이번시간에는 최근 2~3년 새에 이미지 분류 분야에서 상당히 핫한 주제중 하나였던, YOLO(You Only Look Once) 모델에 대해서 알아보았습니다.
이름도 참 흥미롭죠? 오직 한번만 봐도 된다, 굉장히 직관적인 이름이 아닐 수 없습니다. 2015년 1월 처음으로 기고가 된 YOLO는 이제 학습모델 중에서 아시는 분들은 다 아는 울트라리틱스(Ultralytics Hub)와 로보플로우(Roboflow) 애플리케이션에 연결되어 사용되고 있습니다.
○ 울트라리틱스, 로보플로우 참조
https://hub.ultralytics.com/
Ultralytics HUB
hub.ultralytics.com
Workspace Home (roboflow.com)
Sign in to Roboflow
Even if you're not a machine learning expert, you can use Roboflow train a custom, state-of-the-art computer vision model on your own data.
app.roboflow.com
심지어 베타버전으로, 무료입니다! 울트라리틱스는 전문가 수준의 모델 구현능력이 아니더라도 쉽고 직관적으로 이미지 학습을 시작할 수 있도록 많은 도움을 주고 있습니다.
아직 개선이 필요한 부분이 없진 않지만 머리 아픈 코드와 씨름하지 않으면서 좋은 결과값을 도출할 수 있는 방법을 추천합니다.
데이터셋의 크기에 따라서 사이즈를 너무 크지 않게 고를 수 있는 것도 큰 장점이 됩니다.
이 논문이 나온지 이제 8년이 다 되어가면서, YOLO의 v5까지 출현하며 폭발적인 연구 성과가 있었습니다.
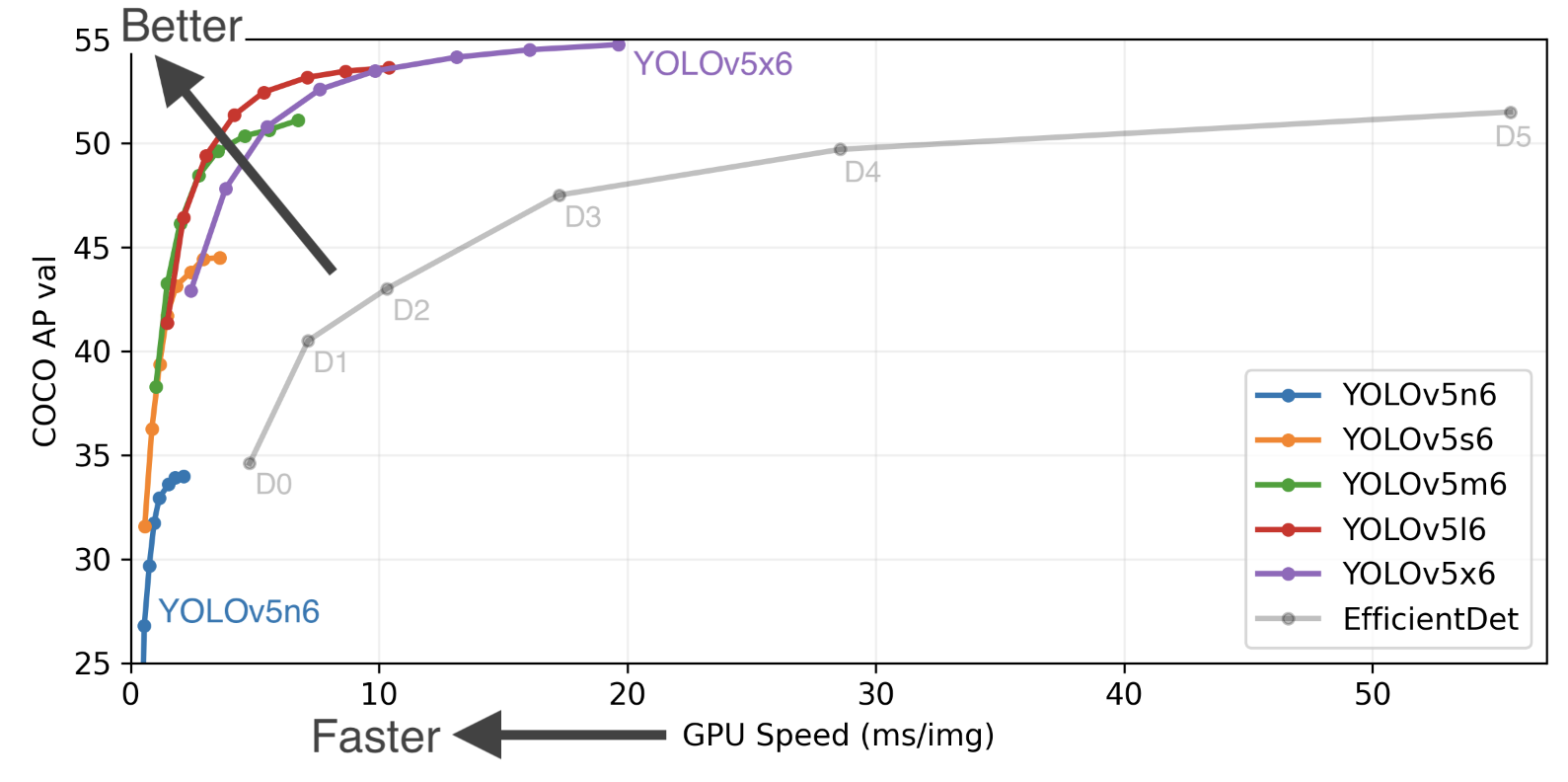
YOLOv5 | PyTorch
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
pytorch.org
연구진들은 이미지 감지에 대한 고찰로부터 시작합니다.
인간의 시각적 인지능력이란.
우리는 어떻게 사물을 인지하고, 어떻게 이렇게 빨리 눈으로 입수한 정보를 정확하게 판단할 수 있을까요?
