
서론
지난 시간에서 나이브 베이즈 모델을 통해
spam mail 리스트 중에서 특정한 단어가 포함되어 있을 시 자동으로
spam으로 표시하는 자연어 처리에 대해서 실습해보았습니다.
이번 시간에는 진행했던 파일을 갖고, 우리가 특정한 단어를 입력하면
"스팸이다", "스팸이 아니다" 등 문장으로 구분해주는 알고리즘을
만들어 보고자 합니다.
먼저 지난 시간에 했던 모델입니다.
# 나이브 베이즈 모델
from sklearn.naive_bayes import MultinomialNB
# 모델링
model = MultinomialNB()
model.fit(X_train, y_train)
pred = model.predict(X_test)
pred
array([0, 1, 1, ..., 0, 0, 0])
혼동 행렬(confusion_matrix)의 경우입니다.
cf_matrix = confusion_matrix(y_test,pred)
cf_matrix
group_names = ['TN','FP','FN','TP']
group_counts = ["{0:0.0f}".format(value) for value in
cf_matrix.flatten()]
group_percentages = ["{0:.2%}".format(value) for value in
cf_matrix.flatten()/np.sum(cf_matrix)]
labels = [f"{v1}\n{v2}\n{v3}" for v1, v2, v3 in
zip(group_names,group_counts,group_percentages)]
labels = np.asarray(labels).reshape(2,2)
sns.heatmap(cf_matrix, annot=labels, fmt='', cmap='coolwarm')
plt.ylabel('True')
plt.xlabel('Predicted')
plt.show()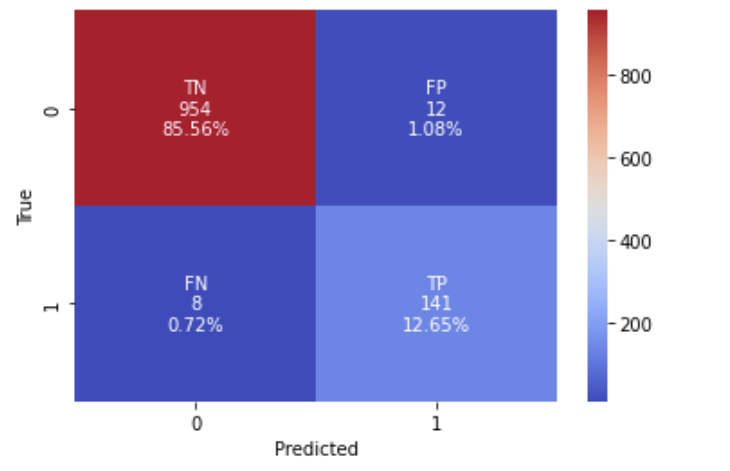
이번에 사용할 도구는 바로 'colab params' 입니다.
params는 코드 우측에 텍스트 검색기를 띄어줌으로서
규칙에 맞는 텍스트를 반환하거나, 혹은 반환하지 않는 기능을
사용할 수 있습니다.
출처는 아래와 같구요.
