이번 시간에는 ADSP의 3과목, <데이터 분석>에서 결코 간과할 수 없는 통계 프로그램인 R의
여러 가지 사용법과 명령어에 대해서 살펴보고자 합니다.
※ 버전이나 해석본에 따라 오류나 오기가 있을 수 있는 점 양해 부탁드립니다.
- 모든 코드는 R을 사용하여 진행했으며 부득이한 경우 이미지 캡처를 사용했습니다

먼저 데이터 분석 툴이자 프로그램인 R(프로그래밍 언어 자체를 뜻하기도 함!)은 개발 당시 널리 쓰이고 있었던 프로그래밍 언어 S를 통해서 구현되었습니다. 데이터 처리 부분은 Scheme이라는 언어로 영감받았습니다.
R을 만든 분들은 로버트 젠틀맨과 로스 이타카라는 연구진으로, 둘다 이름의 시작 철자에 R이 포함되어서 이런 이름이 탄생한 것입니다. 운영체제는 윈도우와 맥, 리눅스 등 다양한 os에도 모두 돌아갑니다.
너무나 감사하게도 오픈 소스로, 완전히 무료! 패키지까지 무료입니다!
다행히도 Python의 문법이나 구현 방식이 많은 부분 유사한 것 같습니다.
아래 문법을 통해 확인해 보겠습니다.
예시 문제 1
다음중 아래의 R 명령문을 수행한 결과에 대한 각 출력 결과가 잘못 연결된 것은 무엇인가?
> x <- seq( 0, 10, 2 )
> y <- rep( c( 1, 3), each = 3)