YOLO가 고민한 지점이 이 부분입니다. 인간의 시각정보 체계는 우리가 개발한 어떠한 것보다도 빠릅니다. 사람의 빠르고 정확한 알고리즘은 물체를 판단하는데 있어 고도의 기계 센서없이 거의 자동적으로 이루어집니다. 자동차를 운전한다고 생각해보시면 이해가 빠르실 겁니다. 도로의 상황이나 주변 환경, 표지, 차의 상태 등을 하나하나 구분해서 인지하시나요?
아마 모든 상황을 동시에 판단하고 즉각적으로 대응할 겁니다. 인간의 이런 실시간 판단 능력은 기계에 적용한다면 상당한 혁신을 불러올 것입니다.
YOLO 개발 당시의 감지 시스템은 분류기(Classifiers)를 감지를 위해 용도를 변경한 것이었습니다. 사물을 감지하기 위해서 기존의 시스템들은 객체들을 분류기에 넣고, 검증 이미지에 있는 다양한 장소와 스케일들을 테스트 했습니다. DPM(Deformable parts model)과 같은 시스템은 전체 이미지를 넘어서 마주치는 장소들을 고르게 보는 분류기에서 슬라이딩 윈도우처럼 작동했습니다.
참고 이미지 : 슬라이딩 윈도우 알고리즘
당시에 진행했던 R-CNN(영역별 합성곱 신경망; Regions with Convolution Neural Network Features)은 영역별 제안 기법 (Region proposal methods)를 사용, 이미지 안에 있는 잠재적인 바운딩 박스들을 먼저 만들고 그 제안된 박스들을 통해 분류기를 돌리는 것이었습니다.

출처 : YOLOP | PyTorch
분류작업이 끝나면 바운딩 박스들을 정제(refine)하며, 이른바 후처리를 하는데요. 중복된 감지결과를 제거하고 장면안에 있는 다른 객체들을 기준으로 재채점(rescore)를 진행합니다. 각각의 개별 컴포넌트들이 분할되어 학습해야 하기 때문에 이러한 컴플릭스 파이프라인은 느리고, 최적화하기도 어렵습니다.
연구진들은 단일 회귀 문제로 이 객체 탐지를 재정립하고, 클래스 확률과 바운딩 박스 좌표의 이미지 픽셀에서 바로 가져온다는 방향으로 나아갔습니다. 이 시스템 (yolo를 말함)을 사용하면 물체들이 어디에 있는지와 현재 어떻게 존재하는지 예측하는 이미지를 단 한번만 봐도 됩니다.
Yolo는 아래와 같은 점에서 간단합니다.

