오랜만에 이미지 탐지에 대한 논문 탐구를 진행합니다.
지난 시간에는 YOLOv 모델들을 차례로 살펴보았지요?
이번 시간에는 시간을 거슬러 올라가 과거의 모델을 되짚어 보겠습니다.
바로 Faster R-CNN 입니다
Faster R-CNN은 이미지와 관련된 지난 논문 분석에서 살펴보았던 YOLOv1, YOLOv2의 발견으로부터 1년전에 제시된 모델 입니다. YOLOv2를 설명할 때, multitask 에 대한 방법론 부분에서도 Faster R-CNN에 대한 언급이 잠깐 나온 바 있었네요.
[Deep Learning] YOLOP v2 / 더 향상된 욜로 모델! - 논문리뷰 (tistory.com)

이미지 출처 : Faster R-CNN: Down the rabbit hole of modern object detection | Tryolabs
Faster R-CNN: Down the rabbit hole of modern object detection
In this post, I'll explain the architecture of Faster R-CNN, starting with a high level overview, and then go over the details for each of the components. You'll be introduced to base networks, anchors as well as the region proposal network.
tryolabs.com
이번에는 독특하게도 Microsoft research asia에서 제시된 기술입니다. 찾아보니 중국 베이징에 본신을 두고 있는 월-클 연구소였네요. 역시나 본문에서 소개하는 기술 이외에도 ResNetXt, Deep Image Prior, DSSM, Conditional GAN 등 딥러닝&이미지 처리 분야에서 혁신적인 기술들을 내놓고 있습니다. 물론 이미 많은 단체에서 투자에 힘쓰고 있지만, 한국에서도 이미지 탐지나 자연어 처리 분야와 관련해서 이러한 세계적 기업과 어깨를 나란히 할 수 있는 성과가 나오면 좋겠습니다.
Artificial Intelligence research at Microsoft aims to enrich our experiences
Artificial Intelligence research at Microsoft aims to enrich our experiences
Microsoft AI Research is creating artificial intelligence machines that complement human reasoning to augment and enrich our experience and competencies.
www.microsoft.com
# 중요 개념 : Residual Proposal Network(RPN), Translation-invariant Anchor, Fast R-CNN
서론. 무엇이 영향을 주었는가
본 연구가 발표될 당시(2015년)의 객체 탐지 기술은 region proposal 기법과 region-based convolutional neural network(R-CNN)의 탄생으로 인해 한 발자국 진보가 이루어졌습니다. region에 기반을 둔 CNN은 처음 개발될 때, 연산 cost가 많이 들었지만 SPPnet, Fast R-CNN에서의 모델 구조에서 convolution across proposal을 공유함으로서 대폭 감소되었습니다.
출처 : SPPNet — Organize everything I know documentation (oi.readthedocs.io)
용어 확인 : proposal
여기서 proposal(region proposal)이란 객체가 존재할 가능성이 높은 영역들을 의미합니다. 예를 들어, 이미지에서 자동차를 검출하려면, 자동차의 일부분이 포함된 이미지 영역을 "proposal"로 생성할 수 있습니다. 이후, 이 영역에서 객체를 검출하고 분류할 수 있습니다.
딥러닝 분야에서 proposal은 객체 탐지를 위한 중요한 요소 중 하나이며, 높은 성능을 위한다면 정확하고 효율적인 proposal 생성을 고민하는 것이 필요합니다.
※ 일상적으로 proposal의 의미가 "제안서, 신청서" , "제안" 의 의미가 강해서 따로 서술했습니다.
이 당시의 최신 버전의 모델인 Fast R-CNN은 매우 깊은 신경망을 사용하여 거의 실시간 속도를 달성하지만, 이는 proposal에 소요되는 시간을 무시한 상태에서 측정한 것입니다. 이제는 proposal이 최첨단 탐지 시스템에서 실행 시간의 병목 구간(bottleneck)이 되고 있습니다.
Region proposal 방법은 보통 cost가 적게 드는 특징과 경제적인 추론(economical inference) 체계에 의존합니다. 가장 인기있는 방법인 Selective Search는 공학적으로 만들어진 저수준 기능에 기반하여, 초점이 맞춰진 superpixel을 greedy한 형태로 병합합니다. 하지만 Fast R-CNN과 비교한다면 Selective Search는 뭐 엄청나게 빠르진 않습니다. CPU 활용시 이미지 하나 당 2초의 시간이 소요되기 때문입니다. EdgeBox라는 모델도 있습니다만, 이미지 하나 당 0.2초가 소요되며 탐지 신경망과 동일한 실행 시간이 걸립니다.
[참조] Edgebox?
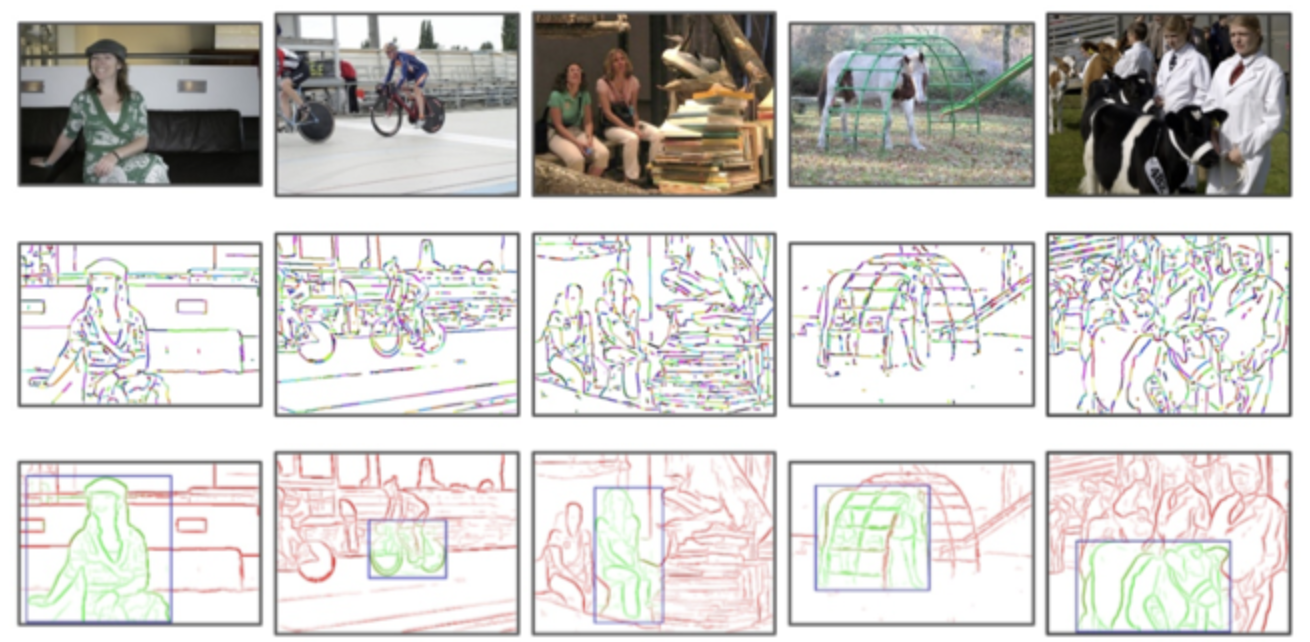
출처 : Edge Boxes (엣지 박스) (donghwa-kim.github.io)
엣지 박스는 이미지 처리의 객체 탐지 알고리즘 중 하나로, 이미지에서 목표로 하는 객체가 있을 가능성을 빠르게 찾기 위해 사용됩니다. 이를 위해서 이미지의 가장자리(귀퉁이)를 탐지하고, 가장자리들이 모여있는 박스(edge box)를 찾습니다.
이미지에서 가장자리는 이미지 픽셀의 밝기 값 (gradient)를 구한 후, 기울기 값이 큰 지점을 찾아내는 방식으로 구할 수 있습니다. 이렇게 찾아진 가장자리들은 오브젝트가 위치할 가능성이 높은 지역들입니다.
