지난 CelebA 데이터셋의 모델 생성에 이어서
더 나아간 GAN 학습 사례를 보겠습니다.
생성자와 판별자 class를 제작하고 celebA의 데이터셋을
2만장만 뽑아 각각 에포크를 한번 돌린 상황이었습니다.
에포크가 높지 않아서인지 이목구비가 뚜렷하게 나오진 않고
형태만 겨우 유지하고 있는 이미지를 보여주고 있습니다.
새로 알아낸 것
문법 착오로 인해서 에포크가 제대로 돌아가지 않았습니다.
EPOCHS = 10
for epoch in range(EPOCHS):
print(f' 에포크 = {epoch+1}')
for image_data_tensor in celeba_dataset:
D.train(image_data_tensor, torch.cuda.FloatTensor([1.0]))
D.train(G.forward(generate_random_seed(100)).detach(), torch.cuda.FloatTensor([0.0]))
G.train(D, generate_random_seed(100), torch.cuda.FloatTensor([1.0]))
pass
pass
실제 EPOCHS = 10
이 부분에서 for문을 들여쓰기 오류로 아래와 같이 진행해서, 지나치게 빨리 끝났고
생성자 생성이 왠만큼 되진 않았던 것으로 예측됩니다.
EPOCHS = 10
for epoch in range(EPOCHS):
print(f' 에포크 = {epoch+1}')
for image_data_tensor in celeba_dataset:
D.train(image_data_tensor, torch.cuda.FloatTensor([1.0]))
D.train(G.forward(generate_random_seed(100)).detach(), torch.cuda.FloatTensor([0.0]))
G.train(D, generate_random_seed(100), torch.cuda.FloatTensor([1.0]))
pass
pass(현재 이미지)
plt.imshow(img, interpolation='none', cmap = 'Reds')
3 x 2 형태의 이미지 배열
f, axarr = plt.subplots(2,3, figsize = (16, 8))
for i in range(2):
for j in range(3):
output = G.forward(generate_random_seed(100))
img = output.detach().cpu().numpy()
axarr[i,j].imshow(img, interpolation = 'none', cmap = 'Reds')
pass
pass
생성자가 만들어낸 이미지를 보면, 모두 유사한 자세와 이목구비의 좌표를
계산하고 있는 것을 알 수 있습니다. 머리스타일이나, 얼굴 색만 조금씩 다릅니다.
counter = 438000
counter = 439000
counter = 440000
CPU times: user 17min 9s, sys: 26.4 s, total: 17min 36s
실제로 10회가량 에포크를 넣어 학습시켰을 때, 상당히 많은 시간이 소요됬습니다.
counter 또한 40만 회를 넘어갑니다.
여기서 생성자와 판별자의 훈련과정상 중요한 점은 LOSS 값이 판별자 하나만
지속적으로 내려가는 것만이 아니라, 생성자와 판별자 모두 LOSS값이 유사하게 수렴해야 한다는 점입니다.