여러 박스들을 위한 클래스별 확률과 다수의 바운딩 박스들을 동시에 예측하는 단일 합성곱 신경망을 나타내고 있습니다. YOLO는 이미지 감지의 성능을 최적화하고 전체 이미지들을 훈련합니다. 이러한 통합된 모델은 과거 이미지 감지 기법들보다 몇가지 뛰어난 점을 보여주는데요.
먼저, YOLO는 극단적으로 속도를 높혔습니다. 연구진들은 여기에 따르면 복잡한 파이프라인이 필요하지 않기에 감지를 회귀 문제라고 생각합니다. 감지물을 예측하기 위해 새로운 이미지를 검증하는 시간을 거치는 신경망을 구성했습니다. 여기서 또 신기술이 나오네요.

이들은 타이탄X GPU(Titan X GPU)를 사용, 배치 프로세싱 없이 초당 45프레임으로 구동하는 신경망을 사용했고 빠른 버전은 150 fps를 넘기도 했습니다. 즉, 25 밀리초 이하의 latency를 가지는 실시간의 스트리밍 비디오로 처리할 수 있게 된 것입니다. 더구나, YOLO는 다른 리얼타임 시스템의 정밀도(precision) 평균값의 두 배 이상의 정밀도를 달성했다고 합니다.
두번째 특징에 대한 소식, YOLO는 예측값을 만들 때 이미지를 전역적으로 추론합니다. 영역별 제안에 기반을 둔 기법과 슬라이딩 윈도우와 다르게, YOLO는 객체들의 외견 만큼이나 군집(classes)들의 맥락적인 정보를 암묵적으로 인코딩하기 때문에 학습&검증 시간동안 전체적인 이미지를 봅니다. 