
서론
바로 지난시간에 이어서, 미국의 자치구별 초소형 기업의 밀도에 대한 분석 데이터입니다.
같은 데이터를 그대로 이어서 사용했고 표준화 스케일링을 진행한 상태입니다.
이번엔 KNN 모델을 사용해서 회귀 문제를 제시해보았는데요?
* K-Nearest Neighbors Regressor
이때 KNN모델이란, 주변의 가장 인접한(Nearst) 이웃의(Neighbors)
K개의 샘플을 이용해서 임의의 값을 예측하는 방식을 의미합니다.
K가 5개일 경우, 5개의 가장 가까웃 이웃을 찾아 평균을 계산해서 값을 예측합니다.
지난번에는 KNN모델의 분류문제를 해결하는데 사용했었죠?
[Machine Learning] KNN 알고리즘 실습사례_wine 분류
KNN Algorithm 간단하게 시작하자면 K개의 이웃(Neighbors)한 점들을 인접한(Nearest) 영역에서 포집시키는 방법입니다. KNN 알고리즘은 비교적 합리적이고 유용한 방식은 아니지만, 빠르고 쉬우며 분류나
astart.tistory.com
주로 분류문제에서 사용되지만, 회귀문제도 예측이 가능합니다.
먼저, 지난 시간에 분리했던, 독립변수 X입니다.
X # 확인
X의 컬럼이 다 보이지 않아 따로 뽑은 코드입니다.
X.columnsIndex(['active', 'pct_bb_2017', 'pct_bb_2018', 'pct_bb_2019', 'pct_bb_2020',
'pct_bb_2021', 'pct_college_2017', 'pct_college_2018',
'pct_college_2019', 'pct_college_2020', 'pct_college_2021',
'pct_foreign_born_2017', 'pct_foreign_born_2018',
'pct_foreign_born_2019', 'pct_foreign_born_2020',
'pct_foreign_born_2021', 'pct_it_workers_2017', 'pct_it_workers_2018',
'pct_it_workers_2019', 'pct_it_workers_2020', 'pct_it_workers_2021',
'median_hh_inc_2017', 'median_hh_inc_2018', 'median_hh_inc_2019',
'median_hh_inc_2020'],
dtype='object')
종속변수 y는 초소형 기업의 밀도인 density를 따로 뽑았었습니다.
y = the_new_train['microbusiness_density']
다시 돌아가서, KNN 모델을 호출해주고, 적용시켜줍니다.
필자는 한 개의 Colab 파일에서 모두 진행했기 때문에, 초기 과정에서
모든 패키지를 전부 호출했었습니다.
from sklearn.neighbors import KNeighborsRegressorknn = KNeighborsRegressor()
knn.fit(X_trainst, y_train)
pred = knn.predict(X_testst)
예측치는 행의 길이가 긴 관계로 생략합니다.
pred # 예측치
이제 테이블로 실제값과 pred를 평가해서 점과 선이 함께 있는 regplot으로
쫙 펼칠 예정입니다.
# 테이블로 평가
comparison = pd.DataFrame({
'actual': y_test, # 실제값
'pred': pred
})
comparison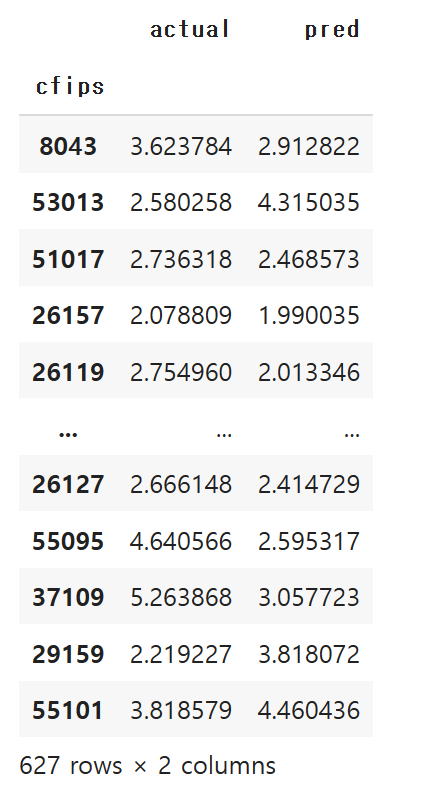
그래프로 시각화합니다.