> z <- paste( 'ba', 'nana' )
> w <- mean( x, na.rm = T )
① x : 0 2 4 6 8 10
② y : 1 1 1 3 3 3
③ z : banana
④ w : 5
z <- paste('ba', 'nana')는 내부적으로 seq '1'가 숨어있기 때문에 ba nana로 반환됩니다.
먼저 행렬부터 진행해보겠습니다.
행렬(matrix)은 모든 데이터프레임의 기본입니다.
1부터 6까지 차례로 증가하는 리스트를 row(행)이 2개인 행렬로 구현해봅니다.
> m1 <- matrix( c(1:6), nrow=2)
> m1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
파이썬과 다른 점은 R로 행렬을 만들 때, 행과 열이 1부터 시작한다는 점입니다.
파이썬은 무조건 0부터 시작했죠?
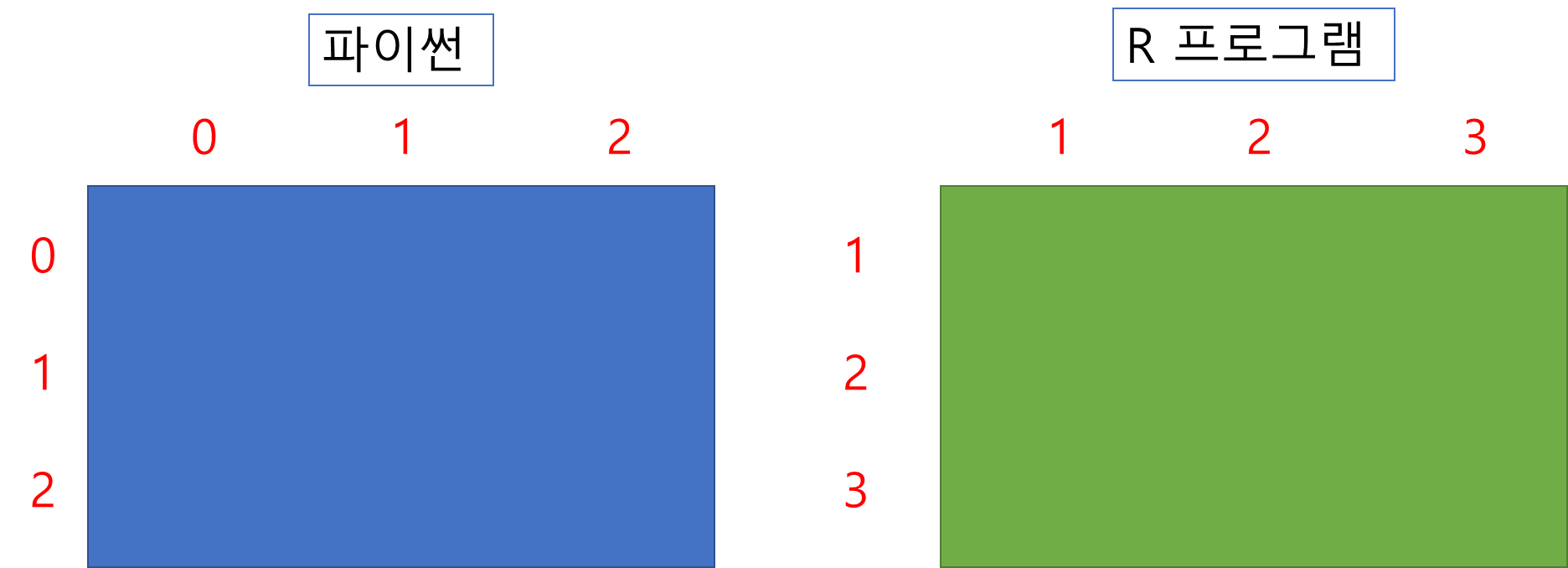
때문에 같은 사이즈의 행렬도 파이썬에서는 [0:2, 0:2] 사이즈가 R에서는 [2,3]으로 동치됩니다.
이부분을 텍스트로만 본다면 약간 헷갈릴 수 있을 것입니다.
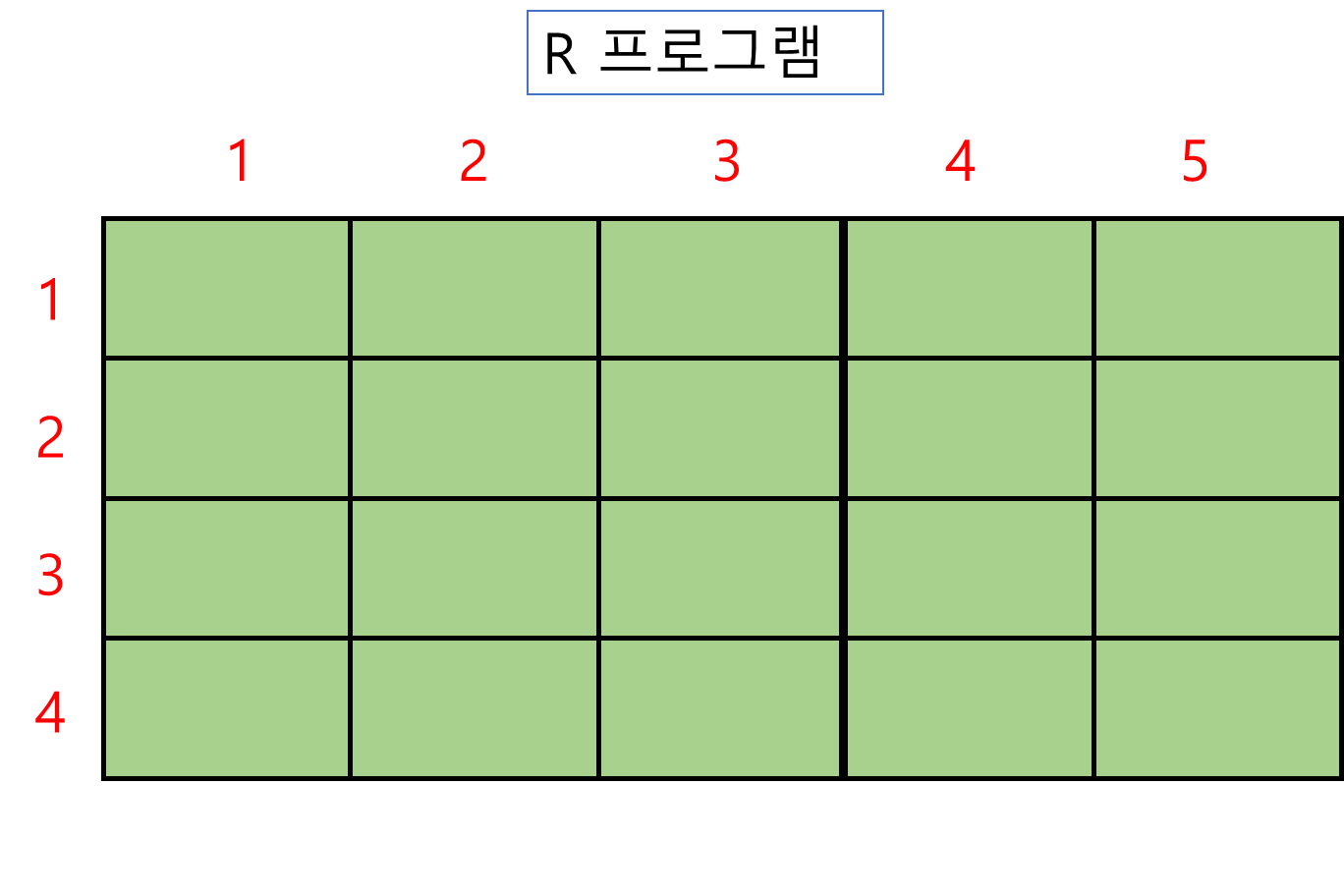
파이썬에서의 [4 x 5] 의 행렬은 어떻게 표현될까요?