https://colab.research.google.com/notebooks/forms.ipynb
Forms
Run, share, and edit Python notebooks
colab.research.google.com
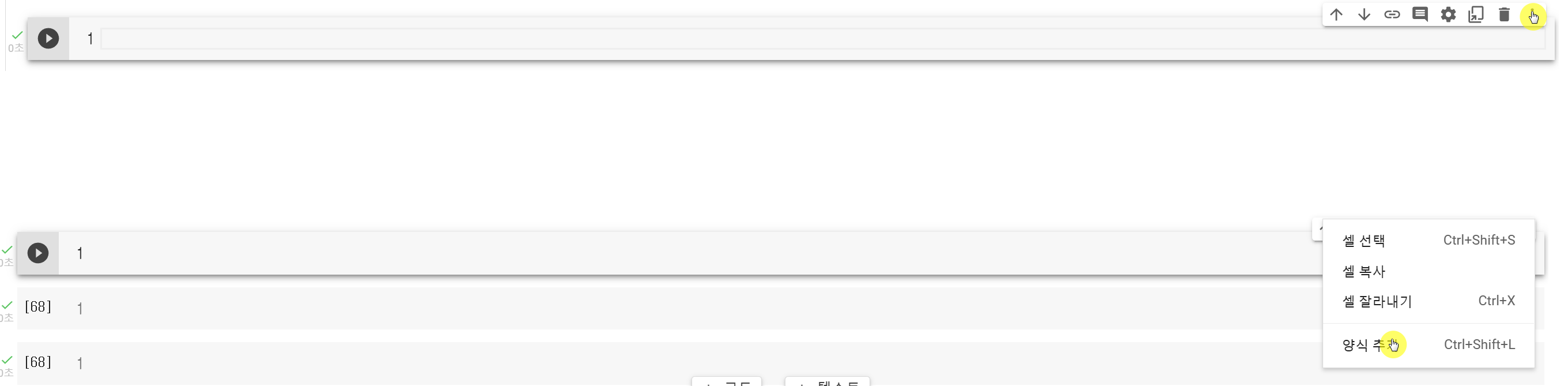
코랩의 코드를 추가하고, 우측 상단에 셀 작업 더보기를 클릭합니다.
그 후에 양식 추가를 클릭해 줍니다.
(ctrl+shift+L)
그렇다면 아래 형식이 생성되게 됩니다!

적당히 제목 텍스트는 바꿔줍니다.
스팸 검색기_나이브베이즈 사용
그리고 다시 설정을 들어가면 양식 부분이 약간 바뀌어 있습니다.
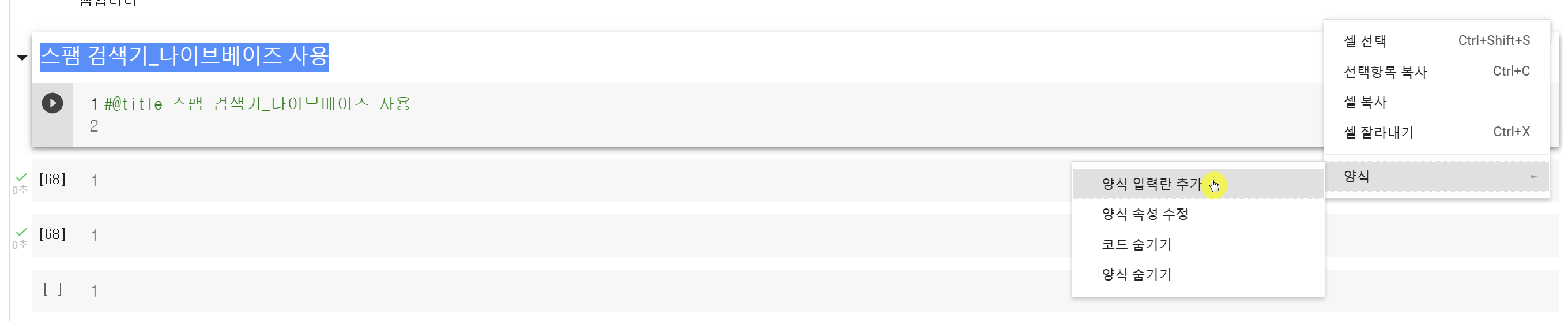
양식 입력란 추가를 클릭합니다.
