
서론

얼마 있으면 이쁜 트리가 거리에서 많이 보이는 크리스마스가 시작되네요!
이번 시간에는 지난번 실시했던 똑같은 wine csv 파일을 통해
결정트리 문제를 진행해보겠습니다.
원본은 동일한 csv파일이고, 분류하는 알고리즘만 변형시킨 것입니다.
목표는 각 feature별로 조건이 분기되는 트리를 만드는 것입니다.
분류문제의 평가 점수를 계산한 후에, plot_tree를 통해 시각화가 어떻게
구현되는지 보게될 것입니다.
마찬가지로, 실습을 서술한 글이기 때문에, 오류와 오판이 있을 수 있음에 양해 드립니다
먼저 결정트리(Decision Tree)란 무엇인지 간단하게 보겠습니다.
Decision Tree 개념
기본적으로 분류 문제와 회귀 문제를 해결하는 툴로 나뉩니다.
분류문제를 DecisIon Tree Classfier, 회귀문제를 Decision Tree Regressor로
모델링합니다.
결정트리는 데이터를 무수하게 쪼개어 나가고,
각 그룹에 대한 예측치를 만드는 방식으로
수많은 트리 모델의 기본이 되는 알고리즘 입니다.
일종의 순서도처럼, 뿌리와 가지모양으로 쪼개지면서 수많은 분기점들을
만들게 되는데요?
이러한 모습때문에 Decision tree가 되었습니다.

단점
단, 가지가 끝없이 깊어지면 과적합(Overfitting) 문제가 발생하고,
최근들어 개발되고 있는 트리 기반 모델에 비해서는 예측력이 계속 떨어진다는
단점도 있습니다.
일단, 정확한 설명은 사이킷런에서 정리한 문서에서 확인하실 수 있습니다.
물론 필자보다 훌륭한 수많은 블로그에서도 이 개념에 대해서 다루고 있습니다👍
https://scikit-learn.org/stable/modules/tree.html
1.10. Decision Trees
Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning s...
scikit-learn.org
8.1 의사결정나무 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
먼저, 필요한 도구들을 불러오는 것부터 시작하겠습니다.
# 필요한 라이브러리 호출
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import sklearn
wine = pd.read_csv('wine.csv')
wine
데이터를 처음 불러왔으니, info(), describe() 등 여러가지 정보를
작성해봅니다.
wine.info() # 변수 고려중<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178 entries, 0 to 177
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Class 178 non-null int64
1 Alcohol 178 non-null float64
2 Malic_Acid 178 non-null float64
3 Ash 178 non-null float64
4 Ash_Alcanity 178 non-null float64
5 Magnesium 178 non-null int64
6 Total_Phenols 178 non-null float64
7 Flavanoids 178 non-null float64
8 Nonflavanoid_Phenols 178 non-null float64
9 Proanthocyanins 178 non-null float64
10 Color_Intensity 178 non-null float64
11 Hue 178 non-null float64
12 OD280 178 non-null float64
13 Proline 178 non-null int64
dtypes: float64(11), int64(3)
memory usage: 19.6 KB
지난 실수를 대비하여 스케일도 확인해봅니다.
wine.describe() # 스케일링이 필요한지 체크
다만, 결정트리 알고리즘은 스케일링의 영향력이 작기 때문에
큰 필요는 없어 보이네요.
# nan 값은? nan값 없음
wine.isnull().sum()Class 0
Alcohol 0
Malic_Acid 0
Ash 0
Ash_Alcanity 0
Magnesium 0
Total_Phenols 0
Flavanoids 0
Nonflavanoid_Phenols 0
Proanthocyanins 0
Color_Intensity 0
Hue 0
OD280 0
Proline 0
dtype: int64
늘 문제가 되는 Nan값도 있는지 찾아 봅니다.
👉없습니다.
# 소수점 축약
pd.options.display.float_format = '{:,.4f}'.format
과도하게 길어지는 소수점도 4자리 정도로 줄여줍니다.
기본적으로 훈련셋, 시험셋은 구분해줘야 하기 때문에
train_test_split도 호출해줍니다.
# 종속변수 Class
# 독립변수 class 그 외
from sklearn.model_selection import train_test_split
X = wine.drop('Class', axis = 1)
y = wine['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 12)
지난 데이터와 마찬가지로 독립변수는 와인의 각종 feature들,
종속변수는 와인의 class로 잡았습니다.
위에서 서술했듯이, 목표는 feature별로 분기되는 결정트리 즉,
데이터의 분류를 보는 것입니다.
패키지는 분류문제에서 사용되는 DecisionTreeClaasifier입니다.
# DecisionTreeClassifier 패키지 호출
from sklearn.tree import DecisionTreeClassifier
모델 지정합니다.
랜덤값은 특별한 의도는 없습니다.
# 모델 설정
model = DecisionTreeClassifier(random_state=210)
이미 분류한 X,y 훈련셋들을 적용합니다.
# 적용합니다
model.fit(X_train, y_train)
pred = model.predict(X_test)
예측값을 잠깐 볼까요?
predrray([3, 3, 2, 1, 2, 3, 1, 3, 2, 1, 3, 3, 2, 1, 1, 1, 1, 1, 1, 3, 1, 1,
2, 2, 1, 1, 2, 2, 2, 1, 1, 2, 1, 3, 1, 3])
pred에 대한 정확도 점수도 작성해보겠습니다.
어떻게 될까요.