이러한 가장자리들을 활용하여, 이미지 전체에 대해 가장 높은 가장자리 밀도(Edge Density)를 가진 지역을 찾아냅니다. 이 지역은 오브젝트가 위치할 가능성이 높은 곳으로 판단됩니다. 그리고 이 지역을 중심으로 다양한 크기와 비율의 박스들을 생성하고, 이 중에서 오브젝트가 있을 가능성이 가장 높은 박스를 선택합니다.
더 깊게 들어가며
본 페이퍼에서는 DNN을 사용해서 proposal 영역을 계산하면 계산 비용이 거의 없는 해결책을 제시하려 했습니다. 이를 위해, 최신의 객체 탐지 신경망(object detection network)과 convolution layer를 공유하는 Region Proposal Network를 소개합니다. 이 기법은 테스트 시 shared convolution을 사용해서, proposal 영역을 계산하는데 드는 비용이 작아지는 장점이 있었습니다.
Faster R-CNN의 개발진들은 region-based detector에서 사용되는 convolutional feature map(컨볼루션 피쳐 맵)은 region proposal 생성에도 사용될 수 있다는 것을 알아내었습니다. 이러한 합성곱 피쳐 맵 위에 컨볼루션 레이어를 추가하여, 정해진 그리드에서 각 위치마다 region bound(존재할 가능성이 높은 영역의 경계)와 objectness score(객체가 존재할 가능성)를 동시에 회귀하는 Region proposal network를 구성합니다. (이하 RPN) 이 신경망은 fully convolutional network(FCN)의 한 종류이며, 탐지 proposal 생성을 위해 end-to-end 형태로 훈련될 수 있습니다.
즉 RPN을 왜 쓰느냐. 간단합니다. RPN은 기존의 Region proposal 생성 알고리즘보다 더 효과적으로 region proposal을 만들기 때문이에요.
RPN 기법은 다양한 크기와 가로x세로 비율(aspect ratio. 이하 종횡비)을 갖는 객체들을 효율적으로 탐지하기 위해서 설계되었습니다.
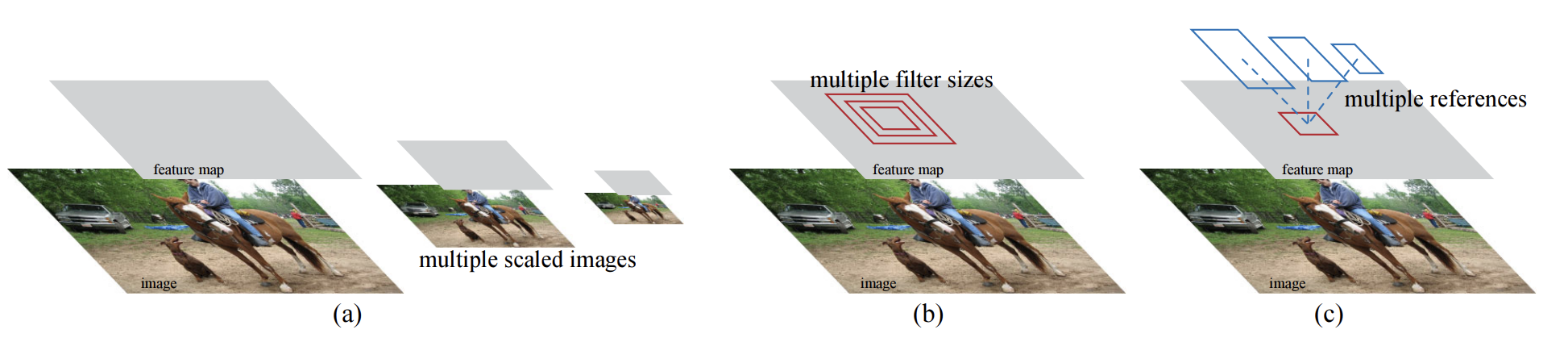
이전까지의 방법들은 pyramids of image나 pyramids of filter를 사용하는 반면, Faster R-CNN에서는 "Anchor box" 기법을 도입합니다. 위 기법을 통해 다양한 크기와 비율을 가진 객체를 참조합니다.
이때
(아래 내용에서 설명함)
이 방식은 pyramid of regression reference(회귀 레퍼런스 피라미드)라고 볼 수 있으며, 이미지나 필터를 다양한 크기와 비율로 열거하는 방식을 사용하지 않아도 된다고 합니다. 이 기법은 single-scale 이미지를 사용해서 학습하고 테스트합니다. 물론 이것 또한 실행 속도를 높이는 장점이 있습니다.
여기서는 RPN과 Fast R-CNN 객체 탐지 신경망을 통합하기 위해서 아래 방법을 넣었습니다.
(1) region proposal 작업을 fine-tuning합니다
(2) 그러고 proposal은 고정한 채 객체 탐지를 위한 파인 튜닝을 번갈아 진행합니다.
이 방법은 더 빨리 수렴되며, 두 작업 모두에서 공유되는 합성곱 피쳐가 있는 통합된 신경망을 생성합니다. 이 방법을 통해 더욱 정확한 객체 탐지가 가능해집니다.
여기서는 RPN이 잘 돌아가는지 확인하기 위해 PASCAL VOC detection benchmark도 테스트하고, MS COCO 데이터셋도 사용해서 테스트 했습니다. → Selective search보다 계산 부담을 줄였고, 학습 속도도 높였습니다. (속도 향상에 대한 문단을 요약했습니다)
관련된 기법 소개
- 여기서는 필자가 미리 확인했어야 할 R-CNN의 흐름에 대해서 다시 언급하는 부분입니다.
Object proposal(객체 추정)

출처 : Generating Object Proposals | pdollar (wordpress.com)
여기서부터 이 용어를 한글로 번역해야 할지, 원문의 어감을 살리기 위해서 그대로 읽어야 할지 난감해지기 시작하는데요. 그만큼 Object proposal은 R-CNN 계열의 주축이 되는 기법이 아닐 수 없습니다. 일단 그대로 진행합니다.
Object proposal을 위해 사용된 방법은 super-pixel(슈퍼 픽셀), Selective search(선택적 탐색), Sliding window(슬라이딩 윈도우), Edgebox 등이 있습니다. Edgebox는 필자가 방금 설명했고, 그 외에는 참조 링크를 확인하면 좋을 것 같습니다.
따로 눈여겨 볼 점은 위에서도 언급했고, 이제 R-CNN 기법의 차례입니다.
객체탐지를 위한 심층 신경망(R-CNN을 말합니다)
R-CNN : 요약
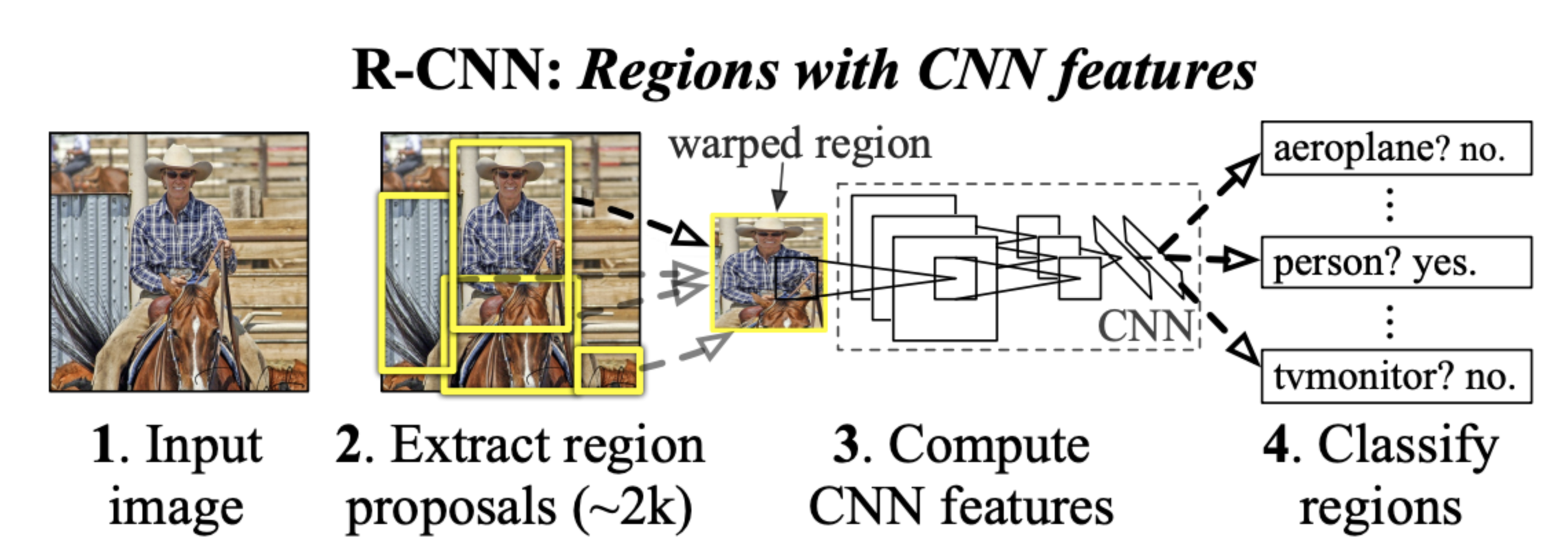
출처 : R-CNN 발표논문. [1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation (arxiv.org)
일반적으로 객체의 위치를 알아맞추려고 할때, 객체를 먼저 보지 않고, 후보들을 뽑아보는 방법입니다.