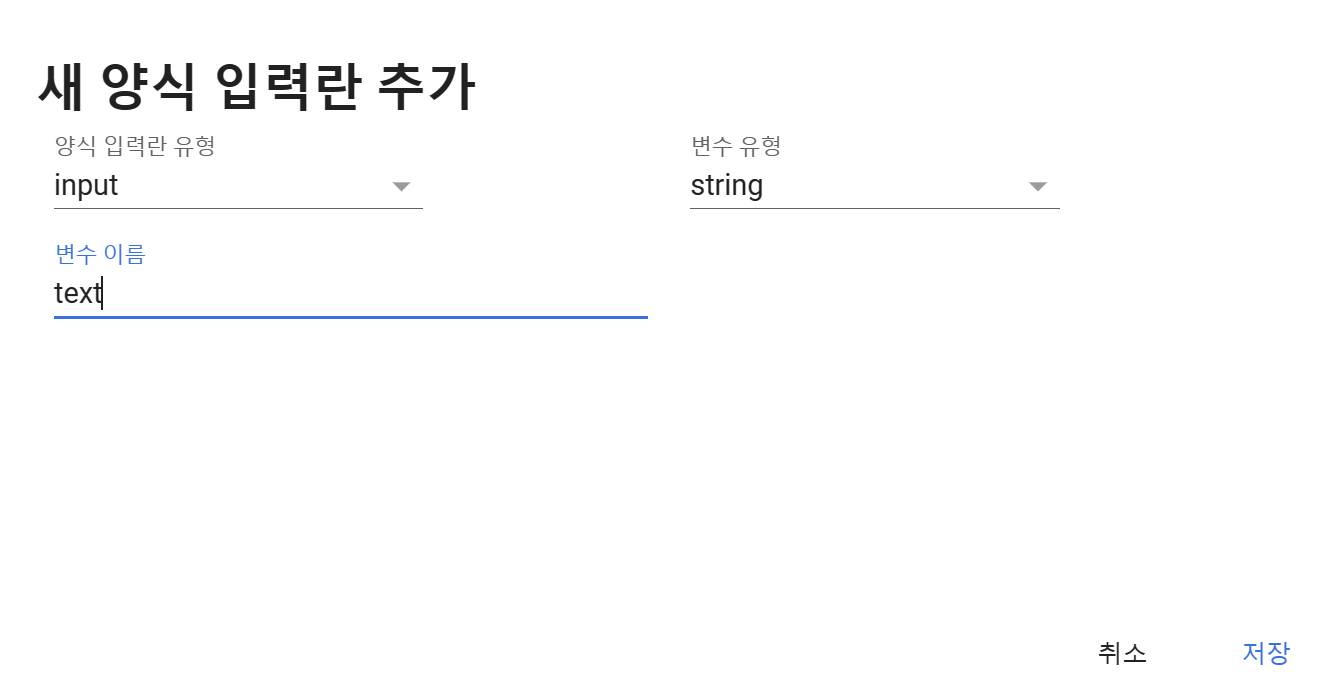
양식 입력란 유형은 그대로 input, 변수 유형도 그대로 string으로 두고(문자열)
변수 이름만 적당히 조정해줍니다. 이부분은 자유입니다.
자 그러면 생성된 것을 알 수 있는데요?

잠깐 들어가기에 앞서서, 지난시간에 데이터 전처리 과정을 한꺼번에 담았습니다.
def preprocessing(text):
#1. 특수문자 제거
new_text = ''
for c in text:
if c not in punctuation:
# print(c)
# new_text.append(c)
new_text += c
#2. 소문자화, 불용어 제거
new_text2 = []
for word in new_text.split():
l_word = word.lower()
# if l_word in stop_english:
if l_word not in stop_english:
# print(l_word)
new_text2.append(l_word)
return " ".join(new_text2)
요약하자면 아래와 같게 됩니다.
spam 데이터의 모든 데이터를 특수문자를 제거하고, 불용어를 제거한 뒤
소문자인 문자열만 조회해서 합쳐주는 것이죠.
