※ 제이펍의 파이토치 첫걸음을 참조 했습니다.
이번시간에는 ResNet 을 활용한 전이모델을 이미 만들어진 모델인
'resnet18'을 활용해 taco와 burrito를 구분하는 모델을 구현해보겠습니다.
일반적으로 taco는 또르띠야에 고기와 채소를 올린 멕시코 음식으로, 위가 살짝
벌려져 있는 것이 특징입니다. burrito는 같은 멕시코 전통음식이지만 또르띠야를
둘둘 말아서 살짝 구운 것입니다. 재료 자체는 비슷한데, burrito는 돌돌 말려서
위가 닫혀있는 것이 특징입니다.
본의아니게 점심시간에 테스트를 진행하게 되어 먹는 것으로 모델을 골랐는데요.
먼저 사진을 한번 보겠습니다. (matplotlib의 imshow 사용)
Reference
https://github.com/lucidfrontier45
https://github.com/lucidfrontier45/PyTorch-Book
일본의 데이터 사이언스 전문인력 lucidfrontier45 님
import matplotlib.pyplot as plt# 학습 데이터 확인
# 타코(위가 뚫려 있음), 브리또 (위가 막혀있음) 혼합 배출
dataiter = iter(train_loader)
images, labels = next(dataiter)
img = utils.make_grid(images, padding=0)
npimg = img.numpy()
print(npimg.shape)
plt.figure(figsize=(10, 7))
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
0행 0~2열에 있는 것은 확실히 타코입니다.
반면 0행 6열의 경우 브리또가 섞여 있습니다.
다시 돌아와서, pytorch에 사용할 패키지를 로드해주고, colab에서 런타임 유형도
GPU로 변경해줍니다.
필자는 한꺼번에 진행했습니다.
import torch
import torchvision
import torch.nn.functional as F
from torch.utils import data
from torch import nn, optim
from torchvision import transforms, datasets
from torchvision.utils import save_image
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import models
from torchvision import utils
import os
import random
import tqdm# gpu 사용
USE_CUDA = torch.cuda.is_available()
device= torch.device("cuda" if USE_CUDA else "cpu")
print(f"Using Device : {device}")
데이터 파일은 미리 Github를 통해 다운로드받은 파일을 올려서 사용합니다.
!wget https://github.com/lucidfrontier45/PyTorch-Book/raw/master/data/taco_and_burrito.tar.gz
!tar -zxvf taco_and_burrito.tar.gz
훈련셋 이미지와 검증셋 이미지는 구분 처리합니다.
# dataset 작성
train_imgs = ImageFolder('/content/taco_and_burrito/train/',
transform = transforms.Compose([
transforms.RandomCrop(224),
transforms.ToTensor()
]))
test_imgs = ImageFolder('/content/taco_and_burrito/test/',
transform = transforms.Compose([
transforms.RandomCrop(224),
transforms.ToTensor()
]))
train_loader = DataLoader(train_imgs, batch_size = 32, shuffle = True)
test_loader = DataLoader(test_imgs, batch_size = 32, shuffle = False)
훈련셋 이미지의 클래스와 인덱스 구성요소도 확인하면, 부리또는 거짓(0), 타코는 참(1)값으로
형성되어 있는 것을 알 수 있습니다.
print(train_imgs.classes), print(train_imgs.class_to_idx)
이미지는 위에서 제시한 파일로, train loader의 배치 사이즈가 32로 정해놓았기 때문에
8x4개의 이미지가 조회할때마다 랜덤하게 바뀌긴 합니다.