R-CNN은 물체가 존재할 것으로 예상되는 후보 영역(region proposal)을 먼저 생성한 다음, 각 후보 영역에서 CNN을 사용해서 객체의 유뮤와 객체의 클래스를 예측합니다. 이때 사용되는 것이 앞에서 언급한 선택적 탐색입니다.
- 이 방법은 먼저 이미지를 여러가지 방법으로 분할한 다음, 이 영역을 하나씩 결합하여 후보 영역을 생성합니다. 이렇게 생성한 후보 영역에서 CNN을 사용하여 객체를 검출합니다. 이때 CNN은 각 후보 영역에서 고정된 크기의 이미지 패치를 추출하고, 이 패치를 input으로 사용하여 객체 탐지를 수행합니다.
R-CNN방법은 CNN을 끝까지 학습하여 proposal region을 object 카테고리 혹은 배경으로 분류합니다. (바운딩 박스 regression을 제외하고) R-CNN은 주로 분류기(Classifier)로 작용하여, 객체 경계(bound)를 예측하지 않습니다.
정리 : Overfeat

출처 : Overfeat 원논문. [1312.6229] OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks (arxiv.org)
Overfeat 기법에서는 fully connection layer가 학습되어 단일 객체를 가정한 localization(로컬라이제이션) 작업에서 box coordinate를 예측하도록 학습합니다. 그 후 fully-connected layer(이하 FC)를 컨볼루션 레이어로 변환하여, 다중 클래스 specific object를 탐지합니다.
추가정리 : Multibox 기법
출처 : [1312.2249] Scalable Object Detection using Deep Neural Networks (arxiv.org)

Multibox는 에서 제시된 여러 클래스에 대해 예측하는 다중 박스(multiple) 모델을 뜻합니다. Input 이미지에서 객체가 존재할 가능성이 높은 영역(proposal region)을 생성하고, 이러한 제안된 영역에 대해 class-agnostic box(클래스-비특정 박스)를 동시에 예측합니다. * 클래스-비특정 박스는 클래스 정보를 고려하지 않고, 단순히 바운딩 박스 좌표를 예측하는 구조입니다.
이 모델은 입력이미지를 여러개의 큰 image crop(224 x 244 등)으로 나누어 처리합니다. 각 이미지 크롭에 대해서 multibox 신경망이 적용되며, 각 영역마다 multi class agnostic box를 예측합니다. 이렇게 예측된 박스들은 후속 분류를 위한 proposal region으로 사용됩니다. Overfeat와 달리, multi class agnostic box를 예측하여 단일 박스 방식(Single-box)를 일반화 하는 것이 큰 장점입니다.
MultiBox 기법에서는 마지막 FC가 여러개의 class-agnostic box를 동시에 예측하는 Single-box를 일반화 합니다. 이러한 클래스 비특정 박스는 R-CNN에서 proposal로 사용합니다. 멀티박스 proposal 신경망은 단일 이미지 크롭이나 다수의 큰 이미지 크롭에서 사용되며, Faster R-CNN의 fully convolutional Schema와는 다른 방향입니다. 멀티박스는 proposal 및 detection 신경망 사이에서 feature를 공유하지 않습니다.
최근 연구에서 Shared computation of convolution(공유된 컨볼루션 연산)은 효율적이면서 정확한 시각적 인식을 위해 소개되고 있습니다. Overfeat에 대한 논문에서 classfication, localization, detection을 위해, 이미지 피라미드에서 컨볼루션 피쳐(convolutional feature)를 계산합니다. 공유된 컨볼루션 피쳐 맵(shared convolutional feature map)에 대한 Adaptively-sized pooling은 효율적인 region-based 객체 탐지와 semantic segmantation(시멘틱 세그먼테이션)을 위해서 개발되었습니다. Fast R-CNN은 Shared convolution feature에서 end-to-end detection train을 가능하게 하며, 높은 정확도와 속도를 보여줍니다.
Faster R-CNN의 구조를 봅니다
이제 Faster R-CNN의 형태입니다. 아래의 두 개의 모듈로 구성됩니다.
< 1 > 영역을 proposal하는 deep fully convolution 신경망
< 2 > proposal된 영역을 사용하는 Fast R-CNN detector
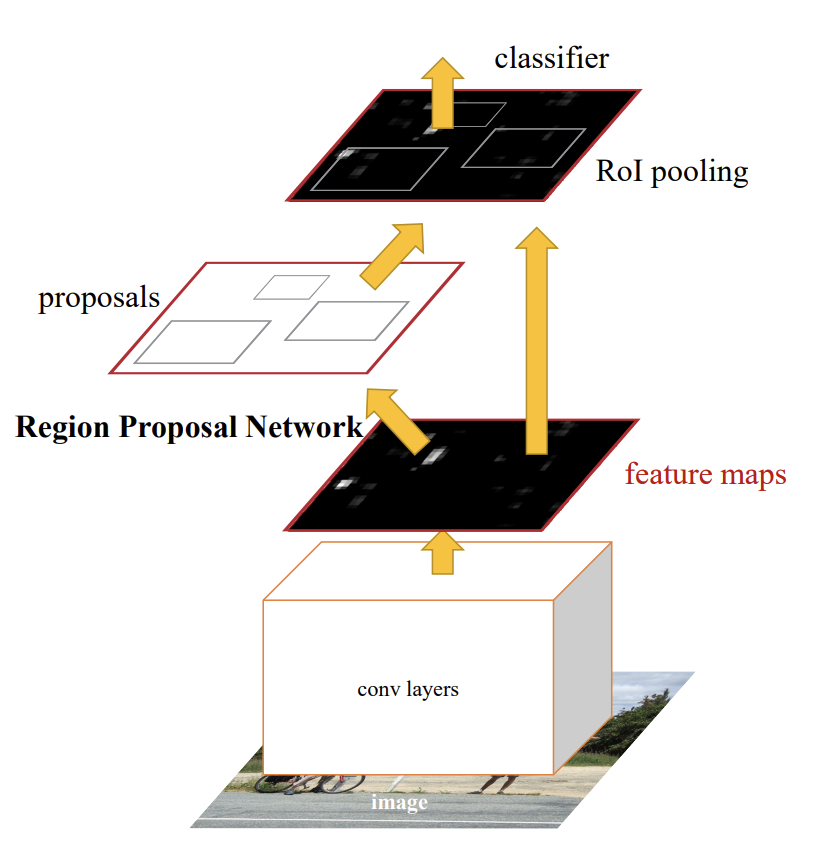
(RPN 모듈은 Fast R-CNN이 어디를 보아야 하는지 알려주는 역할을 합니다.
이 형태가 바로 객체 탐지를 위한 단일 통합 네트워크(single, unifed network)입니다.