예측하건대 생성자의 이미지마다 인물의 자세나, 이목구비의 좌표, 배경색상도 다양하게 생성할 것입니다.
GAN 모델의 강점은 훈련 데이터의 probability distribution을 기록하고 이를 재현한 데이터를
생성하기 위해 노력한다는 점입니다.
판별자의 loss 함수를 확인했습니다.
D.plot_progress()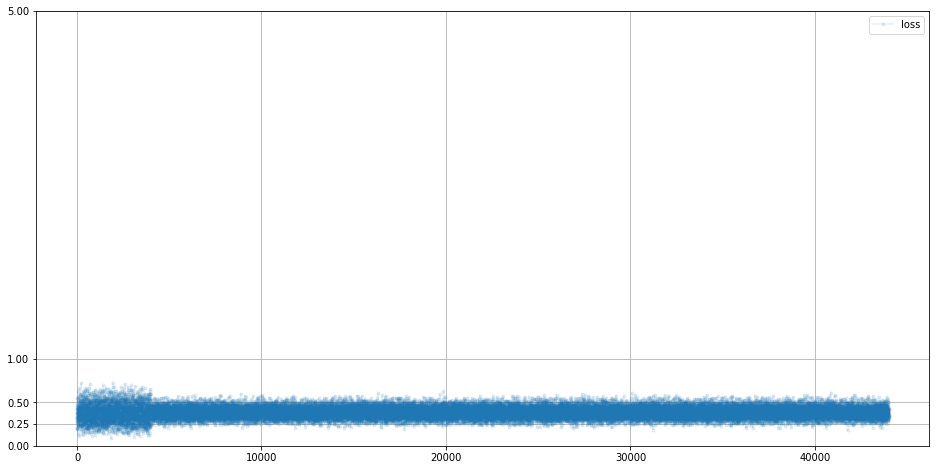
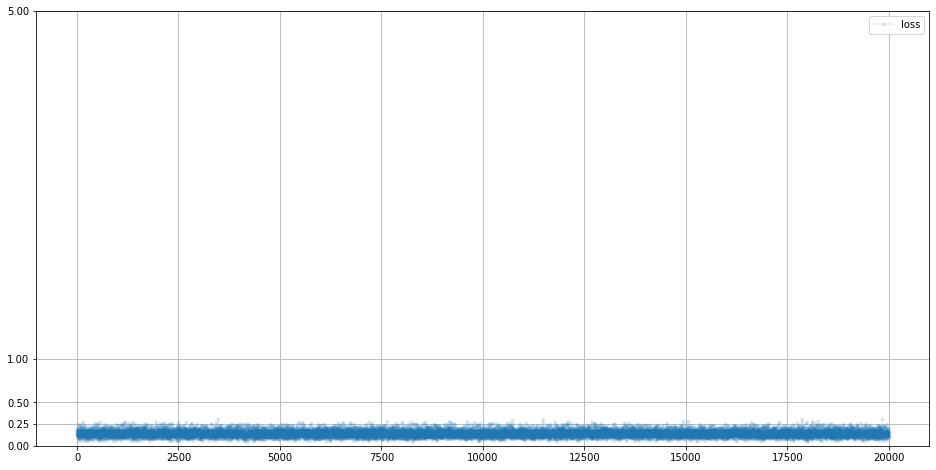
생성자의 loss 함수를 확인해보겠습니다.
G.plot_progress()
2 x 3 서브플롯으로 다시 이미지 조회 시도.
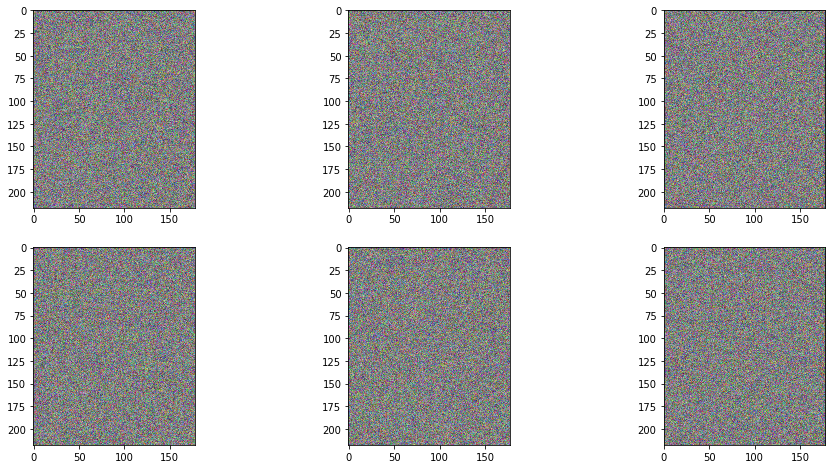
이미지가 너무 과하게 학습된 것일까요?
이제는 판별자가 가짜 이미지를 너무 잘 잡아낸 것일지도 모르겠습니다.
원인을 분석하기 위해 에포크를 2회로 낮추고 다시 진행하겠습니다.
f, axarr = plt.subplots(2,3, figsize = (16, 8))
for i in range(2):
for j in range(3):
output = G.forward(generate_random_seed(100))
img = output.detach().cpu().numpy()
axarr[i,j].imshow(img, interpolation = 'none', cmap = 'Reds')
pass
pass
점점 무서워지네요.
데이터셋 자체를 수정해서 진행해보겠습니다.
# 이미지를 직사각형에서 정사각형으로 crop
def crop_centre(img, new_width, new_height):
height, width, _ = img.shape
startx = width//2 - new_width//2
starty = height//2 - new_height//2
return img[ starty:starty + new_height, startx:startx + new_width, :]
crop하고, 다시 crop_centre를 사용해 img를 자른 데이터셋을 가져와봅니다.
# 자른 이미지를 토대로 데이터셋 소환
class CelebADataset(Dataset):
def __init__(self, file):
self.file_object = h5py.File(file, 'r')
self.dataset = self.file_object['img_align_celeba']
pass
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
if (index >= len(self.dataset)):
raise IndexError()
img = np.array(self.dataset[str(index)+'.jpg'])
img = crop_centre(img, 128, 128)
return torch.cuda.FloatTensor(img).permute(2,0,1).view(1,3,128) / 255.0
def plot_image(self, index):
img = np.array(self.dataset[str(index)+'.jpg'])
img = crop_centre(img, 128, 128)
plt.imshow(img, interpolation = 'nearest')
pass
pass
판별자도 수정합니다.
이전 시간부터 자주 사용했던 Conv2를 통해 합성곱을 이용해 압축이 더 잘되도록 시도해봅시다.