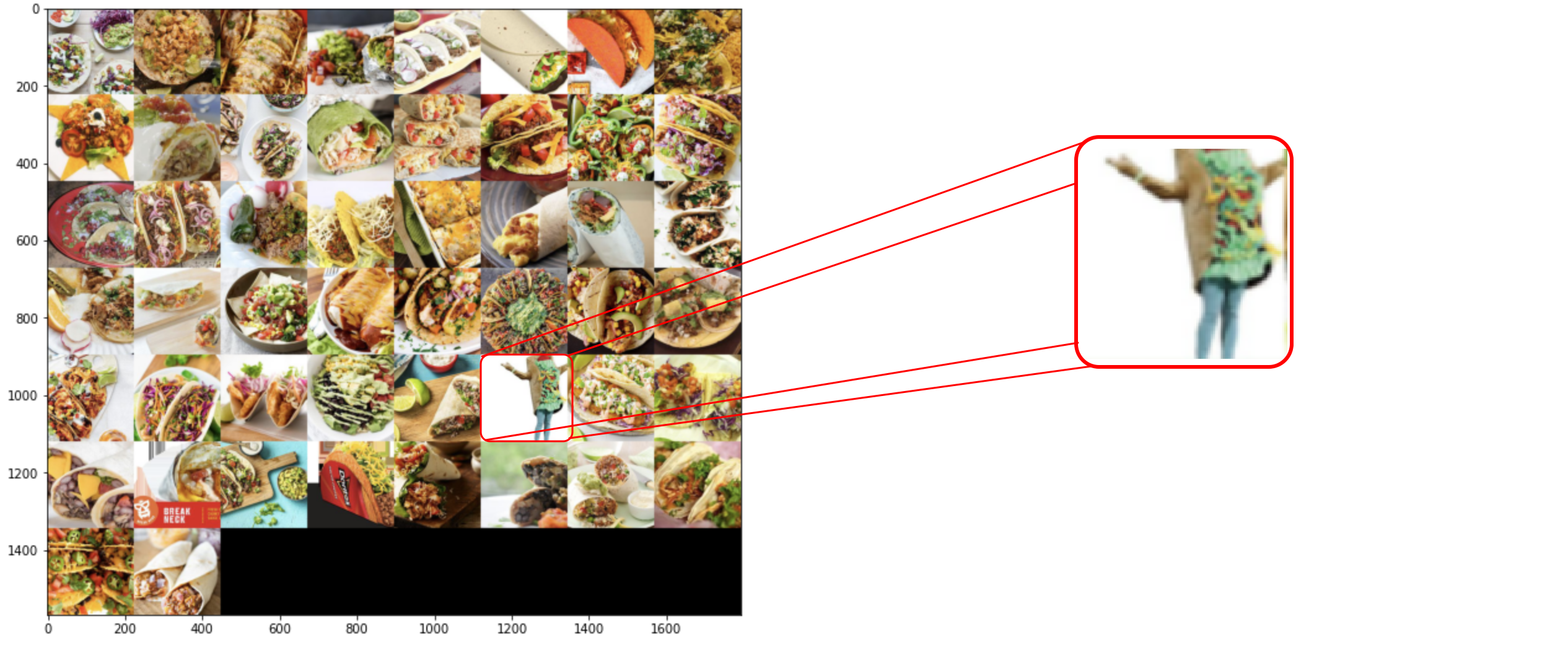
50개를 추가로 꺼내보았습니다.

이분은 어떻게 들어간 것일까요?
놀랍게도 타코를 입고 춤을 추고 있는 사람도 타코로 들어가 있습니다.
다음엔 아까 언급한 resnet이라는 미리 저장한 모델을 불러옵니다.
본 모델은 출력 linear 계층을 fc라는 이름으로 가져옵니다.
모든 패러미터를 미분 대상에서 제외시키고 새로운 linear 계층을 설정합니다.
# Resnet 미리 저장된 모델을 로드
net = models.resnet18(pretrained = True)
for p in net.parameters():
p.requires_grad = False
# 마지막 계층만 변경
fc_input_dim = net.fc.in_features
net.fc = nn.Linear(fc_input_dim, 2)
마지막 계층만 선형으로 수정합니다.
resnet18 덕분에 많은 과정이 생략됬습니다.
훈련함수를 제작하고,예측정확도까지 뽑아봅니다.
최적화 함수는 Adam(이미 성능이 검증된 함수였습니다)
손실 함수는 크로스 엔트로피 함수를 사용한 버전입니다.