※ single과 unifed를 강조하는 의미에서 따로 띄어준 것 같습니다.
여기서는 Attention(어텐션 기법)을 R-CNN이 집중해야 할 위치를 알려주는 데 사용했습니다.
자연어 관련해서 seq2seq에도 등장하는 어텐션 메커니즘을 사용했는데요. 자연어 처리에서만 사용되는 모델이 아닌, 이미지 처리에서도 사용되는 점 알고 있어야 되겠습니다.
Attention-Based Models for Speech Recognition
Recurrent sequence generators conditioned on input data through an attention mechanism have recently shown very good performance on a range of tasks in- cluding machine translation, handwriting synthesis and image caption gen- eration. We extend the attent
arxiv.org
Attention 메커니즘 요약
인공 신경망이 입력된 데이터 중에서 유독, 중요한 부분에 더 집중할 수 있도록 하는 기법이었죠? 일반적으로 딥러닝 모델은 input의 모든 부분을 동등하게 취급해서 처리하지만, 어텐션 메커니즘을 사용하면 모델이 입력된 데이터 중에서 특정 부분에 더 많은 가중치를 두고 처리할 수 있습니다.
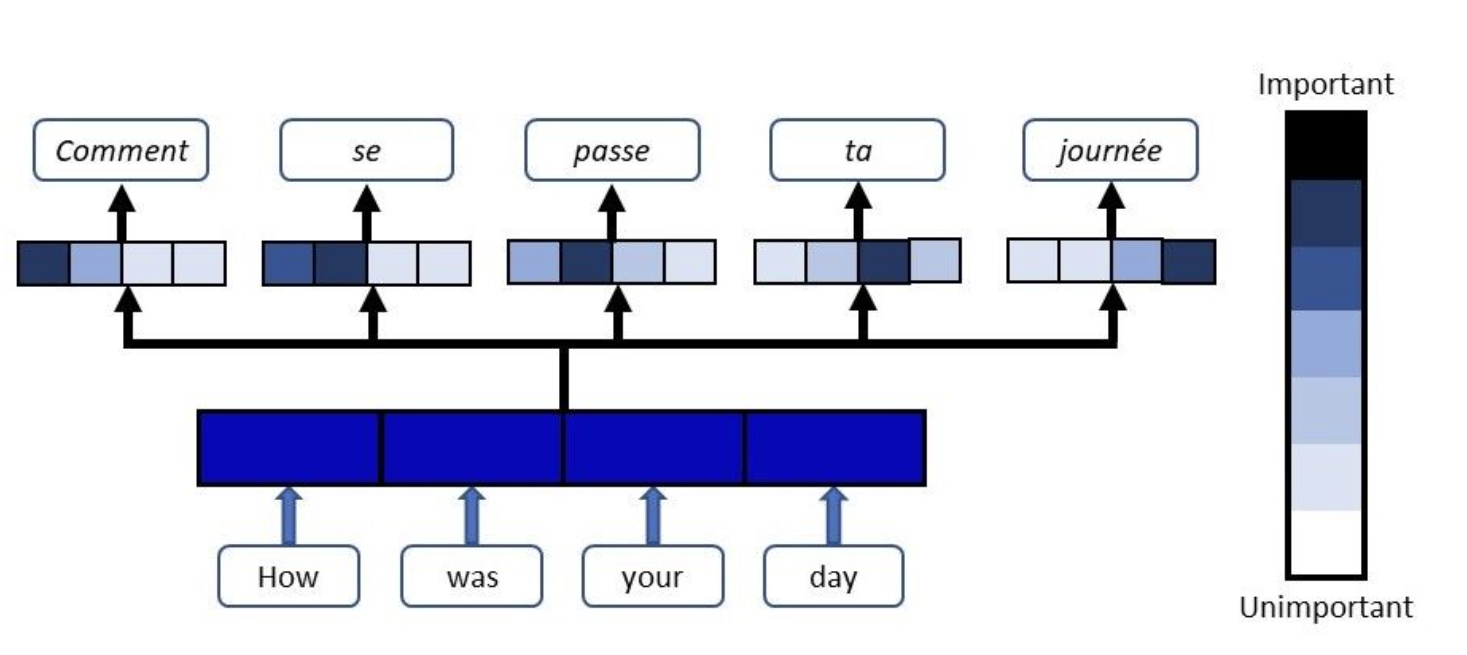
출처 : 아래에서 어텐션 메커니즘을 상세히 나눠서 설명하고 있습니다.
Attention Mechanism (floydhub.com)
R-CNN 계통처럼, 이미지를 입력으로 받는 모델에서 어텐션 메커니즘을 사용하면 모델은 이미지에서 특정한 물체나 패턴에 더욱 집중할 수 있습니다. 역시나 정확도 향상을 위해 사용됩니다.
다음 단계에서는 region proposal을 위한 신경망의 설계와 특성을 소개하고, 그 다음에는 공유된 피쳐로 두가지 모듈을 모두 교육하기 위한 알고리즘을 제시합니다.
줄이자면 RPN이 핵심
RPN은 input으로 임의의 크기를 가진 이미지를 받고, 객체의 존재 여부를 나타내는 개체 점수(objectness score)를 포함한 일련의 직사각형 객체 proposal을 output으로 내놓습니다. 이 과정은 완전 컨볼루션 신경망으로 모델링됩니다.
Faster R-CNN의 최종 목표는 Fast R-CNN object detection network(객체 탐지 신경망)과 계산을 공유하는 것이기 때문에, 두 신경망이 공통된 일련의 컨볼루션 레이어를 공유한다고 가정합니다.
연구진들은 실험을 통해 5개의 공유가 가능한 컨볼루션 레이어를 가진 "VGG-16"과 13개의 컨볼루션 레이어를 가진 "Overfeat + 슬라이딩 윈도우"을 사용합니다. 이를 통해 결과물을 수정하고, 보완할 것입니다.
regional proposal을 생성하기 위해, 연구진들은 마지막 공유 컨볼루션 레이어의 출력으로 얻은 컨볼루션 피쳐 맵 상에서, 작은 신경망을 슬라이딩 합니다. 이 작은 신경망은 n x n 공간 윈도우를 입력으로 받습니다. 각 슬라이딩 윈도우는 낮은 차원의 특징(ReLU가 사용되는 256 차원 혹은 512 차원)으로 매핑 됩니다. 이 피쳐는 박스-회귀 레이어(reg로 표현)와 박스-분류(cls로 표현) 레이어의 두 개의 fully connected layer로 들어갑니다. 이번 Faster R-CNN에서는
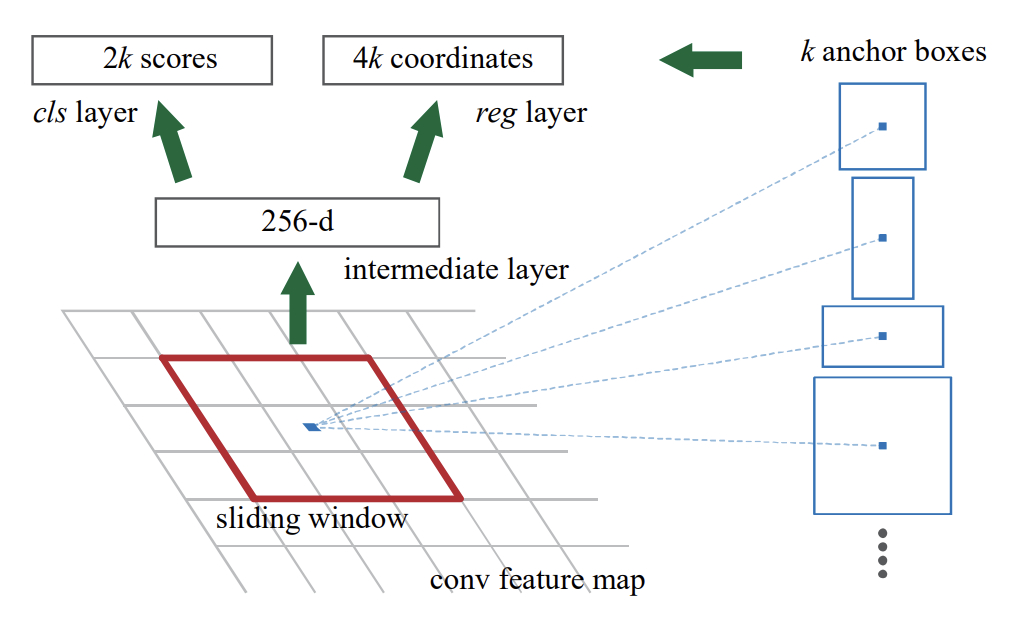
이 구조를 미니 네트워크(mini-network)라고 지칭합니다. 미니 네트워크는 슬라이딩 윈도우 방식으로 작동하기 때문에 Fully connected layer는 모든 spatial location에서 공유됩니다. 이 아키텍쳐는 자연스럽게 n x n 컨볼루션 레이어와 reg와 cls에 대해서 1x1 컨볼루션 레이어를 연이어 구성해서 구현됩니다.