array2 = np.arange(1,7)
array3 = np.array([array2, array2, array2, array2, array2])
array3
array([[1, 2, 3, 4, 5, 6],
[1, 2, 3, 4, 5, 6],
[1, 2, 3, 4, 5, 6],
[1, 2, 3, 4, 5, 6],
[1, 2, 3, 4, 5, 6]])
아마 이렇게 표현될 것입니다.
모형으로 나타낸다면 아래와 같겠습니다.

하지만 [4 X 5 ]를 R로 나타낸다면 아래 내용처럼 보일 것입니다.
<- matrix(seq(1,20, 1), nrow=4, ncol =5, byrow = T)
> m2
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
[3,] 11 12 13 14 15
[4,] 16 17 18 19 20
이렇게 행과 열의 숫자가 다릅니다.
byrow 속성은 R이 원래 열을 기준으로 숫자가 하나씩 쌓이지만 이를 True로 설정하여 행을 기준으로 숫자를 쌓이게 하는 것입니다.
아래는 기본적인 R의 내장함수입니다.
rm() : 대입 연산자에 의해 생성된 변수를 삭제합니다.
* a에 1을 대입한 후 rm으로 삭제
> a<-1
> a
[1] 1
> rm(a)
> a
에러: 객체 'a'를 찾을 수 없습니다
paste( ) : 문자열을 이어 붙입니다.
문자열을 붙인 사례
> paste("it's", "a", "paste")
[1] "it's a paste"
ls( ) : 현재 생성된 변수들의 리스트를 보여줍니다.
> ls()
[1] "m1" "m2"
seq() : 시작값, 끝값, 간격으로 수열을 생성합니다.
아래는 1부터 5까지 만드는데, 1씩 상승하는 수열입니다.
> m3 <- seq(1,5,1)
> m3
[1] 1 2 3 4 5
rep() : 주어진 데이터를 일정 횟수만큼 반복합니다.
1을 다섯 번 반복했습니다.
> rep(1,5)
[1] 1 1 1 1 1
print() : 값을 콘솔창에 출력합니다.
이 함수는 완전히 파이선과 같습니다.
> print("print this value in the console window")
[1] "print this value in the console window"
아래는 통계함수 부분입니다.
실제 기출에서는 summary 부분이 자주 등장합니다.
예시 문제2
다음은 분산분석을 수행한 결과다. 결과를 잘못 해석한 것은?

① 4개의 그룹에 대한 평균을 비교하기 위해 수행하였다.
② 전체 데이터의 갯수는 140개이다.
③ 유의수준 5% 내에서 귀무가설을 기각한다.
④ 각각의 4개 그룹의 평균은 모두 다르다고 볼 수 있다.
이 summary만의 정보로는 4개 그룹의 평균이 같은지, 다른지 판단할 수 없습니다.
sum( vector1 ) : 입력된 값의 합을 구합니다.
> m1
[1] 1 2 3 4
> sum(m1)
[1] 10mean( vector1 ) : 입력된 값의 평균을 구합니다.
