
서론
Naive Bayes 모델은 통계학에서의 베이즈 정리에서 응용한
자연어 처리용 분류 모델입니다. 이후에 나오는 모델에 비해
단순하고 낮은 수준의 모델이지만 이 모델을 사용하는 이유는 속도가 빠르고
순진(naive)하기 때문에 쉬운 수준에서의 알고리즘 분석에는 유용했기 때문입니다.
나이브 베이즈를 위해서는 베이즈 정리에 대해서 잠깐 알아봐야 하는데요?
많은 사전, 블로그에서는 베이즈 정리에 대한
다양한 정의를 소개하고 있습니다만, 필자는 이 설명을 선호합니다.
이전의 경험과 현재의 증거를 토대로 어떤 사건의 확률을 추론하는 알고리즘
이 설명이 왜 나왔을까요.
베이즈 정리의 본 공식입니다.

사건 B가 발생함으로 인해 , 사건 A의 확률이 어떻게 변화하는지를 표현한 정리입니다.
즉, 베이즈 정리를 쓰면 데이터가 주어지기 전의 사전 확률값이, 데이터가 주어지면서
어떻게 변화하는지 계산할 수 있습니다.
베이즈 주의에서 출발한 베이즈 인식론 이라는 분야도 있습니다.
https://www.kyosu.net/news/articleView.html?idxno=31509
‘과학 방법론’으로 살아남으려면 어떤 대답을 던져야할까? - 교수신문
학부 시절에 베이즈주의(Bayesianism)를 처음으로 접했을 때의 놀람을 아직도 기억하고 있다. 막연히 알고 있었던 합리적 사고의 전형을 베이즈주의를 통해서 봤기 때문인데 확률론의 공리 체계를
www.kyosu.net
우리는 의심할 수 없는 진짜를 어떤 기준으로 판단할까요?
제가 '그것이 맞다'고 믿는 것은 그것이 T / F로 쉽게 구분할 수 없습니다.
맞다, 틀리다가 아니라, 0.6 정도로 맞거나, 0.8정도로 맞거나, 0.2 정도로 맞다고
표현할 수 있습니다.
So, 믿음의 문제는 그렇다/그렇지 않다의 문제가 아니라
%로 표현되는 정도의 세계입니다.
여기까지 해서 베이즈 주의의 설명이었습니다.

이렇게까지 해서 넘어가고, 실제 사례를 보겠습니다.
이번에 필자가 도전해볼 데이터는 spam mail을 분류하는 데이터입니다.
value는 스팸일 경우 spam, 스팸이 아닐 경우 ham으로 작성되어 있습니다.
SMS Spam Collection Dataset
Collection of SMS messages tagged as spam or legitimate
www.kaggle.com
목표는 종속변수 spam(target으로 만들 예정)일 경우 예측하여
True-Positive(TP), True-Negative(TN)의 값을 최대화 하는 것입니다.
*TP는 positive로 예측한 것이 True(참)으로 밝혀지는 것, TN은 negative로 예측한 것이
true로 밝혀지는 것입니다💯
(FN은 Negative로 예측한 것이 False(거짓)으로 밝혀진 것, FP는 positive로 예측한 것이
False로 밝혀진것)
즉 FN과 FP의 값은 최소화하는 것이 안전성을 보장할 수 있는 엔지니어링 입니다.
사용하는 알고리즘은 Naive-Bayes의 분류를 위한 알고리즘 입니다.
사용하는 라이브러리 호출합니다.
# 필요한 라이브러리 호출
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import sklearn
spam mail의 원본 csv파일은 미리 저장하여, 구글 경로로 올려놓았습니다.
고로 바로 사용합니다.
spam = pd.read_csv('spam.csv')
spam
알수없는 Unnamed: 0 이라는 컬럼도 있습니다.
이는 인덱스 컬럼으로 옮겨주겠습니다.
spam = pd.read_csv('spam.csv', index_col = 0)
# 인덱스_col을 0번째 열로 바꿔서 target이 왼쪽으로 오게 수정함
spam
갯수를 확인합니다.
spam.info() # object 확인<class 'pandas.core.frame.DataFrame'>
Int64Index: 5574 entries, 0 to 5573
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 target 5574 non-null object
1 text 5574 non-null object
dtypes: object(2)
memory usage: 130.6+ KB
결측치가 있는지 확인합니다.
df.isnull().sum()target 0
text 0
dtype: int64
없네요.