preprocessing(df.text)go jurong point crazy available bugis n great world la e buffet cine got amore watok lar joking wif u onifree entry 2 wkly comp win fa cup final tkts 21st may 2005 text fa 87121 receive entry questionstd txt ratetcs apply 08452810075over18su dun say early hor u c already saynah dont think goes usf lives around thoughfreemsg hey darling 3 weeks word back id like fun still tb ok xxx std chgs send £150 rcveven brother like speak treat like aids patentas per request melle melle oru minnaminunginte nurungu vettam set callertune callers press 9 copy friends callertunewinner valued network customer selected receivea £900 prize reward claim call 09061701461 claim code kl341 valid 12 hours onlyhad mobile 11 months u r entitled update latest colour mobiles camera free call mobile update co free 08002986030im gonna home soon dont want talk stuff anymore tonight k ive cried enough todaysix chances win cash 100 20000 pounds txt csh11 send 87575 cost 150pday 6days 16 tsandcs apply reply hl 4 infourg
(전체 글 중략)
이부분을 정의해줍니다.
[preprocessing(text)]
또한, 문장에 나타난 단어의 횟수를 세줄 때 활용하는 카운터 벡터라이즈를 정의 했었습니다.
cv = CountVectorizer()
cv.fit(X)
이 부분도 text에 transform할때 활용해줍니다.
(cv.transform([preprocessing(text)]))
그리고 나이브베이즈 모델을 위에서 학습시킨 model을 정의했었습니다.
나이브베이즈 중 하나인 MultinomialNB 입니다.
from sklearn.naive_bayes import MultinomialNB
# 모델링
model = MultinomialNB()
model.fit(X_train, y_train)
이 모델을 학습하는데요?, 즉 합쳐줍니다.
model.predict(cv.transform([preprocessing(text)]))
그리고 함수로 활용하기 위해 pred로 정의
pred = model.predict(cv.transform([preprocessing(text)]))
"스팸검색기_나이브베이즈 모델"에 넣어줍니다!
기본적인 뼈대는 나왔습니다.

자 이제, spam입니다, spam아닙니다라고 말해줄 도구가 필요한 상황이죠.
그렇다면, pred는 spam 텍스트에서 학습되지 않은 것을 '0',
spam이라고 학습한 것을 '1' 이라고 표현할 것입니다.
어떤 것이 광고 메일일까요?
일단 가장 먼저 띄이는 spam 메일은 "free entry"입니다.
text = "free entry"
pred[0] == 1True
pred의 행에 1을 갖고 있는 것을 spam이 맞다고 평가했습니다.
이를 활용해서 함수를 작성해줍니다.
1이면 "스팸입니다" 0이면 "스팸 아닙니다" 라고 해주는 것이죠!
if pred[0] == 1:
print('스팸입니다')
else:
print('스팸 아닙니다')
이 모든것을 합쳐줍니다.
#@title 스팸 검색기_나이브베이즈 사용
text = "free entry" #@param {type:"string"}
pred = model.predict(cv.transform([preprocessing(text)]))
if pred[0] == 1:
print('스팸입니다')
else:
print('스팸 아닙니다')
실제로 화면을 볼까요?

이렇게 보여집니다.
혹시 광고가 아닐까 하는...free coupon가 들어간 모습도 보겠습니다.

🕵️♀️ 스팸이라고 조회되는 모습입니다!
자 이렇게해서, 모델링도 해보고 이를 사용해
특정단어를 검색하여 스팸/비스팸으로 구분하는
검색기도 완성했습니다.
다음시간에는 또다른 지도학습의 모델 실습사례를 시도하겠습니다.
'머신러닝 > 지도학습' 카테고리의 다른 글
| [Machine Learning] Kaggle_연습사례 분석_Spaceship_titanic_2 (0) | 2022.12.28 |
|---|---|
| [Machine Learning] Kaggle_연습사례 분석_Spaceship_titanic (2) | 2022.12.27 |
| [Machine Learning] Naive_Bayes 모델 사례_spam mail 분석 (5) | 2022.12.25 |
| [Machine Learning] 결정트리_회귀(Regression) 실습 사례- 보험비 (0) | 2022.12.22 |
| [Machine Learning] 결정트리 알고리즘 분류 실습사례_wine (0) | 2022.12.22 |