> m1
[1] 1 2 3 4
> mean(m1)
[1] 2.5median( vector1 ) : 입력된 값의 중앙값을 구합니다.
> m2
[1] 1 2 3 4 5 6 7
> median(m2)
[1] 4var( vector1 ) : 입력된 값의 표본 분산을 구합니다.
> m2
[1] 1 2 3 4 5 6 7
> var(m2)
[1] 4.666667sd( vector1 ) : 입력된 값의 표본 표준편차를 구합니다.
> m2
[1] 1 2 3 4 5 6 7
> (sd(m2))
[1] 2.160247max( vector1 ) : 입력된 값의 최댓값을 구합니다.
> m2
[1] 1 2 3 4 5 6 7
> max(m2)
[1] 7min( vector1 ) : 입력된 값의 최솟값을 구합니다.
> m2
[1] 1 2 3 4 5 6 7
> min(m2)
[1] 1range( vector1 ) : 입력된 값의 최댓값과 최솟값을 구합니다.
> m3
[1] 3 8 2 5 1 0 10 -1
> range(m3)
[1] -1 10summary( vector1 ) : 입력된 값의 요약값을 구합니다. ✅
summary를 보여드리기 위해 몇가지 행렬을 추가합니다.
먼저 m3와 길이가 같은 m4를 선언합니다.
> m4 <- c(1,2,3,4,5,6,7,8)m3와 m4를 행기준으로 결합한 m5 선언
> m5 = rbind(m3,m4)
> m5
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
m3 3 8 2 5 1 0 10 -1
m4 1 2 3 4 5 6 7 8m5를 데이터프레임으로 만든 m6 선언.
> m6 = data.frame(data = m5)
> m6
data.1 data.2 data.3 data.4 data.5 data.6 data.7 data.8
m3 3 8 2 5 1 0 10 -1
m4 1 2 3 4 5 6 7 8이 m6에 대한 요약값을 보여드립니다.
> summary(m6)
data.1 data.2 data.3 data.4 data.5 data.6 data.7 data.8
Min. :1.0 Min. :2.0 Min. :2.00 Min. :4.00 Min. :1 Min. :0.0 Min. : 7.00 Min. :-1.00
1st Qu.:1.5 1st Qu.:3.5 1st Qu.:2.25 1st Qu.:4.25 1st Qu.:2 1st Qu.:1.5 1st Qu.: 7.75 1st Qu.: 1.25
Median :2.0 Median :5.0 Median :2.50 Median :4.50 Median :3 Median :3.0 Median : 8.50 Median : 3.50
Mean :2.0 Mean :5.0 Mean :2.50 Mean :4.50 Mean :3 Mean :3.0 Mean : 8.50 Mean : 3.50
3rd Qu.:2.5 3rd Qu.:6.5 3rd Qu.:2.75 3rd Qu.:4.75 3rd Qu.:4 3rd Qu.:4.5 3rd Qu.: 9.25 3rd Qu.: 5.75
Max. :3.0 Max. :8.0 Max. :3.00 Max. :5.00 Max. :5 Max. :6.0 Max. :10.00 Max. : 8.00
추가적으로, 마침 필자의 하드에 있는 타이타닉 데이터셋 csv도 찾아보겠습니다.
> titanic = read.csv("C:\myPyCode\data\Titanic\train.csv")> head(titanic)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
1 1 0 3 Braund, Mr. Owen Harris male 22 1 0 A/5 21171 7.2500 S
2 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0 PC 17599 71.2833 C85 C
3 3 1 3 Heikkinen, Miss. Laina female 26 0 0 STON/O2. 3101282 7.9250 S
4 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0 113803 53.1000 C123 S
5 5 0 3 Allen, Mr. William Henry male 35 0 0 373450 8.0500 S
6 6 0 3 Moran, Mr. James male NA 0 0 330877 8.4583 Q
summary로 표현합니다.
최솟값, 1쿼터의 값, 중앙값, 평균, 3쿼터의 값, 최댓값, 결측치까지 나타냅니다.