앵커( Anchor )
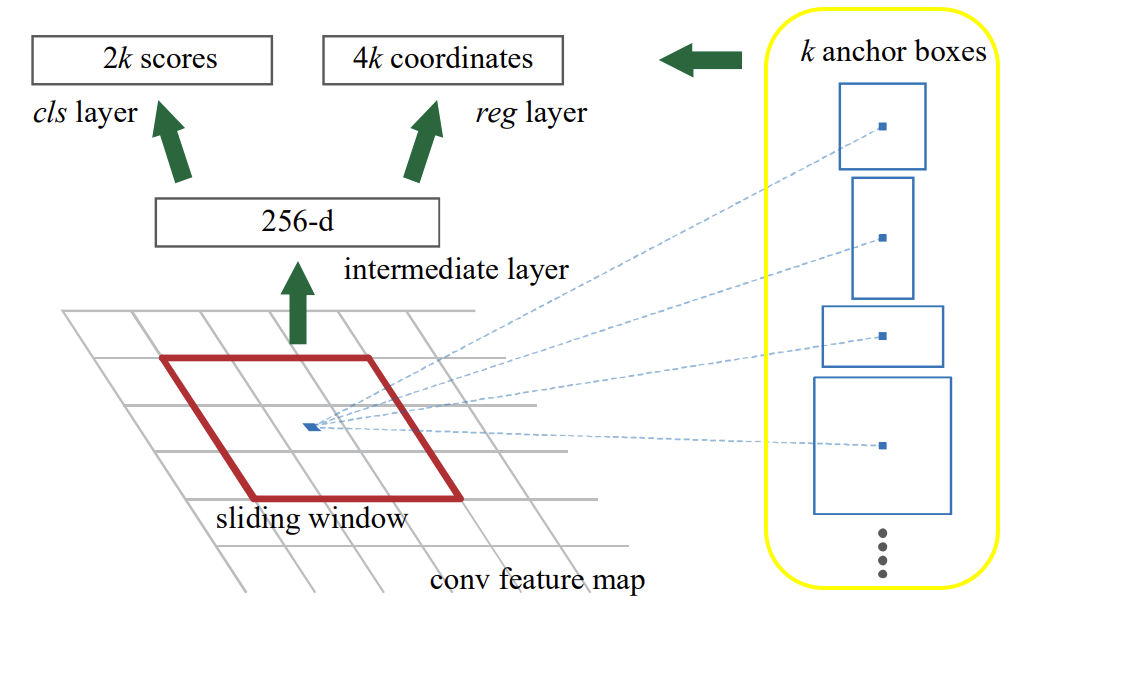
각 슬라이딩 윈도우 위치에서, 본 신경망은 동시에 여러 개의 region proposal을 예측합니다. 각 위치에서 가능한 최대 제안 수는
Anchor : 정리
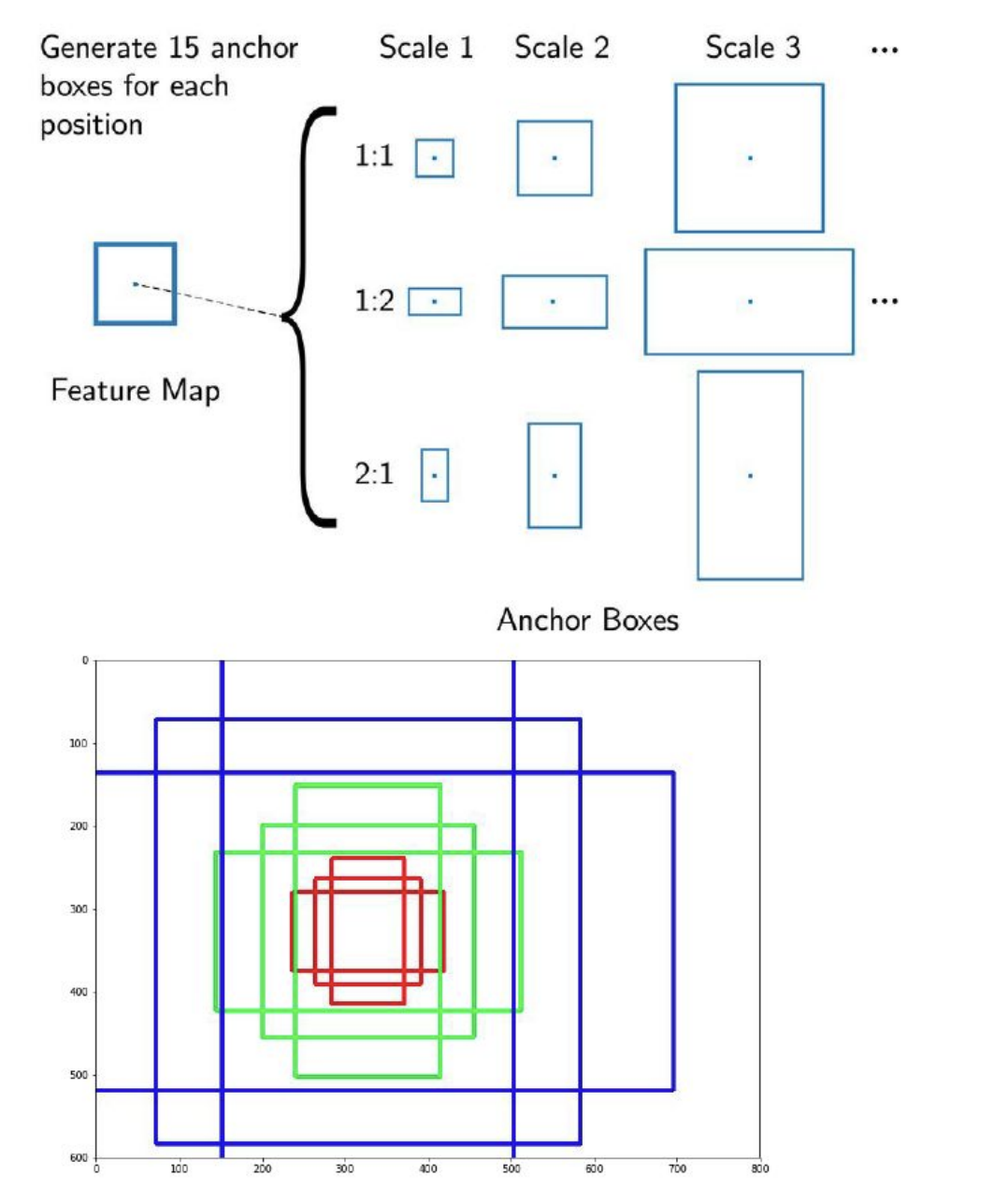
이미지 출처 : discussion_6_detection.pdf (stanford.edu)
객체 proposal 생성을 위해서 사용하는 바운딩 박스의 사전 정의된 위치와 크기를 의미합니다.
슬라이딩 윈도우 방식으로 이미지를 "흝으면서" 각 위치에서 일정한 비율과 크기를 가지는 박스를 생성하는데요. 이를 통해 만들어주는 것이 앵커 입니다.
Faster R-CNN에서는 이 알고리즘을 토대로 기존보다 더 높은 정확도와 속도를 가질 수 있다는 사실을 입증했습니다.
