부산", "인천", "대구"])
s서울 9904312
부산 3448737
인천 2890451
대구 2466052
dtype: int64
좋습니다. 타입은 int 64비트로 나왔죠?
각 줄을 보겠습니다.
s = pd.Series([9904312, 3448737, 2890451, 2466052], # 연속된 데이터 묶음 (리스트, 튜플, 1차원 배열...)
index=["서울", "부산", "인천", "대구"]) # 넣어준 데이터의 길이와 일치하는 인덱스 묶음을 넣으면
# 순서대로 짝지어서 데이터가 들어갑니다
# 인덱스를 안 넣어주면 range 비슷하게 생성 (길이가 맞춰서)
s
인덱스의 값을 라벨이라고 합니다. 라벨은 또한 정수, 문자열, 날짜, 시간도
가능합니다!
s.index, type(s.index)(Index(['서울', '부산', '인천', '대구'], dtype='object'),
pandas.core.indexes.base.Index)
시리즈의 인덱스는 .index 속성으로 접근할 수 있습니다.
s.values, type(s.values)(array([9904312, 3448737, 2890451, 2466052]), numpy.ndarray)
시리즈의 값들은 .values 속성으로 접근할 수 있습니다.
데이터의 이름과 인덱스의 이름을 붙여볼께요.
s.name = "인구"
s.index.name = "도시"
s도시
서울 9904312
부산 3448737
인천 2890451
대구 2466052
Name: 인구, dtype: int64
s.index.name으로 이름도 확인하겠습니다.
s.index.name'도시'
인덱스 부분도 제가 설정한대로 붙여졌습니다.
🏙
다음으로 시리즈의 진화된 형태인 데이터프레임이 있습니다.
2. 데이터프레임(DataFrame)
시리즈가 행방향 인덱스와 1차원 배열 데이터의 결합이었다면
데이터프레임은 2차원 배열 데이터와 행방향 인덱스 + 열방향 인덱스의 결합이라고
할 수 있습니다. 이때 배열 데이터는 딕셔너리 형태로 지정할 수 있습니다.
데이터를 생성해볼까요?
생성
DataFrame
데이터프레임 부터는 표를 코드상으로 표현할 수 없어
이미지로 바로 표현하겠습니다.
data = {
"2015": [9904312, 3448737, 2890451, 2466052],
"2010": [9631482, 3393191, 2632035, 2431774],
"2005": [9762546, 3512547, 2517680, 2456016],
"2000": [9853972, 3655437, 2466338, 2473990],
"지역": ["수도권", "경상권", "수도권", "경상권"],
"2010-2015 증가율": [0.0283, 0.0163, 0.0982, 0.0141]
}
columns = ["지역", "2015", "2010", "2005", "2000", "2010-2015 증가율"]
index = ["서울", "부산", "인천", "대구"]
df = pd.DataFrame(data, index=index, columns=columns)
df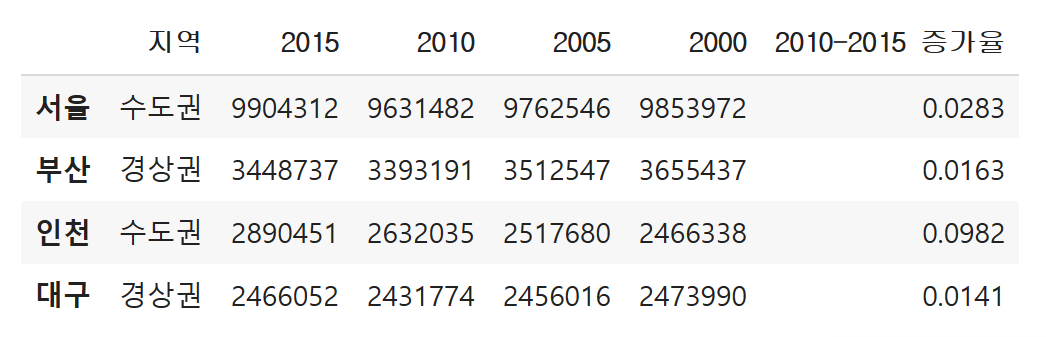
실제 데이터는 아니고, 임의입니다.
먼저, 하나의 열이 되는 데이터를 리스트로 준비합니다.