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,256, kernel_size = 8, stride = 2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=8, stride = 2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 3, kernel_size=8, stride = 2),
nn.LeakyReLU(0.2),
View(3*10*10),
nn.Linear(3*10*10, 1),
nn.Sigmoid()
)
self.loss_function = nn.BCELoss()
self.optimiser = torch.optim.Adam(self.parameters(), lr = 0.0001)
self.counter = 0;
self.progress = []
pass
def forward(self, inputs):
return self.model(inputs)
def train(self, inputs, targets):
outputs = self.forward(inputs)
loss = self.loss_function(outputs, targets)
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 1000 == 0):
print("counter = ", self.counter)
pass
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pd.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5, 1.0, 5.0))
pass
pass
생성자도 수정했습니다.
# 생성자 재정의
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(100, 3*11*11),
nn.LeakyReLU(0.2),
View((1, 3, 11, 11)),
nn.ConvTranspose2d(3, 256, kernel_size = 8, stride = 2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256, 256, kernel_size = 8, stride = 2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256, 3, kernel_size = 8, stride = 2, padding = 1),
nn.BatchNorm2d(3),
nn.Sigmoid()
)
# 최적화 함수 Adam으로 수정
self.optimiser = torch.optim.Adam(self.parameters(), lr=0.0001)
self.counter = 0;
self.progress = []
pass
def forward(self, inputs):
return self.model(inputs)
def train(self, D, inputs, targets):
g_output = self.forward(inputs)
d_output = D.forward(g_output)
loss = D.loss_function(d_output, targets)
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pd.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5, 1.0, 5.0))
pass
pass
중요한점은 판별자에서 conv2d를 통해 신경망을 만들었을 경우
다시 압축 해제해줄때 (생성자) conv2d의 Transpose인 역합성곱을 해주어야 한다는 점입니다.
→ConvTranspose2d 사용. = 역합성곱
transpose convolution이 어떤것인지 느낌이 안오는 경우를 위해서, pytorch의 document도 첨부합니다.
ConvTranspose2d — PyTorch 1.13 documentation
ConvTranspose2d — PyTorch 1.13 documentation
Shortcuts
pytorch.org
요약컨대, 입력보다 출력이 커지는 연산입니다.
좋습니다. 이제 부디 잘나오길 기도할 때입니다.
# epoch1회 진행 시 크게 나아진게 없어 2회로 돌렸습니다
epoch 2회 진행했을 경우
# 다시 epoch 시작
%%time
# 2회 진행
EPOCH = 1
D = Discriminator()
G = Generator()
D.to(device)
G.to(device)
for epoch in range(EPOCH+1):
print(f'epoch : {epoch}')
for image_data_tensor in celeba_dataset:
D.train(image_data_tensor, torch.cuda.FloatTensor([1.0]))
D.train(G.forward(generate_random_seed(100)).detach(), torch.cuda.FloatTensor([0.0]))
G.train(D, generate_random_seed(100), torch.cuda.FloatTensor([1.0]))
pass
passcounter = 80000
CPU times: user 29min 55s, sys: 10.6 s, total: 30min 6s
Wall time: 30min 22s
무려 30분이 넘게 걸렸습니다.
판별자 손실 그래프를 띄워봅니다.
# 손실 그래프 확인
D.plot_progress()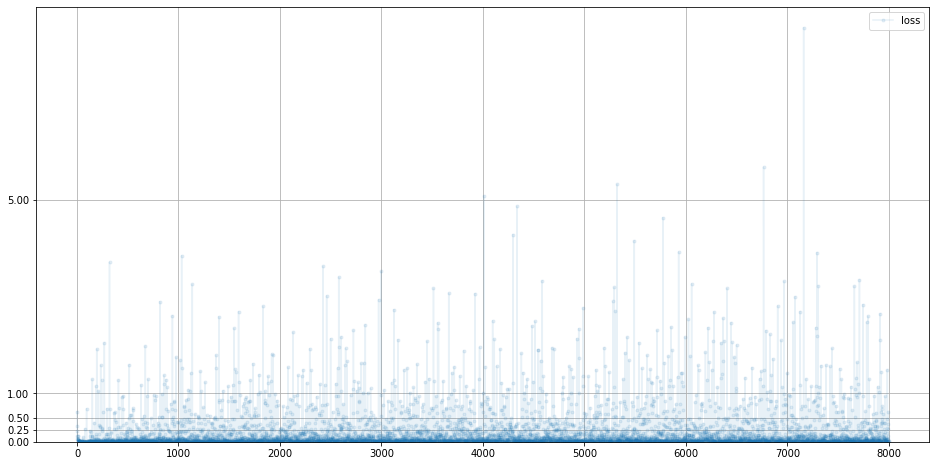
이전과 달리 상당히 loss값이 다양한 것을 볼수있습니다.