앵커는 해당 슬라이딩 윈도우를 중심으로 하며, 스케일 및 종횡비과 관련 있습니다. 기본적으로 이번 모델에서 3개의 스케일과 가로-세로 비율을 사용하여 각 슬라이딩 위치마다
앵커의 심화, Translation-invariant Anchor
Translation-invariant는 한글로 보면 이동 불변이라는 뜻을 가집니다. 일반적으로 신경망에서는 input 이미지의 위치가 조금씩 달라져도 학습된 신경망이 물체를 인식할 수 있도록 하는 "이동 불변성"을 고려하는 것이 중요합니다. 이동이 불변한 앵커를 구성한다는 것은 input 이미지의 이동 변화에 상관없이, 항상 일정한 기준으로 객체를 인식하도록 하는 것을 의미합니다. 논문에서의 설명도 한번 보겠습니다.
이번 R-CNN의 중요한 특징은 앵커와 앵커에 상대적인 proposal을 계산하는 함수 모두에서 이동 불변성을 가진다는 것입니다. 즉, 이미지 내 객체를 이동시키면 proposal도 이동하고, 동일한 함수가 두 위치에서도 proposal을 예측할 수 있어야 합니다. 이러한 이동 불변성은 이후 서술할 방법에서도 보장됩니다. 비교하자면, Multibox 방법은 K-MEANS 를 사용해서 800개의 앵커를 생성하지만 이동 불변성은 가지지 않습니다. 따라서 객체를 이동시키면 동일한 proposal을 생성하지 못할 수 있는데요. 더하여, 이동 불변성은 모델 크기도 줄입니다. multibox 방법은
다중 스케일(Multi-scale)에 대응하는 앵커
Faster R-CNN은 다중 스케일(종횡비 포함)을 처리하기 위한 새로운 방법을 제시합니다.
기존에 있던 방식은 아래와 같습니다.
(1) Deformable Part Model(DPM) 및 이미지 피라미드, Overfeat와 Fast R-CNN의 기반인 이미지/피쳐 피라미드(image/feature pyramid)에 기초를 두는 방법입니다.

다중 스케일에 대해 이미지 크기를 조장하고 각 스케일에 대해 피쳐 맵(Latent SVM) 또는 Deep convolution feature를 계산합니다. 이 방식은 유용하긴 하지만 시간이 많이 소요됩니다.
(2) 피쳐 맵에 다중 스케일(혹은 종횡비)의 슬라이딩 윈도우를 사용하는 방법입니다.

예컨대 DPM에서는 다른 필터 크기( 5 x 7, 7 x 5 등)을 사용하여 서로 다른 종횡비 모델을 별도로 학습합니다. 이 방법을 사용하여 다중 스케일을 처리하는 경우, "필터 피라미드"라고 생각할 수 있습니다. 이 방식은 (1)과 함께 사용되기도 합니다.
이렇듯 앵커를 기반으로 한 다중 스케일 구조 덕분에, Fast R-CNN 검출기에서처럼 단일 스케일 이미지에서 계산된 컨볼루션 피쳐를 간단하게 사용할 수 있습니다. 다중 스케일 앵커 구조는 스케일에 대한 추가 cost 없이 피쳐를 공유하는 데 필수적인 구성요소 입니다.
완성의 전단계, 손실 함수
이제 손실함수를 확인해보겠습니다. RPN을 학습시키기 위해서, 개발진들은 각 앵커에 이진 클래스 레이블(Binary class label. 객체이거나, 혹은 객체가 아니거나 판단)을 할당했습니다. 이부분에서 두 종류의 앵커에 대해 positive 레이블을 할당하는데요.
(i) Ground truth box와 가장 높은 Intersection-over-Union(IoU) 겹침을 갖는 앵커(앵커들)
IoU : 요약
두개의 영역이 얼마나 겹치는지 측정하는 방법 중 하나입니다. 예를 들어, 객체 검출을 위해 예측한 박스와, 실제 객체가 있는 박스 간의 겹치는 면적을 계산한 다음, 이 값을 두 박스의 면적의 합에서 겹치는 면적을 빼주어 계산합니다.
IoU는 0과 1사이의 값을 갖는데요, 1에 가까울수록 두 박스가 일치하고 0에 가까울수록 서로 다른 박스라고 보면 됩니다.
(ii) IoU 겹침이 0.7보다 높은 ground-truth 박스와 겹치는 앵커
이 두 앵커들에 positive lable을 줍니다. 단일 ground-truth box(정답으로 사용되는 박스)가 여러 앵커에 대해서 긍정 레이블알 할당할 수 있다는 점도 유의해야 합니다. 일반적으로 (ii) 조건만 충족시키면 충분하지만, 드물게는 긍정적인 샘플을 찾지 못하는 경우도 생기기에, (i) 조건도 사용해야 합니다.
만약 IoU 비율이 모든 그라운드 트루 박스에 대해 0.3 보다 작은 경우, 긍정 레이블이 할당되지 않은 앵커에 대해 부정 레이블을 할당합니다. 여기서 긍정 nor 부정인 앵커는 학습 목적에 기여하지 않습니다.
이러한 정의를 염두해두고, Fast R-CNN에서 사용하는 다중 손실 함수를 따르는 목적 함수(objective function)를 최소화할 수 있었습니다. 이제 아래와 같이 손실함수를 정의할 수 있습니다.
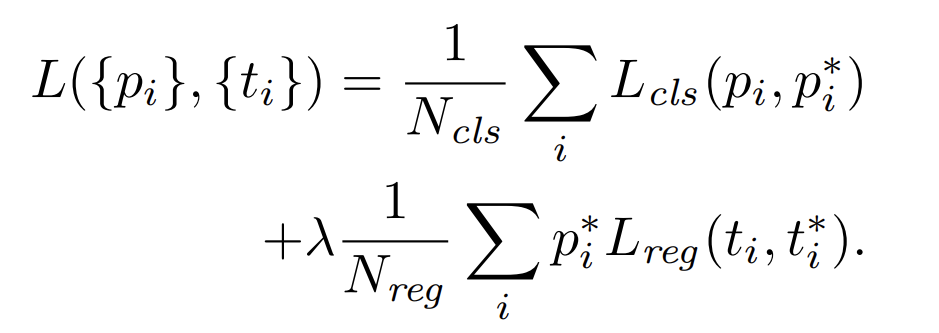
이때,
cls와 reg 레이어의 출력은 각각
두 항목은
테스트시
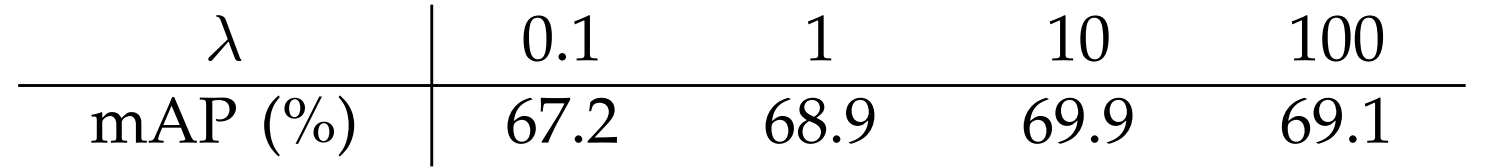
또 한가지 포인트를 알려드리는데, 위와 같은 정규화는 필수가 아니며, 단순화될 수 있다는 점입니다.
바운딩 박스 회귀(bounding box regression)에 대해서는 R-CNN 기술에 따라 4개의 좌표를 패러미터화 하는 방법을 채택합니다. 아래 식으로 표현합니다.
