
서론
지난 글에서 필자가 KNN 알고리즘의 낮은 점수(accuracy_score)로 인해
문제점이 있다고 밝힌 바 있습니다. 스케일링에 대한 부분이 비어있었기 때문인데요.
이번 게시글에서는 Standard Scaler 대신 MinMax Scaler(최소-최대 스케일링)을 통해서
낮은 점수를 해결하도록 노력하겠습니다!💪
지난 시간 링크 : https://astart.tistory.com/34
[Machine Learning] KNN 알고리즘 실습사례_wine 분류
KNN Algorithm 간단하게 시작하자면 K개의 이웃(Neighbors)한 점들을 인접한(Nearest) 영역에서 포집시키는 방법입니다. KNN 알고리즘은 비교적 합리적이고 유용한 방식은 아니지만, 빠르고 쉬우며 분류나
astart.tistory.com
잠깐 설명하자면, 최소-최대 스케일링은 min(x), max(x)를 사용해서,
데이터프레임의 모든 column에서 최댓값이 1, 최솟값이 0인 형태로 변환합니다.

표준화 스케일링, 로버스트 스케일링과 비교했을 때,
데이터의 기존 분포를 가장 있는 그대로 담아내고, 스케일만 변화시킵니다.
항상 유용한 것은 아니니, 특성에 따라 잘맞는 스케일러를 자율적으로 선택해야겠습니다.
자세한 설명은 아래 문서에 설명되어 있습니다.
물론, 손으로 직접 하진 않고, 사이킷런 라이브러리에 내장되어 있는
패키지를 사용합니다.
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html
sklearn.preprocessing.MinMaxScaler
Examples using sklearn.preprocessing.MinMaxScaler: Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.24 Image denoising using kernel PCA Image denoising using kernel PC...
scikit-learn.org
지난 번과 동일한 데이터를 잠깐 확인해보겠습니다.

와인의 성분들에 대한 표입니다. 타겟은 Class였죠.
패키지를 호출합니다.
# 필요한 라이브러리 (전처리용) preprocessing 호출
# 최소 최대 스케일링의 라이브러리 MinMaxScaler 호출
from sklearn.preprocessing import MinMaxScaler
scaler를 쓰기 위해 정의해줍니다.
mm_scaler = MinMaxScaler()
mm_scalerMinMaxScaler()
독립변수의 훈련셋 X_train은 스케일러에 적용해서 X_trainmm
독립변수의 시험셋 X_test는 스케일러에 적용해서 X_testmm
으로 지정합니다.
X_trainmm = mm_scaler.fit_transform(X_train)
X_testmm = mm_scaler.transform(X_test)
스케일러의 fit 자체는 train데이터로만 진행합니다.
X_trainmmarray([[0.45430108, 0.21146245, 0.44919786, ..., 0.55284553, 0.68498168,
0.31098431],
[0.90322581, 0.22332016, 0.5828877 , ..., 0.43902439, 0.84615385,
0.72182596],
[0.4327957 , 0.12252964, 0.35294118, ..., 0.40650407, 0.11721612,
0.12268188],
...,
[0.39784946, 0.09881423, 0.47593583, ..., 0.2195122 , 0.08791209,
0.26533524],
[0.57526882, 0.87944664, 0.51336898, ..., 0.09756098, 0.07692308,
0.31883024],
[0.16935484, 0.22529644, 0.29946524, ..., 0.6097561 , 0.31868132,
0.10699001]])
X_testmm의 실제 모습은 일단 넘어가겠습니다. (똑같이 array 뭉치입니다)
스크롤이 불필요하게 길어지네요.
X_testmm
자 이제, wine 데이터에서 진행했던 K-NN 알고리즘을 다시 불러옵니다.
아마 이전시간을 똑같이 따라했다면, 이미 있기 때문에 재시도할 필요는 없어집니다.