최고 수준의 감지 기법인 Fast 영역별 합성곱 신경망(Fast R-CNN)은 더 커다란 맥락을 보지는 못했기 때문에 이미지의 객체에 대해서 배경의 지면들에 대해서 놓치는 경우가 있었습니다. YOLO는 Fast R-CNN과 비교해도 배경 오류가 절반 이하로 줄어들게 했습니다.

세번째, YOLO는 객체의 일반화 가능한 표현들을 학습합니다. YOLO는 예술작품에 대한 검증과 자연 이미지에 대해 학습했을 때, 더 넓은 가장자리를 두어서 DPM이나 R-CNN의 기법들처럼 최상위권 감지 기법보다 높은 성능을 보입니다.
예측못한 입력물들이나 새로운 도메인들이 적용될 때, 오작동(break down)되는 일이 적습니다. YOLO가 꽤 일반화 가능한 표현물을 쓰기 때문입니다.

YOLO는 정확도 측면에서 최첨단 감지 시스템들에 비해서는 약간 지연되는 편입니다. 본 모델이 특별히 작은 개체들에 대해서는 빠르게 캐치하는 반면, 어떤 객체들을 정밀하게 배치하기 위해서는 많은 노력을 필요로 하네요.
아래는 기술항목에 대한 설명입니다.
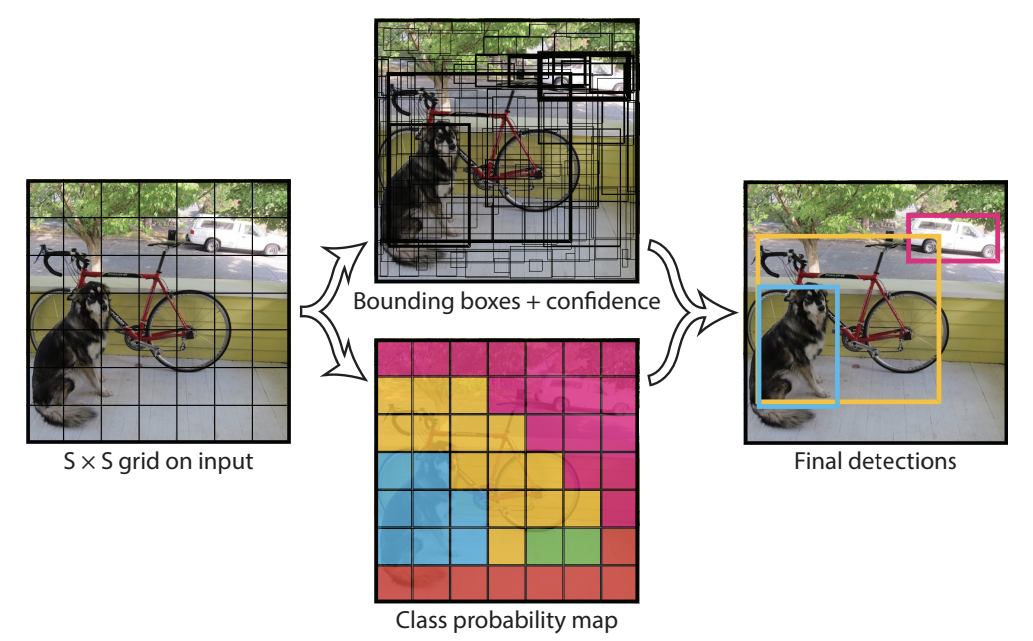
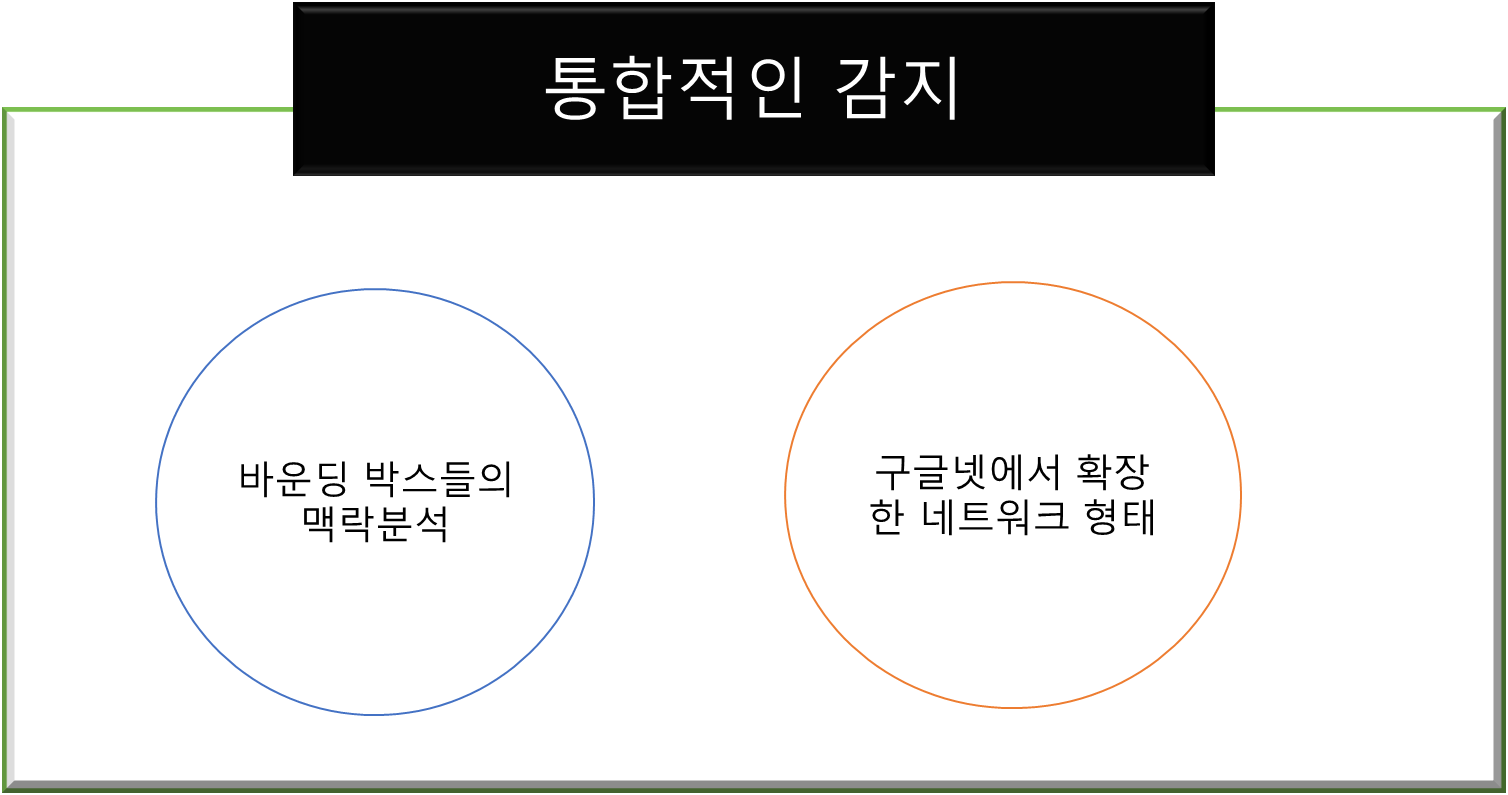
이렇게 두가지 정도로 YOLO 기법의 특징을 정리할 수 있습니다. 바운딩 박스들의 Context에 대한 무시가 아니라 전적인 고려, 전체적인 특징에 대한 판단도 있었습니다. 근본적으로 GoogleLeNet에서 더 발전한 합성곱 신경망구조에서 감지 정확도를 높혔던 기법입니다.