그리고 spam과 ham의 대략적인 비교를 진행합니다.
df.target.value_counts().plot(kind = 'barh')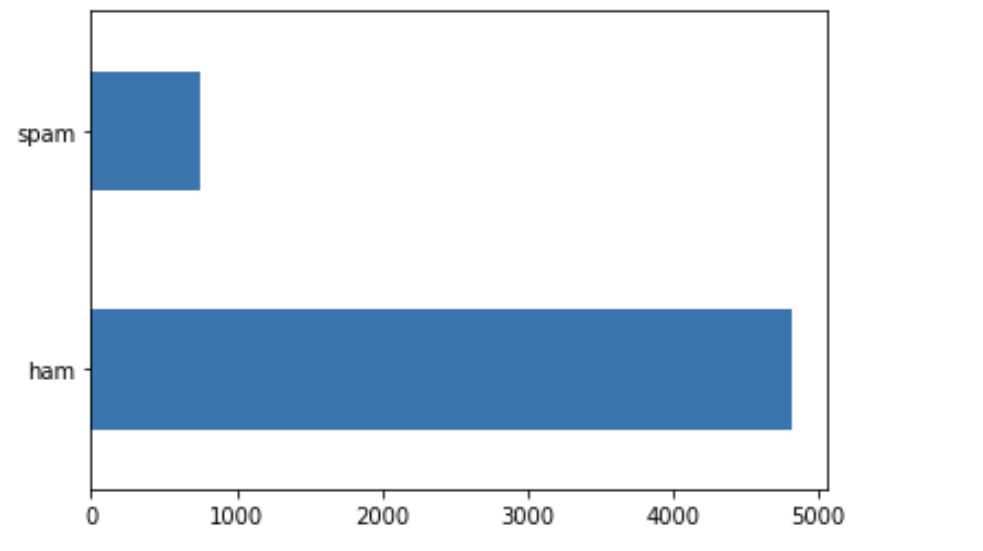
스팸이 아닌 데이터들이 거의 4000건 가까이 차이가 나는군요.
일단 데이터 전처리를 시작해 보겠습니다.
전처리
나이브 베이즈는 기본적으로 자연어 처리의 집합 안에 포함됩니다.
특정한 단어들이 존재하느냐 vs 존재하지 않느냐를 갖고
이것을 기준으로 배열화합니다.
일단 이번 데이터에서는 문장들을 일종의 단어 묶음덩어리들로 변환 시켜서
등장할 때에 모종의 기준을 갖고 배열로 바꿔주려 합니다.
spam의 가장 첫번째 문장을 예시로 봐보겠습니다.
first_text = spam.loc[0, 'text'] # 0번째 행 텍스트
first_textGo until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
이것은 문장입니다.
df.text[0].split()['Go',
'until',
'jurong',
'point,',
'crazy..',
'Available',
'only',
'in',
'bugis',
'n',
'great',
'world',
'la',
'e',
'buffet...',
'Cine',
'there',
'got',
'amore',
'wat...']
이것은 단어 묶음덩어리(뭉치) 입니다.
우리는 이렇게 묶음덩어리로 만들어야, 특정한 텍스트가 스팸에 속하는지
스팸에 속하지 않는지 구분할 수 있습니다.
그리고 나서
해당 작업을 한 후에는, 다음의 세 과정을 처리해야 합니다.
특수문자 제거
대소문자 차이 없애기
불용어 삭제
먼저 특수문자 제거를 진행합니다.
느낌표, 물음표, 쉼표 등 문자열 자체에서 모든 특수문자는
사용처가 없습니다. 때문에 모두 제거해줘야 합니다.
다행히도 파이썬은 특수문자 찾기 패키지를 지원합니다.
from string import punctuation
punctuation!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
이를 사용하면 특수문자가 등장합니다.
이제 나름의 함수를 정의하여, 특수문자를 제거하는
함수를 생각해 볼 수 있습니다.
# 단 하나의 쉬운 함수로 특수기호 삭제하는 함수 저장
def remove (old_text: str):
new_text = ''
for c in old_text:
if c not in punctuation:
new_text += c
return new_text
new_text 라는 빈 문자열을 지정하고
old_text를 반복하는데 이제 텍스트 안에서
punctuation(특수문자)가 없을 경우, 그 문자를 new_text안에 넣어줍니다.