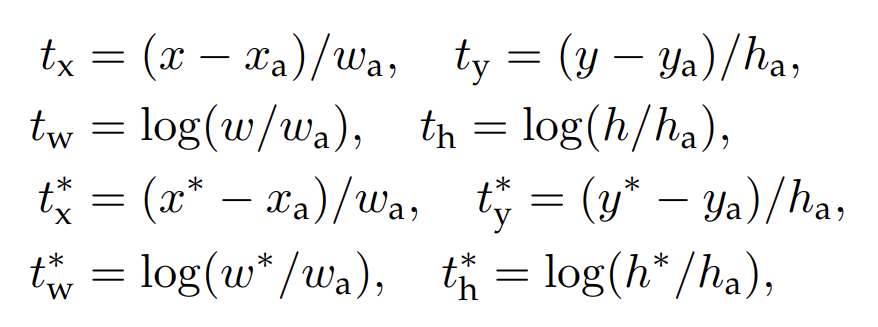
이때
이는 동일하게 y, w, h 값에도 적용됩니다. 앵커 박스에서 근처의 실제 박스로의 바운딩 박스 회귀로 생각할 수도 있습니다.
그러나 이전 Region of Interest(RoI) 기반 방법인 SPPnet, Fast R-CNN과 다른 방식으로 바운딩 박스 회귀를 달성합니다. 두 모델에서는 임의의 크기의 RoI에서 풀링된 피쳐에서 바운딩 박스 회귀가 수행되고, 회귀 가중치는 모든 영역 크기에 대해 공유됩니다. 이 공식에서, 회귀에 사용되는 피쳐는 피쳐 맵의 동일한 공간 크기 (3 x 3) 입니다. 크기에 대한 변화를 고려하기 위해, k 개의 바운딩 박스 regressor가 학습됩니다. 각 regressor는 한 가지 스케일과 종횡비를 담당하며, k개의 regressor는 가중치를 공유하지 않습니다. 본 방식으로 피쳐가 고정된 사이즈/스케일인 상태에서도 다양한 크기의 박스를 예측할 수 있습니다.
드디어, RPN을 학습하는 과정
이제 다행히 익숙한 기술들이 많이 등장하네요. RPN은 역전파(Backpropagation)와 SGD(Stochastic gradient descent)를 사용하여 엔드투-엔드 방식으로 학습할 수 있습니다. 오차 역전파의 페이퍼에서 제안된 "이미지 중심(image centric)" 샘플링 전략에 따라서, 각 미니 배치는 많은 긍정 및 부정예시앵커(example anchor)가 포함된 단일 이미지에서 생성됩니다. 모든 앵커의 손실함수를 최적화하는 것도 되지만, 이 이미지에서 256개의 앵커를 무작위로 샘플링하여 미니배치의 손실함수를 계산합니다. 샘플링된 긍정 및 부정 앵커의 비율은 최대 1:1 입니다. 다시말해, 여기서 만약 128개 미만의 긍정 샘플이 있는 경우, 미니배치를 부정 예시로 채웁니다.
새로운 레이어는 모두 공분산 가우시안 분포에서 표준 편차를 0.01로 가중치를 무작위로 초기화 시킵니다. 다른 레이어(공유 컨볼루션 레이어)는 따로 ILSVRC 에서 분류를 위해 모델을 사전 학습하여 초기화합니다. 개발진들은 ZFnet의 모든 레이어와 VGG net의 conv3_1과 up 레이어를 메모리 절약을 위해 조정합니다. PASCAL VOC 데이터셋에서는 60k 미니배치에 대해 학습률(learning rate)를 0.001로 설정하고, 다음 20k 미니배치에 대해 0.0001로 설정했습니다. 모멘텀은 0.9였고, 가중치 감쇠(weight decay)는 0.0005로 설정합니다(구현은 Caffe로 활용).
R-CNN과 Fast R-CNN을 위한 공유 피쳐
현재까지 RPN에 대해서 학습하는 방법을 설명했지만, 객체 탐지 CNN은 고려하지 않았습니다. 객체 탐지 신경망으로는 Fast R-CNN을 사용하며, 공유 컨볼루션 레이어를 가진 RPM과 Fast R-CNN으로 구성된 통합 신경망을 학습하는 알고리즘을 살펴봅니다.
RPN과 Fast R-CNN 양자는 각각 독립적으로 학습되며, 컨볼루션 레이어도 각각 다른 방식으로 수정됩니다. 그러므로, 두 개의 별개 신경망을 학습하는 대신 서로 컨볼루션 레이어를 공유할 수 있는 기술을 개발해야 하는데요. 아래 세 가지 방법으로 공유 피쳐를 사용하는 방식을 보여줍니다.
1. 번갈아가면서 학습하기(Alternating training)
먼저 RPN을 학습한 다음, proposal을 사용하여 Fast R-CNN을 학습하는 방식입니다. Fast R-CNN으로 조정된 신경망은 RPN을 초기화하는데 사용되고, 이 과정을 반복합니다. 이는 연구진이 모든 실험에서 사용한 방식이라고 합니다.
2. 근사적 조인트 학습(Approximate joint training)
RPN과 Fast R-CNN 신경망이 합쳐져서 하나의 신경망으로 훈련되며, 위 Faster R-CNN을 표현한 이미지와 같이 진행됩니다. 각 SGD의 반복(iteration)에서 포워드 패스(forward pass)는 영역 제안을 생성하며, Fast R-CNN detector를 학습할 때 미리 계산된 고정 proposal과 마찬가지로 처리됩니다. 역전파도 통상적으로 이루어지며, 공유 레이어의 경우 RPN 손실과 Fast R-CNN 손실에서 역전파된 시그널이 결합됩니다. 이 방법은 구현이 쉽지만, proposal 박스 좌표에 대한 미분도 신경망 반응이므로 근사적(Approximate)입니다. 실험에서는 대체로 결과가 유사하지만, 번갈아가면서 학습하기에 비해, 훈련 시간이 20~50% 줄어드는 것을 확인했습니다.
3. 비근사적인 조인트 학습(Non-approximate joint training)
앞서 언급한 것처럼 RPN이 예측한 바운딩 박스는 입력 데이터의 함수로서 동작합니다. Fast R-CNN의 RoI 풀링 레이어는 컨볼루션 피쳐와 예측한 바운딩 박스를 입력으로 받기 때문에, 이론적으로 유효한 역전파 기법은 박스 좌표에 대한 기울기도 포함해야 합니다. 이러한 기울기는 방금 말한 근사적 조인트 학습에서 무시되었습니다. 비근사적인 조인트 학습 방식에서는 박스 좌표에 대한 미분 가능한 RoI 풀링 레이어가 필요합니다. 이는 본 페이퍼에서는 해결하기 어려운 문제라고 하는데요. 독특하게도 해결법을 찾으려면 Multi-task Network Cascade(MNC)의 내용이 담긴 논문의 일독을 권하고 있습니다. 여기서 RoI warping layer를 사용을 추천하네요.(이 참조 논문도 Faster R-CNN을 언급하고 있습니다)
4단계 교대 학습(Alternative training)
연구진은 교대 최적화를 통해 공유 기능을 학습하는 실용적인 4단계 학습 알고리즘을 정했습니다.
1단계에서는 RPN을 학습하는 과정에서 설명한 대로 RPN을 학습하구요. 이 신경망은 ImageNet 사전 학습 모델로 초기화되고, region proposal 작업을 위해 엔드투-엔드로 fine-tuning 됩니다.
2단계에서는 RPN에서 생성된 proposal을 사용하여 Fast R-CNN을 사용한 별도의 탐지 신경망을 학습합니다. 이 신경망도 ImageNet 사전 학습모델로 초기화됩니다. 위 시점에서 두 신경망은 컨볼루션 레이어를 공유하진 않습니다.
3단계에서는 공유 컨볼루션 레이어를 고정하고, RPN에 고유한 레이어(Unique to RPN)만 fine-tuning 하여 탐지 신경망을 사용하여 RPN 학습을 초기화합니다. 이제 두 신경망은 컨볼루션 레이어를 공유합니다.
마지막, 4단계에서는 공유 컨볼루션 레이어를 고정한 채, Fast R-CNN의 고유한 레이어를 fine-tuning 합니다. 이렇게 하면 두 신경망이 동일한 컨볼루션 레이어를 공유하고, 통합된 신경망을 구성할 수 있습니다. 비슷한 교대 학습을 더 많은 반복에서 실행할 수 있지만, 연구진들은 이를 무시할 만한 개선안만 확인했다고 합니다.
