지난 시간에 이어서, 이미지의 객체 인식(object detection)에 대해서 yolo를 더 탐구해보고자 합니다.
현시대까지 이루어진 Object detection에 대해 분류와, 시대적 흐름에 대해서 아주 잘 정리한 글이 있어서 이부분도 참조 합니다.
[컴퓨터비전10] 자율주행자동차의 핵심 알고리즘, 객체 인식(Object Detection) 기본 개념 정리 (tistory.com)
[컴퓨터비전10] 자율주행자동차의 핵심 알고리즘, 객체 인식(Object Detection) 기본 개념 정리
안녕하세요. 데이터 요리사, 루나 입니다. 자율주행 자동차는 실시간으로 주변의 객체를 인지하고, 상황을 판단해서, 차량을 제어하는 엄청난 기술의 총 집합체라고 할 수 있습니다. 이번 글에
zhining.tistory.com
이번에 살펴볼 논문은 <YOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception> 입니다.
YOLOPv2를 아래와 같이 활용한 곳은 중국 난징 소재의 T3CAIC라는 자동차 기업으로, 이와 관련해서 찾아본 결과 중국 쪽에서도 객체 인식이나 자율 주행과 관련해서 많은 발전이 진행된 것으로 보입니다. (특히 YOLO 모델에 한해서)
국내에서도 이 분야에 물론 혁혁한 성과가 있었지만 논문의 수나 관심도 측면에서는 중국의 성과도 눈여겨 보고, 바짝 쫒아가기 위한 라이벌 의식(?)도 가져야 할 것 같습니다.
원 출처 : YOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception | Connected Papers
Connected Papers | Find and explore academic papers
A unique, visual tool to help researchers and applied scientists find and explore papers relevant to their field of work.
www.connectedpapers.com
바로 이전에 8년전에 발표된 YOLOP 초기 모델을 소개하면서, 모델의 장점으로 real-time에 가까운 고속 탐지, 전역적인 추론을 언급한 바 있습니다. 컴퓨터 비전이 고속성을 가지면 가질수록 이미 그것(object)가 지나간 다음에 분석하는 것이 아니라, 바로 그 즉시 현장에서 사용자가 그것(object)을 직접 사용할 수 있게 됩니다. 그렇다면 이때 궁금증이 생깁니다.
이것을 어디에 이용할 수 있을까요?
바로 "운전"입니다. YOLO가 자율주행의 기술적인 혁신을 불러일으킨 것인지, 자율주행에 대한 관심이 YOLO의 성숙도를 높인 것인지는 알 수 없었지만, 일단은 자율주행 차량을 위한 모델링에 곧바로 쓰이고 있었습니다. 운전을 하는 동안 필요한 능력인 멀티테스킹 능력을 최대한 발휘할 수 있도록 말이죠. 기업 연구진들은 판옵틱 세그멘테이션(panoptic segmentation)을 운행중 인식 기술에 적용시키면서, 높은 정밀도와 높은 효율성을 동시에 발휘하는데 성공합니다.
새로운 개념이 또 등장했는데요. 판옵틱 세그멘테이션은 이미지를 감지하는데 있어서, 배경정보 뿐만 아니라 관심을 두는 객체의 인스턴스까지 구별해서 탐지하는 기법입니다. 본 기법에 대해서는 아래 블로그의 설명을 참조합니다.
Instance/Panoptic segmentation (velog.io)
Instance/Panoptic segmentation
Week7(CV), Day 34. Instance/Panoptic segmentation
velog.io
연구진에 의하면 컴퓨터 비전과 딥러닝, 시각을 기점으로 한 객체 인식, segmentation, 레인 인식(lane detection)의 발전이 이루어지고 있었지만, 개발 당시에는 아직 자율주행에서는 애매한 부분이 남아있었습니다.
자율주행의 '가성비' 적인 측면에서 말입니다.
연구진들은 자율주행의 주된 구성요소인 robust panoptic driving perception 시스템으로 꼽았습니다. 이를 자율주행의 효율성 즉, 가격을 낮추는 키포인트가 될 것이라고 생각한 것이죠.