그리고 이 각각의 열에 대한 이름(라벨)을 키로 가지는 딕셔너리를
만들어줍니다.
다음, 이 데이터를 pd.DataFrame 생성자에 넣습니다.
동시에 열 방향 인덱스는 columns라는 인수로, 행 방향 인덱스는
index라는 인수로 지정합니다.
특징
실제로 데이터는 이미 있는 csv파일이나 xlsx 파일을 불러오고,
직접 작성하는 경우는 거의 없습니다. 때문에 추후에 불러오기 방법을
확인하겠습니다.
DataFrame은 2차원 배열과 유사합니다만, 공통 인덱스(행)을 가지는
columns을 딕셔너리로 묶어놓은 것 뿐입니다.
🚩다만 각 열마다 자료형이 다를 수는 있습니다.
증명
df.지역.dtype, df['2015'].dtype, df['2010-2015 증가율'].dtype(dtype('O'), dtype('int64'), dtype('float64'))
각 columns (지역, 2015, 2010-2015 증가율)은 텍스트, int, float로
다 다릅니다.
다른 속성들을 보겠습니다.
df.valuesarray([['수도권', 9904312, 9631482, 9762546, 9853972, 0.0283],
['경상권', 3448737, 3393191, 3512547, 3655437, 0.0163],
['수도권', 2890451, 2632035, 2517680, 2466338, 0.0982],
['경상권', 2466052, 2431774, 2456016, 2473990, 0.0141]], dtype=object)
df.values는 제작의 반대로 데이터만 접근하고 싶을 때 사용합니다.
df.columnsIndex(['지역', '2015', '2010', '2005', '2000', '2010-2015 증가율'], dtype='object')
df.columns는 열 방향 인덱스를 확인할 때 사용합니다.
df.indexIndex(['서울', '부산', '인천', '대구'], dtype='object')
특별한 점은 없습니다.
df.index는 행 방향 인덱스를 확인할 때 사용합니다.
시리즈처럼 열 방향 인덱스, 행 방향 인덱스에 이름도
지정할 수 있죠
df.index.name = '도시'
df.columns.name = '특성'df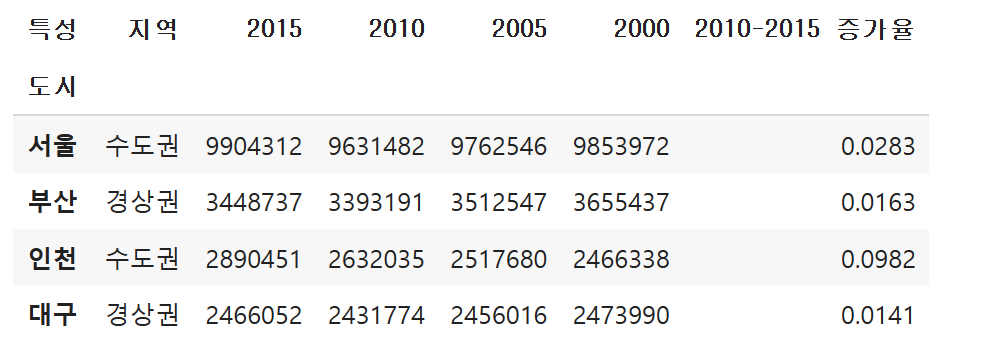
좋습니다.
일단 생소한 기능들을 처음 선보이기 때문에
series와 dataframe의 간단한 생성으로 시작해보았습니다.
아직 갈 길은 많이 남았습니다!
다음부터는 갱신과 수정, 인덱싱과 슬라이싱을 확인하도록
하겠습니다. 🛴🛴🛴
'Programming Language > Python_library' 카테고리의 다른 글
| 2KHz의 sin파 PyQt5로 구현 (0) | 2023.09.17 |
|---|---|
| 파이썬_활용단계 ep.2 pandas를 써서 표 안의 원하는 것만 골라뽑기 (0) | 2022.12.18 |
| 파이썬_응용단계 ep.8 난수와 샘플링, 데이터 카운팅! (2) | 2022.12.13 |
| 파이썬_응용단계 ep.7 정렬과 통계 (0) | 2022.12.11 |
| 파이썬_응용단계 ep.6 배열의 연산 (0) | 2022.12.11 |