계속 반복해서 조회하면서 비 특수문자를 넣습니다.
그럼 결과는?
특수문자가 없는 것(문자열)만 처리되서 반출될 수 있습니다.
remove(first_text)'Go until jurong point crazy Available only in bugis n great world la e buffet Cine there got amore wat'
바로 위에 있었던 첫번째 문장의 특수기호 삭제된 버전입니다.
단, 이 함수는 한가지 문제가 있는데요.
remove(spam.text)
# 전체 데이터는 기호를 삭제하지 못함'Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...Ok lar... Joking wif u oni...Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C\'s apply 08452810075over18\'sU dun say so early hor... U c already then say...Nah I don\'t think he goes to usf, he lives around here thoughFreeMsg Hey there darling it\'s been 3 week\'s now and no word back! I\'d like some fun you up for it still? Tb ok! XxX std chgs to send,
(...중략)
텍스트 전체를 넣어버리면, 특수기호는 삭제하지 못한다는 점입니다.
이럴때는 한줄씩 구분하게 해주는 메서드를 사용해야 할텐데요.
그것이 바로 apply 메서드 입니다.
.apply 메서드
spam.text.apply(remove)0 Go until jurong point crazy Available only in ...
1 Ok lar Joking wif u oni
2 Free entry in 2 a wkly comp to win FA Cup fina...
3 U dun say so early hor U c already then say
4 Nah I dont think he goes to usf he lives aroun...
...
5569 This is the 2nd time we have tried 2 contact u...
5570 Will ü b going to esplanade fr home
5571 Pity was in mood for that Soany other suggest...
5572 The guy did some bitching but I acted like id ...
5573 Rofl Its true to its name
Name: text, Length: 5574, dtype: object
사용시 한줄씩 구분해서 remove 함수를 사용할 수 있습니다.
위는 그 결과입니다.
spam의 변수로 저장해줍시다.
spam.text = spam.text.apply(remove)
spam.text # 전부 삭제 완료 및 한줄씩 구분됨
삭제된 점 확인합니다.
spam

좋습니다.
이제 불용어 삭제 차례입니다.
불용어 처리는 일단 어떻게 불용어들을 찾는지 보고
그 다음단계인 소문자 만드는 작업은 어렵지 않으므로 한꺼번에 진행하려합니다.
우리의 목적은 무엇이었을까요?
문장에 대한 분석인데, 기왕이면 효율적으로 단어들을 재정리하면 좋겠죠.
하지만 일반적으로 사용하는 문장에는 분석에 꼭 필요한 요소만 있는게 아닙니다.
그것이 꼭 존재하지 않아도, 중심의미를 이해할 수 있는 요소들도 있습니다.
즉, 언어를 분석할 때 의미가 없는 단어들을 머신러닝에서는 불용어라고 합니다.
영어로는 stopwords라고 하네요.
불용어는 쉽게 정의할 순 없지만,
대표적으로는 영어의 전치사를 생각해볼 수 있습니다. 문법적으로 꼭
필요하긴 하지만 문단의 중심내용이나, 글쓴이의 의도를 파악하려 한다면
전치사는 반드시 필요한 텍스트라고 보긴 어려울 것입니다.
stopwords도 바로 구분할 수 있는 도구가 있는데요?
바로 자연어 처리전용 툴킷인 NLTK(Natural Language Toolkit) 입니다.
# Natural Language Toolkit
import nltk아래 공식 사이트에서도 자세한 개념을 확인할 수 있습니다.
NLTK :: Natural Language Toolkit
Natural Language Toolkit NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries
www.nltk.org
여기서 일종의 말뭉치 패키지 중 stopwords를 찾을 수 있습니다.
이는 영어, 프랑스어(french), 중국어(chinese), 스페인어(spanish) 등의 언어 중
불용어 뭉치들을 찾아줄 수 있습니다.
여담으로 한국어도 불용어 패키지 안에 존재할까요?
안타깝게 존재하지 않습니다😓
다만 일본어도 없다는 점, 조금의 위안이 되네요😋
from nltk.corpus import stopwords
길게 투자할만한 설명은 아니니, 바로 호출해줍니다.