이미지 출처 : CAIC-AD/YOLOPv2: YOLOPv2: Better, Faster, Stronger for Panoptic driving Perception (github.com)
GitHub - CAIC-AD/YOLOPv2: YOLOPv2: Better, Faster, Stronger for Panoptic driving Perception
YOLOPv2: Better, Faster, Stronger for Panoptic driving Perception - GitHub - CAIC-AD/YOLOPv2: YOLOPv2: Better, Faster, Stronger for Panoptic driving Perception
github.com
첫째, 실시간 교통상황에서의 객체 탐지기
당대의 객체를 감지하는 detectors는 1단 감지기와 2단 감지기로 나뉘어졌습니다. 2단 감지기는 다시, 두개의 요소로 구성됬습니다. 하나는 구역별로 제안하는 부분, 하나는 탐지를 refinement하는 부분입니다. 이 기법들은 정밀도를 높이고, 1단 객체 감지기가 더 빠르게 변화시킴으로써 실시간으로&현실적으로 테스트하는데 자주 보이게 되었습니다. YOLO 시리즈가 향상된 1단 객체 탐지 구조를 계속해서 반복했습니다. 연구진들은 간단하지만 강력한 신경망 구조인 BOF(Bag of Freebies) 기법을 사용함으로서 객체 탐지의 성능을 높였습니다.

다시 돌어가서, fully 합성곱 신경망(CNN)을 사용함으로써 기존의 세그멘테이션 알고리즘을 대체할 시멘틱 세그멘테이션(semantic segmentation)에 대한 연구가 진행됬습니다. 더 높아진 성능의 모델인, U-net의 인코더+디코더 구조, PSPNet에서 다른 차원의 피쳐들을 추출하는데 쓴 피라미드 풀링 모듈(pyramid pooling module)도 있었습니다. 이 기법들은 주행가능한 구역을 효과적으로 나누는데 영향을 미쳤습니다.
참조 : U-Net의 구조와 PSPNet의 구조
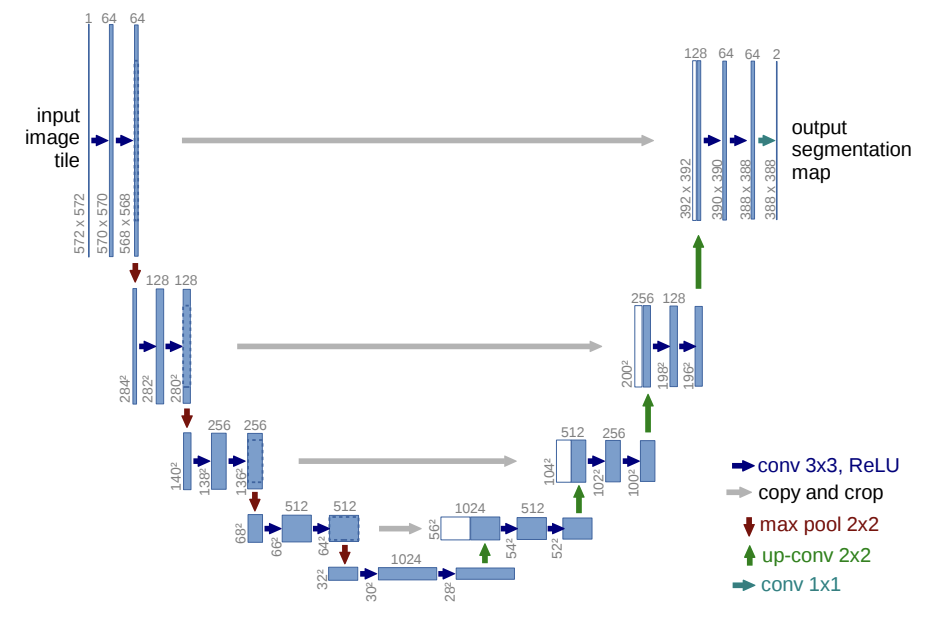
U-Net은 2015년에 발표한 알고리즘으로, 이번에는 독일산 모델이네요. 세포 단계에서 이미지 augmentation을 하는 과정에서 발전된 모델입니다. 좌측 부분이 인코더이고 우측 부분이 디코더입니다. U자 형태를 갖고있네요. 이 모델에 대해서도 다음시간에 논문과 함께 살펴보겠습니다.