# 모델 훈련 함수 제작
def eval_net(net, data_loader, device = device):
net.eval()
ys = []
ypreds = []
for x, y in data_loader:
x = x.to(device)
y = y.to(device)
with torch.no_grad():
_, y_pred = net(x).max(1)
ys.append(y)
ypreds.append(y_pred)
ys = torch.cat(ys)
ypreds = torch.cat(ypreds)
accuracy = (ys == ypreds).float().sum()/len(ys)
return accuracy.item()
# 훈련 함수. n_iter는 따로 조정 가능
def train_net(net, train_loader, test_loader, only_fc = True,
optimizer = optim.Adam, loss_function = nn.CrossEntropyLoss(),
n_iter = 10, device = device):
train_losses = []
train_accuracy = []
val_accuracy = []
if only_fc:
optimizer = optimizer(net.fc.parameters())
else: # 마지막 선형 계층의 패러미터만 optimizer 전달
optimizer = optimizer(net.parameters())
for epoch in range(1,n_iter):
running_loss = 0.0
net.train()
n = 0
n_accuracy = 0
for i, (xx, yy) in tqdm.tqdm(enumerate(train_loader), total = len(train_loader)):
xx = xx.to(device)
yy = yy.to(device)
h = net(xx)
loss = loss_function(h, yy)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
n = n + len(xx)
_, y_pred = h.max(1)
n_accuracy += (yy == y_pred).float().sum().item()
train_losses.append(running_loss / i)
train_accuracy.append(n_accuracy / n)
val_accuracy.append(eval_net(net, test_loader, device))
print(f'epoch 횟수 = {epoch}, 학습 loss = {train_losses[-1]:.4f}, 학습 정확도 = {train_accuracy[-1]:.4f},검증 정확도 = {val_accuracy[-1]:.4f}',
flush = True)
device인 gpu에서 훈련 시작. epoch는 20회, 학습 loss, 정확도, 검증 정확도가 차례대로 조회됩니다.
net.to(device)
# gpu에서 훈련 시작. EPOCH 20회
train_net(net, train_loader, test_loader, n_iter = 20, device = device)
1회~3회 epoch 시 loss 확인
100%|██████████| 23/23 [00:02<00:00, 9.18it/s]
epoch 횟수 = 1, 학습 loss = 0.8044, 학습 정확도 = 0.5084,검증 정확도 = 0.6500
100%|██████████| 23/23 [00:02<00:00, 9.22it/s]
epoch 횟수 = 2, 학습 loss = 0.6008, 학습 정확도 = 0.7275,검증 정확도 = 0.7833
100%|██████████| 23/23 [00:02<00:00, 9.50it/s]
epoch 횟수 = 3, 학습 loss = 0.5070, 학습 정확도 = 0.7935,검증 정확도 = 0.7833
100%|██████████| 23/23 [00:02<00:00, 9.46it/s]
19회~20회 epoch 시 loss 확인
100%|██████████| 23/23 [00:02<00:00, 9.36it/s]
epoch 횟수 = 19, 학습 loss = 0.2903, 학습 정확도 = 0.8848,검증 정확도 = 0.8167
100%|██████████| 23/23 [00:02<00:00, 9.46it/s]
epoch 횟수 = 20, 학습 loss = 0.2835, 학습 정확도 = 0.8961,검증 정확도 = 0.8667
epoch를 50회까지 늘려봅니다.
net.to(device)
# gpu에서 훈련 시작. EPOCH 50회
train_net(net, train_loader, test_loader, n_iter = 50, device = device)
50회 도달.
100%|██████████| 23/23 [00:02<00:00, 9.47it/s]
epoch 횟수 = 50, 학습 loss = 0.2425, 학습 정확도 = 0.9228,검증 정확도 = 0.8333
이번에는 최적화 함수를 Adam → AdamW로 바꿔보겠습니다.