> summary(titanic)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare
Min. : 1.0 Min. :0.0000 Min. :1.000 Length:891 Length:891 Min. : 0.42 Min. :0.000 Min. :0.0000 Length:891 Min. : 0.00
1st Qu.:223.5 1st Qu.:0.0000 1st Qu.:2.000 Class :character Class :character 1st Qu.:20.12 1st Qu.:0.000 1st Qu.:0.0000 Class :character 1st Qu.: 7.91
Median :446.0 Median :0.0000 Median :3.000 Mode :character Mode :character Median :28.00 Median :0.000 Median :0.0000 Mode :character Median : 14.45
Mean :446.0 Mean :0.3838 Mean :2.309 Mean :29.70 Mean :0.523 Mean :0.3816 Mean : 32.20
3rd Qu.:668.5 3rd Qu.:1.0000 3rd Qu.:3.000 3rd Qu.:38.00 3rd Qu.:1.000 3rd Qu.:0.0000 3rd Qu.: 31.00
Max. :891.0 Max. :1.0000 Max. :3.000 Max. :80.00 Max. :8.000 Max. :6.0000 Max. :512.33
NA's :177
Cabin Embarked
Length:891 Length:891
Class :character Class :character
Mode :character Mode :character
추가 참조사항
skewness, kurtosis를 확인하기 위해서는 패키지를 설치해야 합니다.
현재 cran mirror를 설정하여 다운받으려고 하나, 한국 서버에서는 오류로 인해 다운로드가 되지 않습니다.
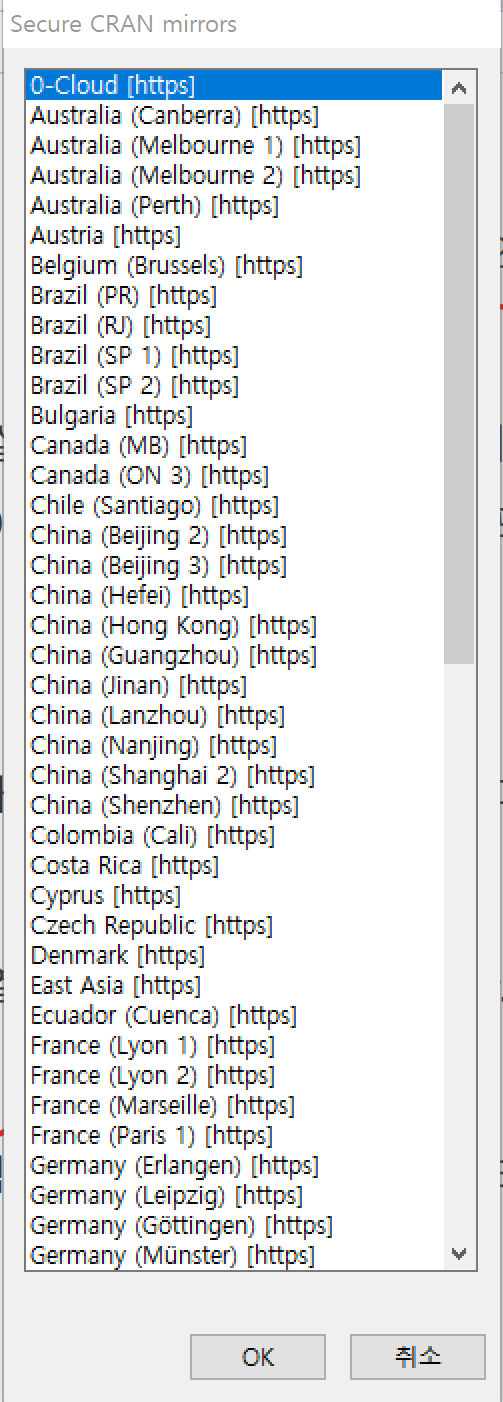
적절하게 브라질 서버나 오스트레일리아 서버 등 보이는 서버를 아무거나 체크해줍니다.
> install.packages("fBasics")
fBasics를 다운받아줍니다. 아래 메세지가 떠야 완료된 것입니다.