[U-Net: Convolutional Networks for Biomedical Image Segmentation]
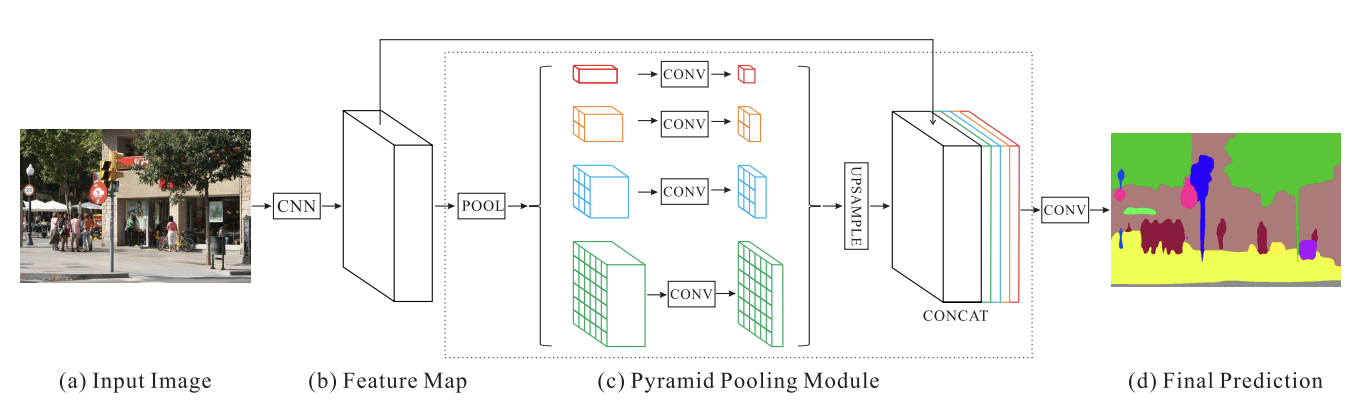
PSPNet은 주로 도시환경에서 객체를 탐지하는데 사용했었던 모델입니다. 위에서처럼 convolution을 하는 계층에서 각자 다른 사이즈가 나오도록 pooling을 해서 다시 합쳐주는 것이 골자입니다. 속도는 그렇게 빠르지 않지만 이를 희생하고 정확도를 높인 모델이라고 볼 수 있습니다.
둘째, 주행가능 영역과 레인 세그멘테이션 기술
레인 세그멘테이션을 위해선 차선의 형태가 얇다는 특징과 픽셀 분산이 파편화되어 있다는 점을 고려해야 합니다. 즉, 이전보다 더 세밀한 탐지 기술을 필요로 합니다. SCNN의 경우 슬라이스 바이 슬라이스 합성곱(slice-by-slice convolution)을 통해 각 레이어 사이로 정보를 전달하는 기법도 있었구요. Enet-SAD라는 모델은 셀프 어텐션 정류 기법(self-attention rectification method)을 택해서 높은 레벨의 피쳐를 낮은 레벨의 피쳐도 학습할 수 있도록 하여, 모델이 구조자체가 경량화될 수 있도록 성능을 높였습니다. 모델의 경량화 부분은 이전의 YOLO v1 부분에서도 강조한 부분이죠.