이전 crop 이미지를 하기 전의 판별자 loss 그래프
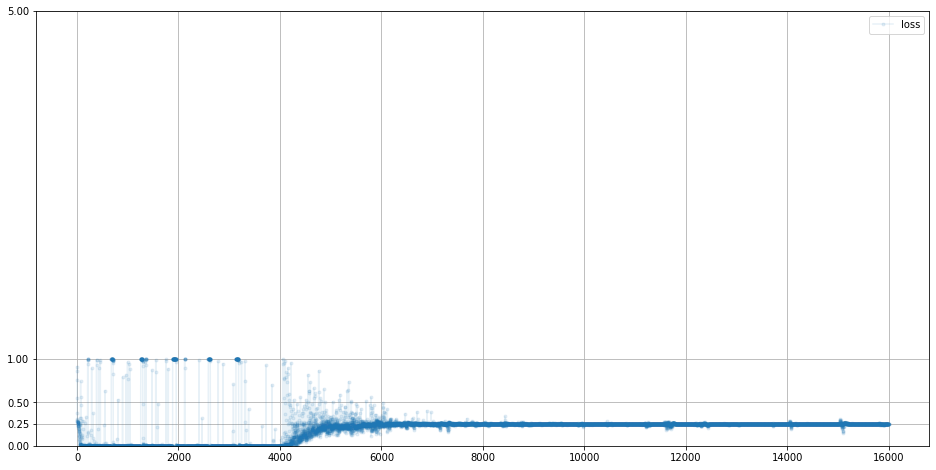
다시 돌아와서, 생성자의 loss 그래프입니다.
G.plot_progress()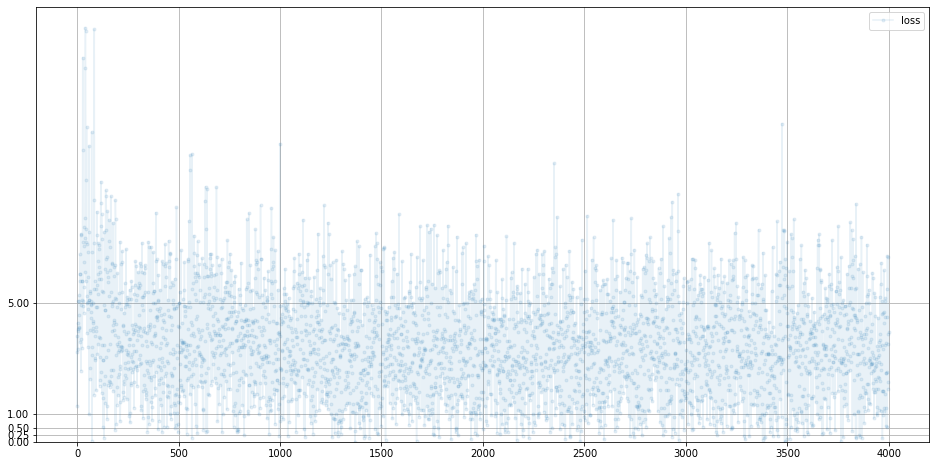
요동치고 있습니다.
마지막으로 생성자가 만들어낸 이미지까지 보겠습니다.
f, axarr = plt.subplots(2,3, figsize = (16, 8))
for i in range(2):
for j in range(3):
output = G.forward(generate_random_seed(100))
img = output.detach().permute(0,2,3,1).view(128, 128, 3).cpu().numpy()
axarr[i,j].imshow(img, interpolation = 'none', cmap = 'Blues')
pass
pass
눈,코,입, 머리까지는 보이긴 했지만 역시 '잘' 만들어졌다고 보긴 어렵습니다.
EPOCH를 확연히 올리거나 신경망을 손봐야 되겠지요.
1) 이미지의 생성자 신경망은 Conv2d와 ConvTranspose2d를 사용하는 것이 응당 나았습니다.
2) 하지만 GPU의 성능 문제로 인해 한번 돌리기 전에 최대한 고려를 많이 해야겠습니다.
- 무료버전의 한계로 인해 GPU 백엔드가 초과하는 딜레마.
'딥러닝 > 개인구현 정리' 카테고리의 다른 글
| [DeepLearning] GAN을 활용한 새로운 산타클로스 얼굴 만들기 feat_Dropout 기법 (0) | 2023.02.12 |
|---|---|
| [DeepLearning] GAN을 활용한 새로운 산타클로스 얼굴 만들기 (0) | 2023.02.09 |
| [DeepLearning] GAN 모델 활용_CelebA얼굴 이미지 구분_1 (0) | 2023.02.01 |
| [DeepLearning] 이미지 구분 모델_Pokemon 809 세트_ep.2 (0) | 2023.01.31 |
| [DeepLearning] 이미지 구분 모델_Pokemon 809 세트_ep.1 (0) | 2023.01.26 |