# 영어의 불용어 호출
stopwords.words('english')['i',
'me',
'my',
'myself',
'we',
'our',
'ours',
'ourselves',
'you',
"you're",
"you've",
"you'll",
"you'd",
'your',
'yours',
'yourself',
'yourselves',
'he',
'him',
....
생략
정말 많은 불용어가 제시됩니다. 일단 생략했지만, 직접 조회해 보는 것도
좋을 것입니다.
이를 정의해줍니다.
stop_words = stopwords.words('english')
이제 다시 함수를 활용할 것인데요. 시작에는 문장을 분리하고,
분리해서 나온 단어들을 들고와서, 불용어 뭉치들과 일치하는지 검색하고
맞으면 삭제하는 함수를 만들면 좋겠습니다.
한번 보겠습니다.
for word in split:
if word not in stop_words:
print(word)Go
jurong
point
crazy
Available
bugis
n
great
world
la
e
buffet
Cine
got
amore
wat
자, 불용어를 없애는 함수를 제작했습니다.
이것을 전체 텍스트로 사용해도 좋을텐데요.
일단은 잠깐 중지하고, 소문자로 변환하는 작업을 진행하려 합니다.
소문자화
여기서부터는 약간의 언어적 지식이 들어갑니다.
영미권 국가의 언어, '영어'는 Alphbet 내에서도 두가지 문자로 나눠집니다.
바로 대문자와 소문자죠?
무의식적으로 우리는 영어 문장을 필기할때 단어의 앞에 대문자를 사용해서
대문자와 소문자를 자연스럽게 사용하고 있다고 생각하겠지만,
실상 영어는 대문자(Upper case letter)와 소문자 (Lower case letter),
두 시스템의 문자를 한꺼번에 사용하는 꼴입니다. 때문에 특정 대명사
(US, TKO 등)을 제외하고는 대문자를 소문자로 변환하는 것만으로도
따져봐야 하는 단어의 갯수를 확연하게 줄여줄 수 있습니다.
이렇게 되었고, 소문자로 바꾸는 방법은 큰 어려움은 없습니다.
.lower를 붙여주면 됩니다.
# 모든 문자열들을 소문자로 만듬
for word in split:
lower = word.lower()
if lower not in stop_words:
print(lower)go
jurong
point
crazy
available
bugis
n
great
world
la
e
buffet
cine
got
amore
wat
자 이를 소문자화 시켜서 텍스트에 추가시켜주는 함수로
다시 생성해줍니다.
# 임의의 함수로 재생성!!
def remove_stop_words(text):
new_text = []
for word in new_text.split():
lower = word.lower()
if lower not in stop_words:
new_text.append(lower) # lower를 객체로 추가시킴
return " ".join(lower)
띄어쓰기는 알맞게 잘 조정해주어야 합니다.
# spam 복사
df = spam
이제 직접 넣어보겠습니다.
아까 수정했던 텍스트를 apply와 함께 넣어줍니다.
엄청난 분량의 스크롤 뭉치들이 보여지고 있습니다.
이제 target열의 더미데이터를 생성하여, spam과 비spam을 0과 1정도로 나눠줍니다.
# dummies로 target의 더미데이터 생성하고 원래 있던것은 삭제
pd.get_dummies(spam, columns=['target'], drop_first=True)
이 피쳐는 일종의 종속변수처럼 쓸 예정입니다.
df.target = df.target.map({'spam':1, 'ham':0}) # 딕셔너리(사전)
df.target0 0
1 0
2 1
3 0
4 0
..
5569 1
5570 0
5571 0
5572 0
5573 0
Name: target, Length: 5574, dtype: int64
(현재 데이터프레임)

먼저 문자와 관련된 패키지를 호출했습니다.
빈도수를 기반으로 벡터화 하는 패키지입니다.
from sklearn.feature_extraction.text import CountVectorizer
X = df.text # 피쳐
y = df.target # 타겟
Countervectorizer는 문서를 토큰 리스트로 변환하고,
각 문서에서 토큰의 출현 빈도를 세고, BOW 인코딩(전체문서를
고정된 단어장처럼 만드는 것) 벡터로 변환합니다.
※ 이 글에서는 아래 링크를 참조했습니다.