▼ self-attention distillation을 사용한 SAD(Enet-SAD)의 사례
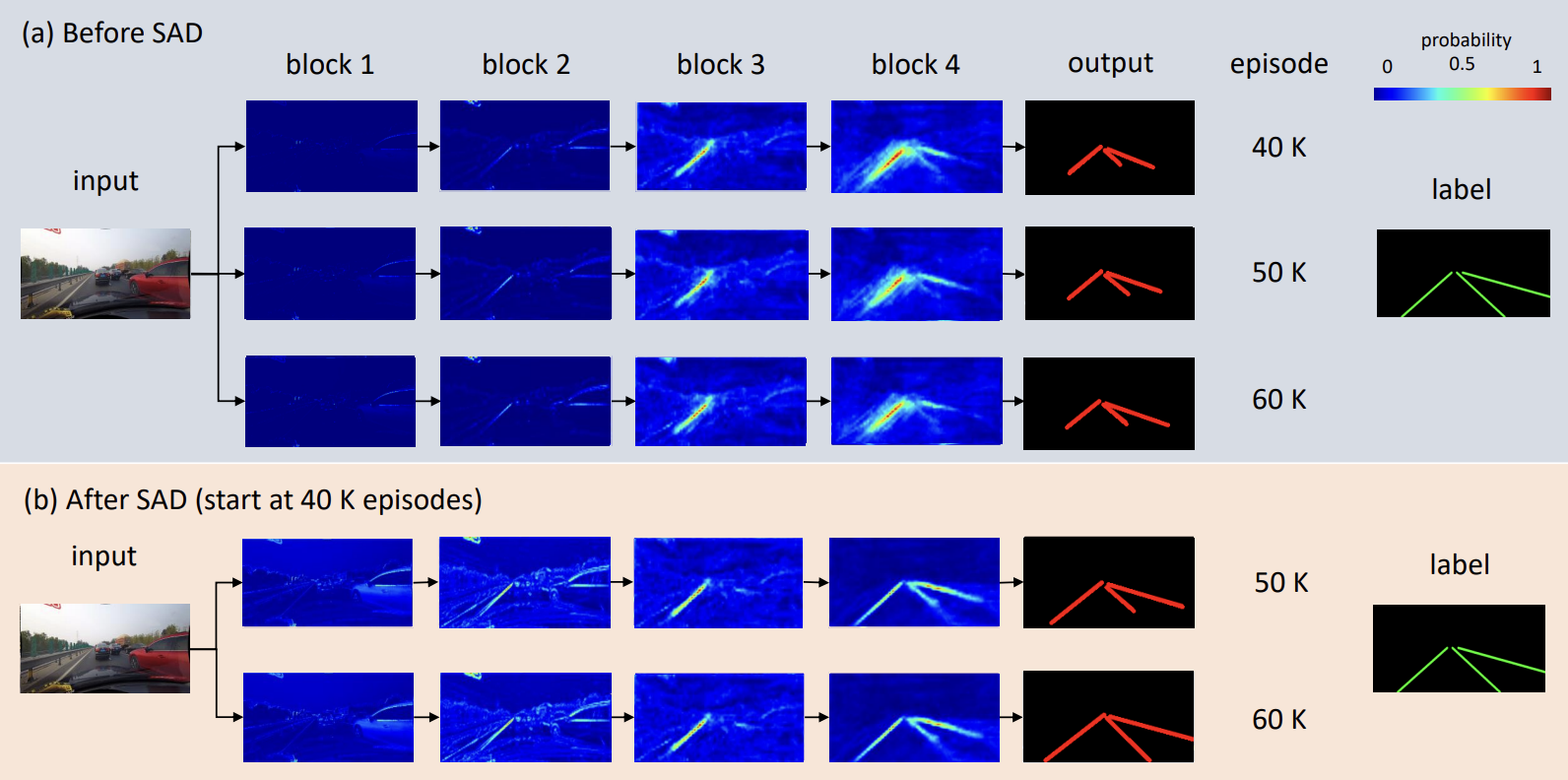
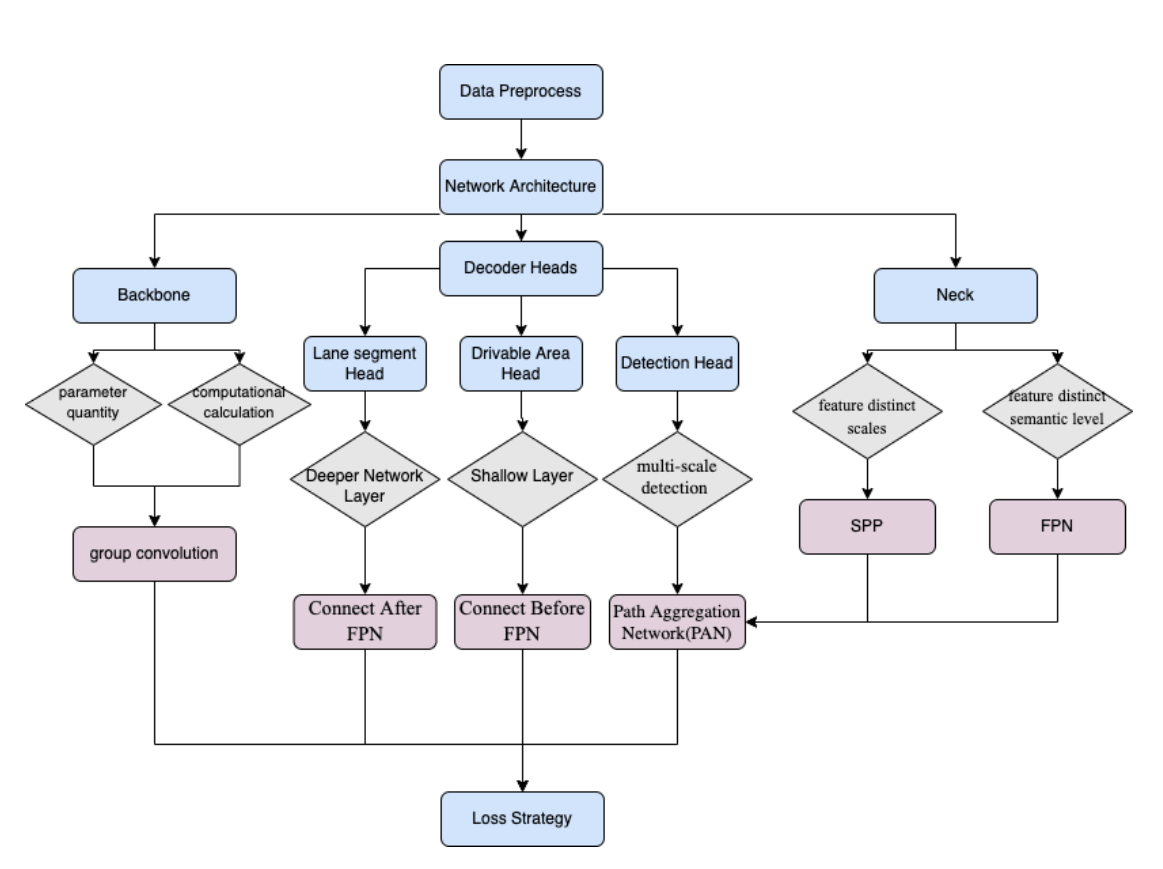
셋째, 멀티테스크에 대한 방법론
아시다시피 국내 뿐만 아니라 세계 어디에서든 운전은 나만 잘한다고 안전하게 할 수 있는 것이 아니죠. 나도 잘하고, 상대방도 잘하고, 우리 모두가 잘해야 도로위는 안전합니다. 말하자면, 도로의 상황은 정적인 그림이 아니라 예측하기 어렵게 시시각각 변화합니다. multitask은 그래서 필연적입니다.
YOLOPv2의 연구진들은 멀티테스크의 supervisory signals을 통해 shared representations들을 network가 잘 학습하도록 만들려고 시도했습니다. Mask RCNN, Faster RCNN, ResNet의 기법들이 쓰였구요. 우리가 익히 아는 residual block을 인스턴스 세그멘테이션과 객체 탐지에 응용하기도 했습니다. YOLOP는 feature extraction을 통한 인코더. 특정 task를 위해 processing하는 세 개의 헤드, multi-task processing을 가져왔습니다. 여기서도 LSNet의 구조, cross-IOU의 loss, MultiNet에서의 영향(한개의 인코더를 세 개의 분리된 디코더가 공유), HybridNet의 Bifpn 등 다양한 기법을 조합시키려 합니다.