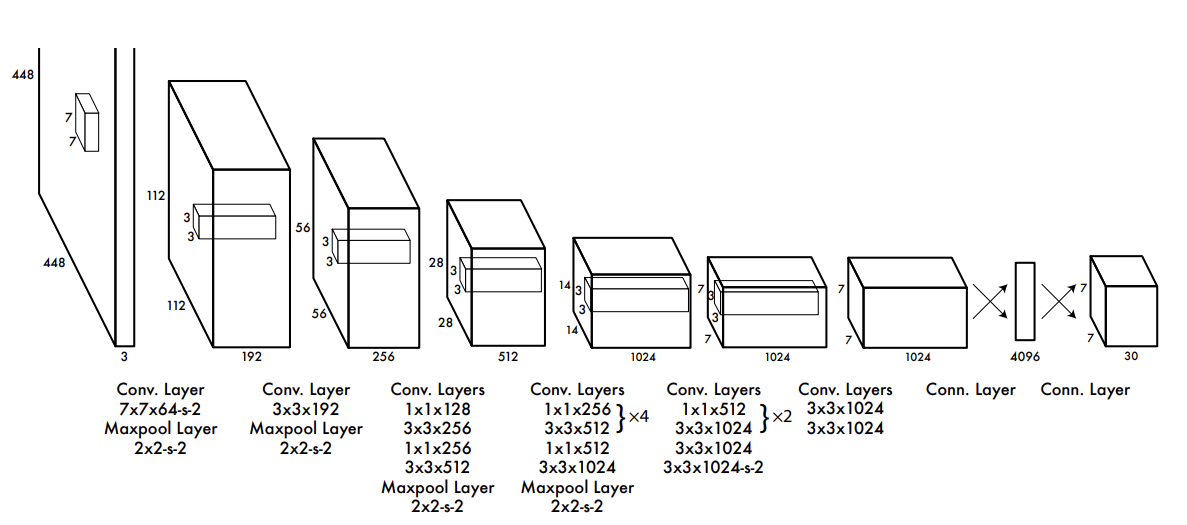
앞으로의 과제는 신경망 구조의 규모(경량성)과 정밀도입니다. YOLO는 각각의 그리드 셀이 오직 두개의 박스들로만 구분되고, 한 개의 클래스로만 예측되도록 바운딩 박스의 공간을 강하게 제한합니다. 이 강력한 제한점은 YOLO의 예측할 수 있는 객체는 소수의 객체만 판별할 수 있도록 만듭니다. 연구진들은 떼지어 가는 새들의 무리처럼, 작은 개체들이 그룹안에 있는 이미지도 감지할 수 있도록 문제의식을 던지고 있습니다.
원문 Reference
[1506.02640] You Only Look Once: Unified, Real-Time Object Detection (arxiv.org)
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
위 링크를 통해 원 논문을 만나보실 수 있습니다.
다음 시간에는 더욱 고성능, 최신화된 모델을 찾아보도록 하겠습니다.
'딥러닝 > 신규 모델&기술 설명' 카테고리의 다른 글
| [논문 리뷰] GAN에서 한 발짝 앞서서, PGAN(Progressive-GAN) 기술 분석 (2) | 2023.03.11 |
|---|---|
| [Deep Learning] YOLOP v2 / 더 향상된 욜로 모델! - 논문리뷰 (0) | 2023.03.01 |
| [DeepLearning] IRB에 관하여 (0) | 2023.02.15 |
| [DeepLearning] LA-MCTS에 관하여 (0) | 2023.02.14 |
| [DeepLearning] GPU-Net을 활용한 이미지 분류_1 (0) | 2023.02.13 |