그외 패러미터는 동일, epoch는 아예 50회부터 시작합니다.
def train_net(net, train_loader, test_loader, only_fc = True,
optimizer = optim.AdamW, loss_function = nn.CrossEntropyLoss(),
n_iter = 10, device = device):100%|██████████| 23/23 [00:02<00:00, 9.58it/s]
epoch 횟수 = 50, 학습 loss = 0.2289, 학습 정확도 = 0.9171,검증 정확도 = 0.8333
큰 차별점은 없어보입니다.
다시 뒤로 회귀해서, 최적화 함수를 SGD로 바꿔서 사용해보겠습니다.
Learning rate는 0.01로 지정, momentum은 0.9 로 모두 임의설정 입니다.
epoch 50회 입니다.
def train_net(net, train_loader, test_loader, only_fc = True,
optimizer = optim.SGD, loss_function = nn.CrossEntropyLoss(),
n_iter = 10, device = device, momentum = 0.9):
train_losses = []
train_accuracy = []
val_accuracy = []
if only_fc:
optimizer = optimizer(net.fc.parameters(), lr = 0.01)
else:
optimizer = optimizer(net.parameters(), lr = 0.01)lr도 계층마다 각각 언급해줍니다.
100%|██████████| 23/23 [00:02<00:00, 9.51it/s]
epoch 횟수 = 100, 학습 loss = 0.2072, 학습 정확도 = 0.9185,검증 정확도 = 0.8667
현재까지는 큰 유의점이 보이진 않습니다.
test loader의 이미지도 확인해보겠습니다.
# 테스트 데이터
# 브리또 배출(위가 막혀있음)
dataiter = iter(test_loader)
images, labels = next(dataiter)
img = utils.make_grid(images, padding=0)
npimg = img.numpy()
plt.figure(figsize=(20, 14))
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()

좋습니다. 이번엔 타코 휴먼은 없지만, 타코를 그린 그림이 들어가있네요.
필자의 궁금증으로 인해, dropout을 0.01로 추가하고, 최적화 함수로 Adamax를 선정해서
▼다시 학습을 진행시켜 보았습니다.
100회까지 보냈을 때 유의미한 차이가 있을지 확인하기 위함이었습니다.
def train_net(net, train_loader, test_loader, only_fc = True,
optimizer = optim.Adamax, loss_function = nn.CrossEntropyLoss(),
n_iter = 10, device = device, dropout = 0.01):(아래 모델 정의 코드 생략) epoch 1회
100%|██████████| 23/23 [00:02<00:00, 9.27it/s]
epoch 횟수 = 1, 학습 loss = 0.2707, 학습 정확도 = 0.8792,검증 정확도 = 0.8667
epoch 50회
100%|██████████| 23/23 [00:02<00:00, 9.33it/s]
epoch 횟수 = 50, 학습 loss = 0.2074, 학습 정확도 = 0.9129,검증 정확도 = 0.8167
epoch 100회
100%|██████████| 23/23 [00:02<00:00, 9.51it/s]
epoch 횟수 = 100, 학습 loss = 0.2072, 학습 정확도 = 0.9185,검증 정확도 = 0.8667
중간에 98회 학습 정확도 0.9396까지 뛰었으나, 이때 최고점을 찍고 다시 하강하기 시작합니다.
과도한 정확도는 과적합으로도 체크할 수 있기때문에 여기서는 마치겠습니다.
이후 신경망 모델에서도 다양한 시도를 진행해보겠습니다.
'딥러닝 > 개인구현 정리' 카테고리의 다른 글
| [DeepLearning] GAN 모델 활용_CelebA얼굴 이미지 구분_1 (0) | 2023.02.01 |
|---|---|
| [DeepLearning] 이미지 구분 모델_Pokemon 809 세트_ep.2 (0) | 2023.01.31 |
| [DeepLearning] 이미지 구분 모델_Pokemon 809 세트_ep.1 (0) | 2023.01.26 |
| [자연어 처리 학습] 셰익스피어 비극 대본집_중세말투 학습_2 (0) | 2023.01.23 |
| [자연어 처리 학습] 셰익스피어 비극 대본집_중세말투 학습_1 (0) | 2023.01.21 |