Mask RCNN과 Faster RCNN의 간단한 이미지


마지막, BOF(bag of freebies)를 통한 낮은 cost
윗부분에서 BOF도 신개념으로 언급되었다고 말했습니다만, Freebies 자체는 공짜 사은품, 덤 같은 뜻으로 쓰이는 용어입니다. 이마트에서 만두를 사면 붙어있는 조그만 만두라고 생각하면 되겠네요. bag of freebies는 공짜 백이라고 보면 되겠습니다. 여기서는 '가성비'를 필요로 하는데요. 일반적으로 신경망을 통한 추론이나 탐지에는 loss, 손실 내지 cost가 붙습니다. 그리고 이를 최소화 하는 것이 대부분의 목표이구요. 연구진들은 객체 탐지의 결과에 있어 추론의 코스트는 최소화하면서 (증가량을 최소화) 정확도는 올리고자 합니다. 이때 통상적으로 학습 단계와 검증 단계를 분리하게 되는데요. 이때, 데이터 augmentation을 입력 이미지의 다양성을 높이기 위해 사용하는데, 이는 구현된 객체 탐지 모델이 다른 도메인을 넘어서 일반화하게 됩니다. 이런 예로는 정상 이미지의 mirroring, 이미지 밝기 수정, 대비, 색조, 채도, 노이즈(yolop를 사용함) 방법 등이 존재합니다. 이러한 데이터 증강은 조정된 영역안에서 모든 픽셀 정보를 바뀌지 않게 하고, 모든 픽셀 레벨의 조정과 같습니다. 또, YOLO 시리즈들은 여러개의 이미지들을 위해 데이터 증강을 동시에 진행하는 것을 추천하고 있습니다. 예로, 모자이크 어그멘테이션(이미지를 4개의 부분으로 붙이고, 배치 사이즈와 데이터의 분산을 높이는 것)도 있네요.
Bag of freebies라는 집합안에 있는 여섯가지 기법들
1. mixup
2. Classification Head Label smoothing
3. Data Augmentation
4. Training Schedule Revamping
5. Synchronized Batch Normalization
6. Random Shapes Training for Single-Stage object detection networks
YOLOPv2에서 제시한 기법들에 대한 정리
YOLOP에서의 객체 탐지시 LOSS
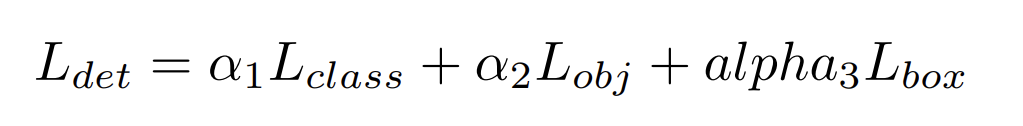
이때 \(L_{det}\) 는 객체 탐지시의 손실값으로, 가중치 합에 대한 손실의 총합입니다.
아래부터, Dice loss는 불균형한 Voxel(volume + pixel) 문제를 완화시키는데, class distribution을 학습할 수 있게 합니다.
Focal loss는 모델이 classified voxel이 부족해도 학습할 수 있게 합니다. 이는 아래 수식을 통해 최종 loss을 계산하도록 나타낼 수 있습니다.
이때, TP와 FN, FP는 우리가 Confusion matrix에서 자주 보았던 바로 그 개념들입니다. (혼동행렬과 귀무가설 게시글 참조)
\(L_{Focal}\)가 Focal loss로, 어렵거나 쉽게 오분류되는 케이스에 대해서 더 많은 가중치를 주는 일종의 손실함수입니다.
\(L_{Dice}\)는 Dice score를 활용한 dice loss입니다.