패키지 ‘timeDate’를 성공적으로 압축해제하였고 MD5 sums 이 확인되었습니다
패키지 ‘timeSeries’를 성공적으로 압축해제하였고 MD5 sums 이 확인되었습니다
패키지 ‘gss’를 성공적으로 압축해제하였고 MD5 sums 이 확인되었습니다
패키지 ‘stabledist’를 성공적으로 압축해제하였고 MD5 sums 이 확인되었습니다
패키지 ‘fBasics’를 성공적으로 압축해제하였고 MD5 su라이브러리를 불러와줍니다.
> library(Fbasics)skewness( vector1 ) : 입력된 값의 왜도를 구합니다.
> m6
data.1 data.2 data.3 data.4 data.5 data.6 data.7 data.8
m3 3 8 2 5 1 0 10 -1
m4 1 2 3 4 5 6 7 8
> skewness(m6)
data.1 data.2 data.3 data.4 data.5 data.6 data.7 data.8
0 0 0 0 0 0 0 0
attr(,"method")
[1] "moment"kurtosis( vector1 ) : 입력된 값의 첨도를 구합니다.
> m6
data.1 data.2 data.3 data.4 data.5 data.6 data.7 data.8
m3 3 8 2 5 1 0 10 -1
m4 1 2 3 4 5 6 7 8
> kurtosis(m6)
data.1 data.2 data.3 data.4 data.5 data.6 data.7 data.8
-2.75 -2.75 -2.75 -2.75 -2.75 -2.75 -2.75 -2.75
attr(,"method")
[1] "excess"skewness와 kurtorsis는 실제로 영어로 왜도, 첨도를 의미합니다.

마찬가지로 이미 쓰여있는 배열에 대해 인덱싱도 가능합니다.
m1 행렬을 다시 소환해보겠습니다.
> m1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
m1의 2행 1열 소환(인덱싱)입니다.
> m1[2]
[1] 2
m1의 1열 2행 인덱싱입니다.
> m1[1,2]
[1] 3
좀더 크게 잘라보겠습니다.
이부분에서도 파이썬에서의 차이점이 생깁니다.
배열을 2개 이상 잘라낼 경우, 미리 행의 이름과 열의 이름을 지정해주지 않으면 오류가 나타나게 됩니다.
열 이름을 지정하지 않을 경우
> m1[ , '[,1]']
m1[, "[,1]"]에서 다음과 같은 에러가 발생했습니다:no 'dimnames' attribute for array
열 이름을 지정한 경우
> m1[,'a1']
[1] 1 2
1열 전부입니다.
R에서 열 값은 실제로는 세로줄 이지만 가로줄로 표시됩니다.
> m1[,'a1']
b1 b2
1 2
열 이름 짓기
열 이름은 아래 명령어로 지정할 수 있습니다.
> colnames(m1) <- c('a1','a2','a3')
> m1
a1 a2 a3
[1,] 1 3 5
[2,] 2 4 6
행 이름을 지정하지 않은 경우
허용 범위를 벗어난 것으로 밝혀집니다.
> m1['[,1]', 'a1']
m1["[,1]", "a1"]에서 다음과 같은 에러가 발생했습니다:첨자의 허용 범위를 벗어났습니다
행 이름을 지정한 경우
1행 1열입니다.
> m1['b1','a1']
[1] 1
1행 모두입니다.
a1 a2 a3
1 3 5
행 이름 짓기
행 이름또한 rownames로 지을 수 있답니다.
> rownames(m1) <- c('b1','b2')
> m1
a1 a2 a3
b1 1 3 5
b2 2 4 6
데이터프레임에서 원하는 열 전체를 뽑을 때 $ 기호를 사용할 수도 있습니다.
> df <- data.frame(m1, m2)
> df
a1 a2 a3 X1 X2 X3 X4 X5
1 1 3 5 1 2 3 4 5
2 2 4 6 6 7 8 9 10
3 1 3 5 11 12 13 14 15
4 2 4 6 16 17 18 19 20
$ 사용
a1 열만 호출입니다.
> df$a1
[1] 1 2 1 2
데이터를 결합하는 부분은 파이썬과 비교했을 때 쉽게 이해되진 않는 과정입니다.
대표적으로 행을 기준으로 결합하는 rbind와 열을 기준으로 결합하는 cbind가 대표적입니다.
m1, m2를 다시 정의해보겠습니다.
m1 <- c(1,2,3,4,5)
m2 <- c(1,2,3,4,5)
rbind (vector1, vector2)
rbind를 사용한 경우입니다. 행들이 입력한 것들만큼 늘어납니다.