#K-NN 라이브러리 호출
#KNeigborsClassfier를 neighbors에서 소환
from sklearn.neighbors import KNeighborsClassifier
KNN알고리즘을 학습시키고, 모델을 만듭니다.
knn = KNeighborsClassifier()
knn.fit(X_trainmm, y_train)
pred = knn.predict(X_testmm)
좋습니다. predict한 값을 한번 보겠습니다.
predarray([3, 3, 2, 1, 2, 3, 1, 3, 2, 3, 3, 3, 2, 3, 3, 1, 1, 1, 1, 3, 1, 1,
2, 2, 1, 1, 2, 2, 2, 1, 1, 2, 1, 3, 1, 3])
이웃에 가까운 주변에서 5개를 비교합니다.
행을 모두 합하면 1이 됩니다. (가능성)
knn.predict_proba(X_testmm) # knn 근접의 주변에서 5개를 비교 (행을 합치면 1이 됩니다.)1
knn.predict_proba(X_testmm) # knn 근접의 주변에서 5개를 비교 (행을 합치면 1이 됩니다.)
array([[0. , 0. , 1. ],
[0. , 0. , 1. ],
[0.2, 0.8, 0. ],
[1. , 0. , 0. ],
[0. , 0.8, 0.2],
[0. , 0. , 1. ],
[1. , 0. , 0. ],
[0. , 0. , 1. ],
[0. , 1. , 0. ],
[0. , 0. , 1. ],
[0. , 0. , 1. ],
[0. , 0. , 1. ],
[0. , 1. , 0. ],
[0. , 0. , 1. ],
[0. , 0. , 1. ],
[0.8, 0.2, 0. ],
[1. , 0. , 0. ],
[1. , 0. , 0. ],
[1. , 0. , 0. ],
[0. , 0. , 1. ],
[1. , 0. , 0. ],
[1. , 0. , 0. ],
[0. , 1. , 0. ],
[0. , 1. , 0. ],
[1. , 0. , 0. ],
[1. , 0. , 0. ],
[0. , 0.8, 0.2],