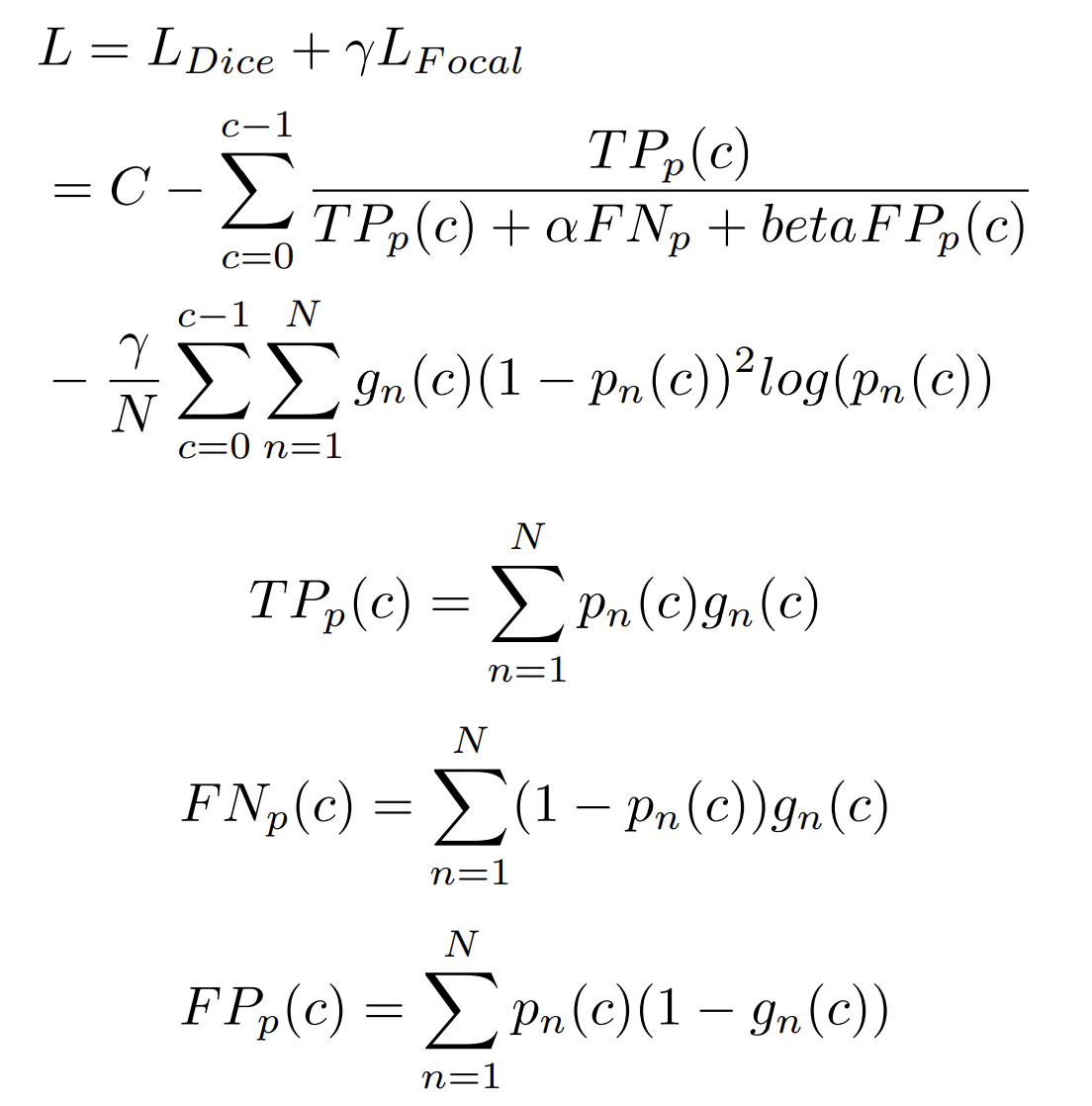
위와 같은 연구를 총합해서 객체 탐지는 교통 장애물의 정보와 위치에 대한 정보도 제공하고, 운전중에 발생하는 신속한 판단과 정확도를 높이도록 돕는 역할을 합니다. 또, 주행가능한 구역 세그먼트(area segment)와 레인 세그먼트(lane segment)를 제공하여 길찾기 성능과 안전성을 높이는데 많은 정보를 제공합니다.