Scikit-Learn의 문서 전처리 기능 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
단어들을 하나하나 카운트를 세줍니다.
cv.vocabulary_{'go': 3822,
'until': 8779,
'jurong': 4734,
'point': 6501,
'crazy': 2518,
'available': 1427,
'only': 6094,
'in': 4444,
'bugis': 1901,
'great': 3919,
'world': 9288,
'la': 4895,
'buffet': 1899,
'cine': 2235,
'there': 8352,
'got': 3879,
'amore': 1188,
'wat': 9040,
'ok': 6054,
'lar': 4934,
'joking': 4702,
....
생략
vocabulary를 호출하면, 수~백개의 단어가 카운트 되는 것을
알수 있습니다.
벡터화된 상태로 변형합니다.
X = cv.transform(X)
거의 다 왔습니다!
알고리즘을 학습시켜보기 위해, 훈련셋과 시험셋으로 나눠줍니다.
테스트 사이즈는 0.2로 했습니다.
# split 시작
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 20)
나이브 베이즈 분류기는 GaussianNB, BernoulliNB, MultinomialNB
이렇게 세 가지입니다.
GaussianNB는 연속적인 어떤 데이터에도 적용할 수 있고
BernoulliNB는 이진 데이터를 적용할 때
MultinomialNB는 카운트 데이터(특성이 어떤 것을 헤아린 정수 카운트.
예를 들면 문장에 나타난 단어의 횟수입니다)에 적용됩니다.
BernoulliNB, MultinomialNB는 대부분 텍스트 데이터를 분류할 때 사용합니다.
패키지를 호출합니다.
# 나이브 베이즈 모델
from sklearn.naive_bayes import MultinomialNB
모델링을 진행해줍니다.
# 모델링 시작
model = MultinomialNB()
model.fit(X_train, y_train)
pred = model.predict(X_test)
예측값 확인
predarray([0, 1, 1, ..., 0, 0, 0])
정확도 점수도 계산할 수 있도록 호출해줍니다.
from sklearn.metrics import accuracy_scoreaccuracy_score(y_test, pred)0.9820627802690582
좋습니다. 약 98점에 근접하는 점수를 보여줍니다.
예측값과 참/거짓의 혼동 확률을 보여주는
confusion matrix라는 것도 제작해보겠습니다.
# 혼동 행렬
from sklearn.metrics import confusion_matrix
counter matrix 정의
confusion_matrix(y_test, pred)array([[954, 12],
[ 8, 141]])
단순 배열로만 보면 이해가 어려우실 겁니다.
단순화한 heatmap 그래프로 시각화 해보겠습니다.
sns.heatmap(confusion_matrix(y_test, pred), cmap='coolwarm', annot=True, fmt='.0f')
plt.title("CONFUSION MATRIX")
plt.ylabel('True')
plt.xlabel('Predicted')
plt.show()
인덱스와 라벨값을 추가해서, 소수점 2개 정도의 값을
서술하는 매트릭스를 만들어줍니다.
cf_matrix = confusion_matrix(y_test,pred)
cf_matrix
group_names = ['TN','FP','FN','TP']
group_counts = ["{0:0.0f}".format(value) for value in
cf_matrix.flatten()]
group_percentages = ["{0:.2%}".format(value) for value in
cf_matrix.flatten()/np.sum(cf_matrix)]
labels = [f"{v1}\n{v2}\n{v3}" for v1, v2, v3 in
zip(group_names,group_counts,group_percentages)]
labels = np.asarray(labels).reshape(2,2)
sns.heatmap(cf_matrix, annot=labels, fmt='', cmap='coolwarm')
plt.ylabel('True')
plt.xlabel('Predicted')
plt.show()
어떤가요?
서두에서 목표로 했던 TN과 TP가 최적화된 숫자로 나왔을까요?
이상으로, 나이브 베이즈 모델의 실습 사례를 마치겠습니다.
'머신러닝 > 지도학습' 카테고리의 다른 글
| [Machine Learning] Kaggle_연습사례 분석_Spaceship_titanic (2) | 2022.12.27 |
|---|---|
| [Machine Learning] Naive_Bayes 모델_ep.2 colab 검색기 (0) | 2022.12.26 |
| [Machine Learning] 결정트리_회귀(Regression) 실습 사례- 보험비 (0) | 2022.12.22 |
| [Machine Learning] 결정트리 알고리즘 분류 실습사례_wine (0) | 2022.12.22 |
| [Machine Learning] KNN 알고리즘 실습사례_wine 분류2_solution (0) | 2022.12.21 |