# 정확도 점수 찍기
from sklearn.metrics import accuracy_score
점수 계산용 패키지를 올려봅니다.
accuracy_score(y_test, pred)0.9166666666666666
91점으로 확인이 되는군요.
이제 트리 시각화로 들어가보겠습니다.
패키지는 plot_tree를 사용했습니다.
# 시각화
# 트리 그래프 호출
from sklearn.tree import plot_tree
# 사이즈 조정
plt.figure(figsize=(20, 14))
# depth 3으로 설정
plot_tree(model, max_depth=3, fontsize=20, feature_names = X_train.columns)
plt.title("wanna wine?")
plt.show()
사이즈는 너무 작지 않게 조정했구요.
노드들의 깊이를 나타내는 max_depth는 3으로 설정했습니다.
max_depth를 10이상으로 하거나 전체(19)로 하면 컴퓨터가 멈추더군요.
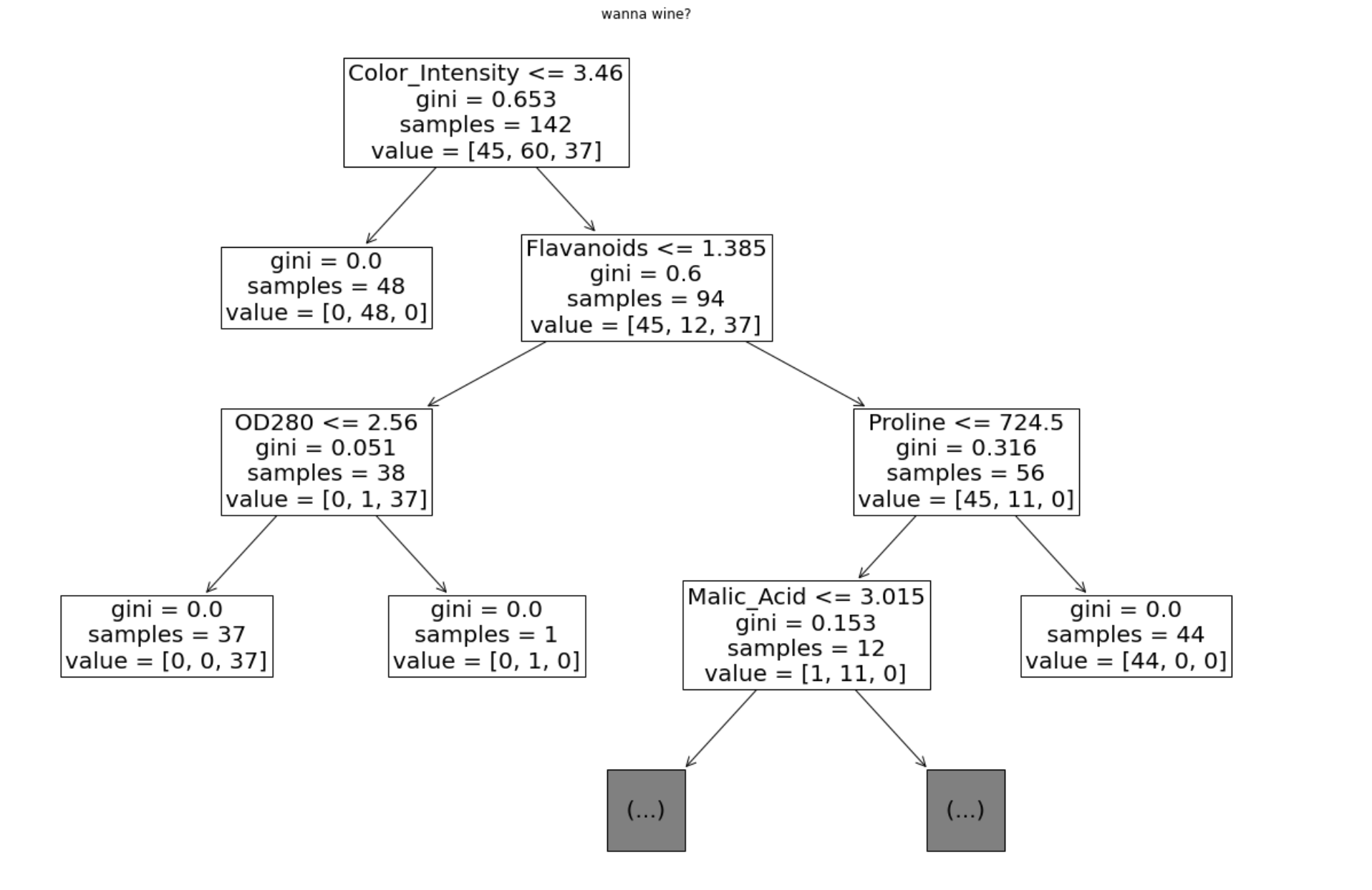
이렇게 하여, wine을 통한 결정트리 분류문제 풀이와 시각화가
모두 종료되었습니다!
'머신러닝 > 지도학습' 카테고리의 다른 글
| [Machine Learning] Naive_Bayes 모델 사례_spam mail 분석 (5) | 2022.12.25 |
|---|---|
| [Machine Learning] 결정트리_회귀(Regression) 실습 사례- 보험비 (0) | 2022.12.22 |
| [Machine Learning] KNN 알고리즘 실습사례_wine 분류2_solution (0) | 2022.12.21 |
| [Machine Learning] KNN 알고리즘 실습사례_wine 분류 (0) | 2022.12.19 |
| 선형회귀 ep2. 결정계수에 관하여 (2) | 2022.12.16 |