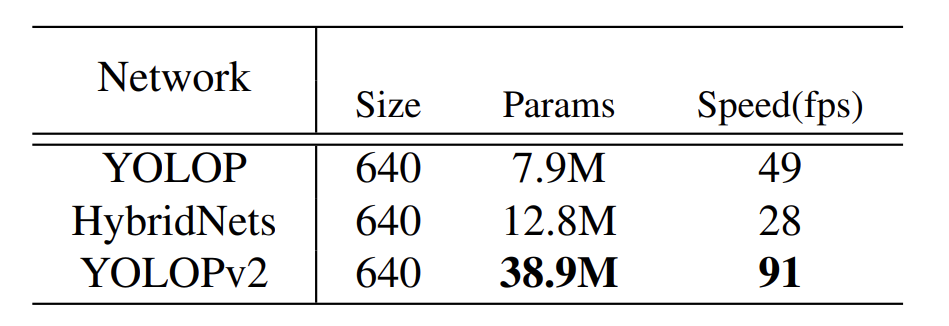
fps를 기준으로 채점한 YOLOPv2의 성능
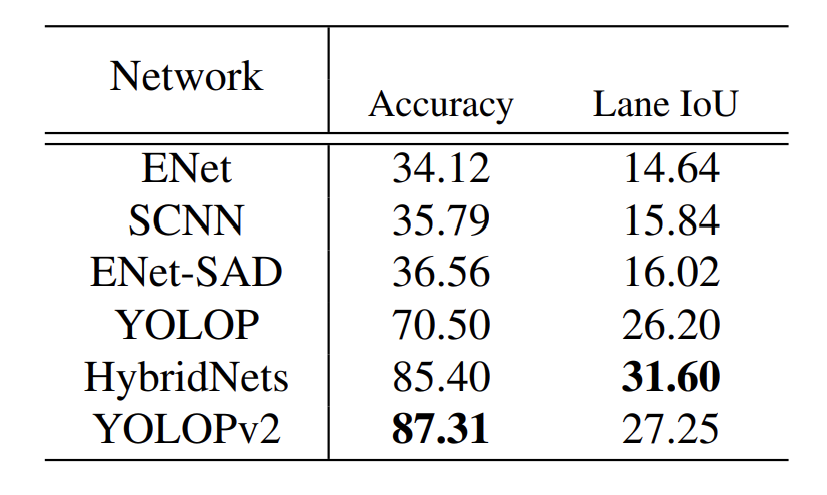
주행가능영역에서의 mIOU입니다.

레인 인식에서의 비교군입니다.
연구의 토대들로 보면 YOLOPv2에 대한 연구는 다양한 RNN, CNN들의 통합이라는 느낌이 강합니다.
연구방향은 YOLOP, HybridNet 등 이미 지나온 연구들을 기초로 하고 있습니다. YOLOPv2 모델은 이 두가지에 영향받아 코어 설계 컨셉을 잡았고, 뿐만아니라 피쳐 추출을 위한 강력한 backborn을 활용하여 자율주행 모델에 적용합니다. 또, 기존의 연구물과 다르게, 개발진들은 3개의 디코더 헤드를 branch로 잡아 더 동일한 branch의 주행가능 영역 세그멘테이션과 레인 디텍션을 운영하는것 외에도 중요한 테스크를 진행합니다. 왜 이렇게 시도했을까요. 이들은 트래픽 영역(traffic area) 세그멘테이션과 레인 탐지가 기본적으로 다른것을 인지하고, 두가지의 피쳐 레벨(feature level)을 상이한 신경망 구조로 넣는 것이 필요하다고 생각했기 때문입니다.
이상으로, 이번 논문 리뷰는 마치도록 하겠습니다.
다음 시간에도 또 새로운 최신 기술에 대해서 살펴보도록 하겠습니다!
Reference
YOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception 원논문(서론 링크 존재)
CAIC-AD/YOLOPv2: YOLOPv2: Better, Faster, Stronger for Panoptic driving Perception (github.com)
[1708.04485] SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks (arxiv.org)
[1505.04597] U-Net: Convolutional Networks for Biomedical Image Segmentation (arxiv.org)
Review — Bag of Freebies for Training Object Detection Neural Networks | by Sik-Ho Tsang | Medium
'딥러닝 > 신규 모델&기술 설명' 카테고리의 다른 글
| [논문 리뷰] residual proposal network를 사용해서 한층 빨라진 객체 탐지, Faster R-CNN (0) | 2023.03.18 |
|---|---|
| [논문 리뷰] GAN에서 한 발짝 앞서서, PGAN(Progressive-GAN) 기술 분석 (2) | 2023.03.11 |
| [DeepLearning] YOLOv 모델, you only look once 논문 분석 (0) | 2023.02.27 |
| [DeepLearning] IRB에 관하여 (0) | 2023.02.15 |
| [DeepLearning] LA-MCTS에 관하여 (0) | 2023.02.14 |