< 그 이후 내용은 구체적인 실험의 변수나 parameter를 조정한 내용들 입니다>
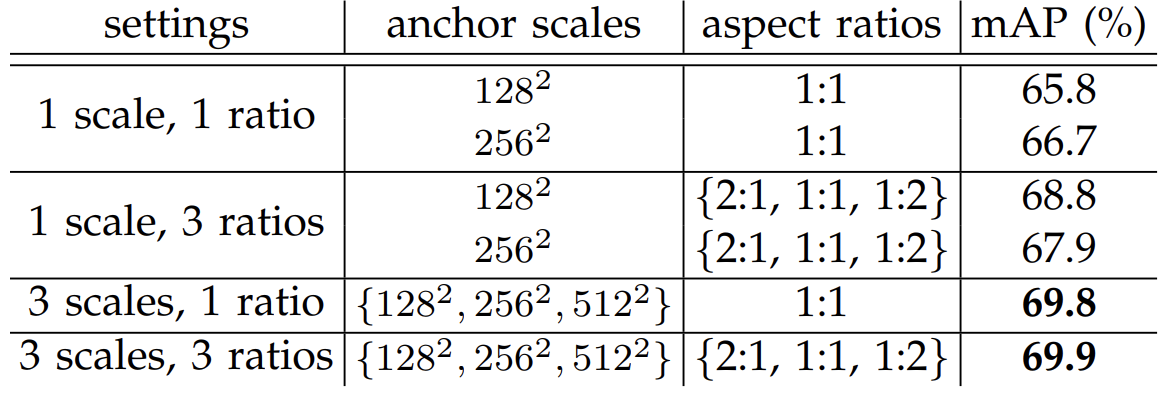
이 부분이 서로 다른 앵커 설정을 사용한 Faster R-CNN의 테스트 결과 입니다(PASCAL VOC 2007 데이터셋)
3개의 스케일과 3개의 종횡비를 사용했습니다. 각각의 앵커 크기도 다르네요.

proposal의 수마다 변화하는 recall 및 IoU의 수치도 제시하고 있습니다.
아래는 결과적으로 Faster R-CNN 모델을 사용해서 보여주는 객체 탐지의 이미지(일부) 입니다.
시간도 198ms의 안정적인 시간으로 측정되었다고 제시하고 있습니다.
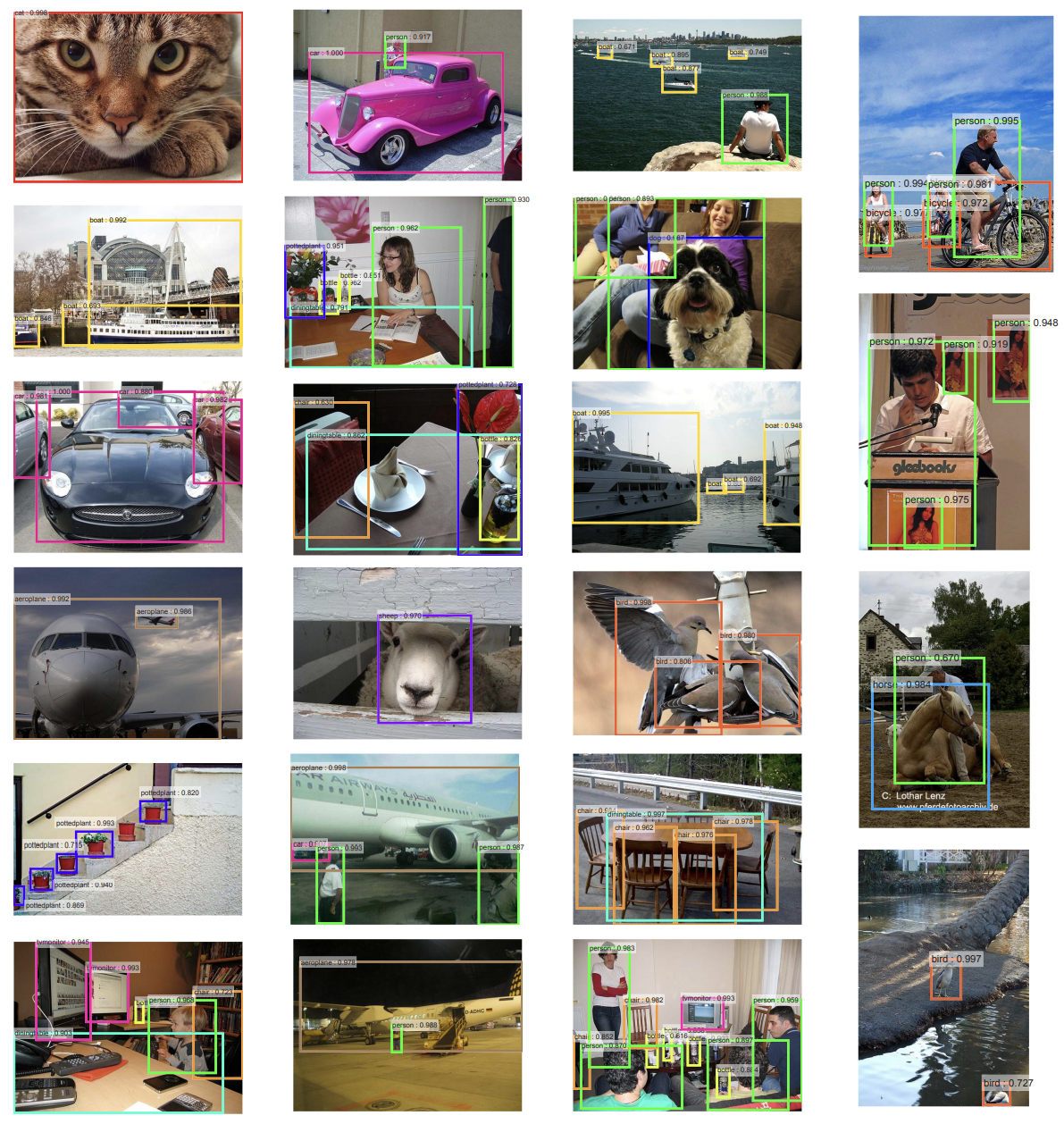
여기까지 하여, Faster R-CNN의 모델 설명과 논문 분석을 마치겠습니다. 다음시간에도 R-CNN 계열의 발견 이후에 더 흥미로운 이미지 처리 모델이 있다면 살펴보겠습니다.
※ 23.03.19 1차 수정 : 레퍼런스, 링크, 문법 추가 수정
Reference
* 반복되서 사용된 논문들은 본문에도 링크가 참조되어 있습니다.
Faster R-CNN 원 논문 : [1506.01497] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (arxiv.org)
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottle
arxiv.org
discussion_6_detection.pdf (stanford.edu)
Why does Faster R-CNN use anchor boxes? - Quora
Why does Faster R-CNN use anchor boxes?
Answer: In image classification we are interested in the class of objects that are present irrespective of their locations. We can extend this a bit further by localizing them, which is called object detection. Let's start with a basic example of how this
www.quora.com
Microsoft Word - FB6197 (iop.org)
Object Detection for Dummies Part 2: CNN, DPM and Overfeat | Lil'Log (lilianweng.github.io)
[1512.04412] Instance-aware Semantic Segmentation via Multi-task Network Cascades (arxiv.org)
Generating Object Proposals | pdollar (wordpress.com)
'딥러닝 > 신규 모델&기술 설명' 카테고리의 다른 글
| [세미나 정리] 2023 K-디지털 플랫폼. Meet, AI 세미나 현장스케치 (2) | 2023.05.25 |
|---|---|
| [논문 리뷰] GAN에서 한 발짝 앞서서, PGAN(Progressive-GAN) 기술 분석 (2) | 2023.03.11 |
| [Deep Learning] YOLOP v2 / 더 향상된 욜로 모델! - 논문리뷰 (0) | 2023.03.01 |
| [DeepLearning] YOLOv 모델, you only look once 논문 분석 (0) | 2023.02.27 |
| [DeepLearning] IRB에 관하여 (0) | 2023.02.15 |