[0. , 0.8, 0.2],
[0.2, 0.8, 0. ],
[1. , 0. , 0. ],
[1. , 0. , 0. ],
[0. , 1. , 0. ],
[1. , 0. , 0. ],
[0. , 0. , 1. ],
[1. , 0. , 0. ],
[0. , 0. , 1. ]])
다시 정확도를 평가해 볼까요?
패키지 호출
# 정확도 평가
from sklearn.metrics import accuracy_score
시험셋과 예측 적용합니다.
accuracy_score(y_test, pred)0.9722222222222222
정확도 점수도 다시 대폭 상승한 것이 보이는군요.
헌데, 문제가 무엇이었을까요?
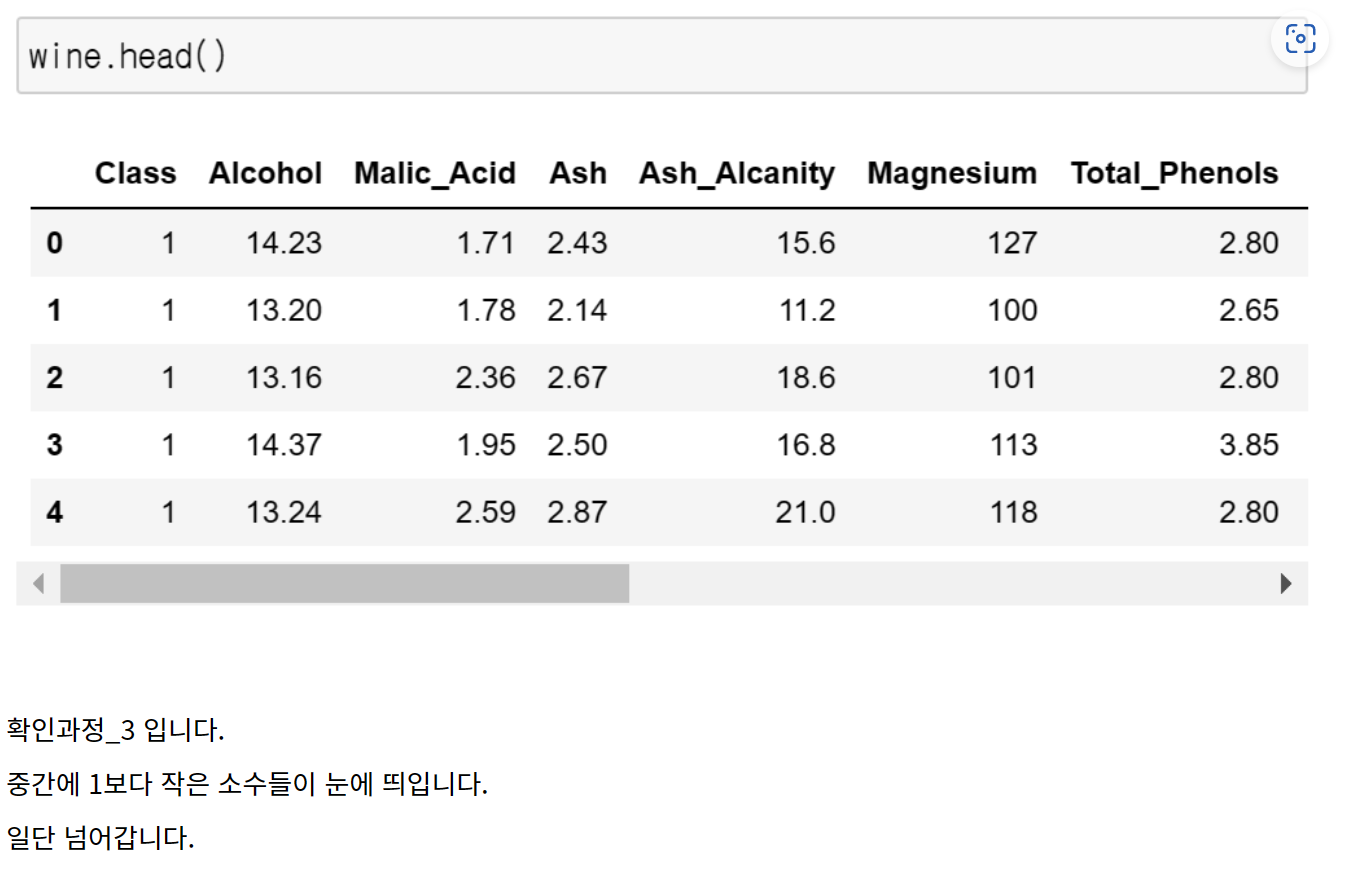
바로 이 부분이었습니다.
1이하의 소수점을 가진 숫자들이 Hue나 Nonflavanoid_Phenols 에서는 계속 보였던 반면
Proline이나 Magnesium에서는 백의 자리는 물론, 천의 자리까지 데이터가 존재해서
스케일이 제각각이었기 때문이죠.(격차)
- KNN 알고리즘은 변수의 스케일 간의 격차가 클 경우, 산출되는 거리값이 왜곡될 수 있습니다.
😥
때문에 데이터의 스케일러는 wine 데이터프레임에서
사실상 선택의 문제가 아니라, 필수였던 것이죠!
이후에는 격차를 줄이는 데이터 처리 방법인 Scaling에 대해서 확인해보겠습니다!
'머신러닝 > 지도학습' 카테고리의 다른 글
| [Machine Learning] 결정트리_회귀(Regression) 실습 사례- 보험비 (0) | 2022.12.22 |
|---|---|
| [Machine Learning] 결정트리 알고리즘 분류 실습사례_wine (0) | 2022.12.22 |
| [Machine Learning] KNN 알고리즘 실습사례_wine 분류 (0) | 2022.12.19 |
| 선형회귀 ep2. 결정계수에 관하여 (2) | 2022.12.16 |
| Machine Learning ep.1 선형회귀 기초개념 & 마을의 보험료 예측 (0) | 2022.12.15 |