> rbind(m1, m2)
[,1] [,2] [,3] [,4] [,5]
m1 1 2 3 4 5
m2 1 2 3 4 5
이렇게 세로방향으로 합쳐지는 것을 볼 수 있습니다.
열은 자동으로 생성되네요.
cbind (vector1, vector2)
cbind를 사용한 경우입니다. 이제는 열이 입력한 것들만큼 늘어납니다. ✔
cbind(m1,m2)
m1 m2
[1,] 1 1
[2,] 2 2
[3,] 3 3
[4,] 4 4
[5,] 5 5
좋습니다. 하지만 m1, m2 배열의 수가 같지 않으면 어떻게 될까요?
> m1 <- c(1,2,3,4)
> m2 <- c(1,2,3,4,5)
> cbind(m1,m2)
m1 m2
[1,] 1 1
[2,] 2 2
[3,] 3 3
[4,] 4 4
[5,] 1 5
경고메시지(들):
cbind(m1, m2)에서:
number of rows of result is not a multiple of vector length (arg 1)
이렇게 number of rows of result is not a multiple of vector length (arg 1) 오류가 도출되게 됩니다.
하지만 억지로 만들어주긴 하는데요.
재사용 규칙 ; 벡터의 길이가 달라도 연산이 가능하다. 데이터가 적은 벡터의 데이터가 재활용됨.
이 재사용 규칙때문에 만들어주긴 합니다.
m1 m2
[1,] 1 1
[2,] 2 2
[3,] 3 3
[4,] 4 4
[5,] 1 5
다만, 1,2,3,4 다음이 없기때문에 가장 첫번째 순서에 있던 데이터를 호출하여 가져오게 됩니다.
아래는 R에서 확인되는 약간 문법이 다른 문자 연산들 입니다.
여러가지 문자 연산
tolower : 주어진 문자열을 소문자로 바꿉니다.
> c1
[1] "abc" "ABC" "BD" "가나다" "123"
> tolower(c1)
[1] "abc" "abc" "bd" "가나다" "12toupper : 주어진 문자열을 대문자로 바꿉니다.
> c1
[1] "abc" "ABC" "BD" "가나다" "123"
> toupper(c1)
[1] "ABC" "ABC" "BD" "가나다" "123nchar : 주어진 문자열의 길이를 구합니다.
> c1
[1] "abc" "ABC" "BD" "가나다" "123"
> nchar(c1)
[1] 3 3 2 3 3substr : 문자열의 일부분을 추출합니다.
> c2 <- ("이 문자열을 보겠습니다.!")
> c2
[1] "이 문자열을 보겠습니다.!"
> substr(c2, 1, 8)
[1] "이 문자열을strsplit : 문자열을 구분자로 나누어 쪼개줍니다.
> c2
[1] "이 문자열을 보겠습니다.!"
> strsplit(c2, "을")
[[1]]
[1] "이 문자열" " 보겠습니다.!"grepl : 문자열에 주어진 문자가 있는지 확인합니다. (bool 값 입니다)
> c2
[1] "이 문자열을 보겠습니다.!"
> grepl("다", c2)
[1] TRUEgsub : 문자열의 일부분을 다른 문자로 대체합니다.
> c2
[1] "이 문자열을 보겠습니다.!"
> gsub("이", "저", c2)
[1] "저 문자열을 보겠습니다.!"이상입니다.
이 이후에도 더 다양한 ADSP 빈출 개념들을 다루어 보겠습니다.
'필기정리 > 스터디노트' 카테고리의 다른 글
| [ADSP] 2023년도 1회 (36회차) ADSP 시험 복기 및 후기 (0) | 2023.02.26 |
|---|---|
| [ADSP] 데이터 웨어하우스와 마트에 관하여 (0) | 2023.02.24 |
| [ADSP] 데이터 분석기획 개념 - 데이터 거버넌스에 대하여 (0) | 2023.02.23 |
| [ADSP] 시계열 분석 - 정상성 가정에 대하여 (0) | 2023.02.20 |