# regplot 제작
plt.figure(figsize=(10, 7))
sns.regplot(x = 'actual', y= 'pred', data = comparison)
plt.show()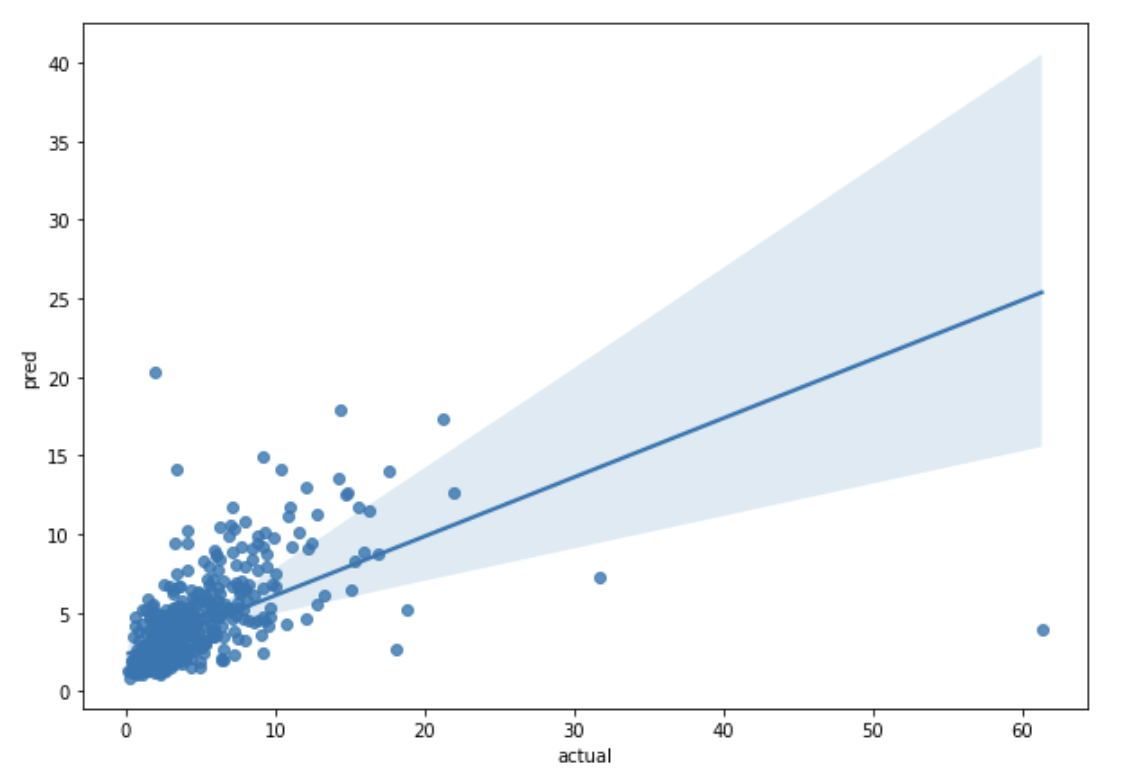
평가지표로는 mse, rmse, mae, R²을 사용했습니다.
평가지표에 관련된 안내는 2주전 [결정계수에 관하여] 편에서 서술한 바 있습니다.
결론적으로 R²을 구하는 것이 목표인데 0~1사이의 유리수에서 1에 가까울수록
예측이 높은 정확도를 갖는 것이라고 판단할 수 있었습니다.
선형회귀 ep2. 결정계수에 관하여
지난 글에서와 같이, 선형회귀에서는 예측값과 실제값 사이의 차이, 즉 오차들을 보고 모델의 성능을 결정한다고 언급했습니다. 이번에는 이 오차들에 대한 부분입니다. SSR과 SST에 대한 용어는
astart.tistory.com
# mse 평가
mean_squared_error(y_test, pred) # 에러가 더 늘어남11.200077812576886
# rmse 평가
mean_squared_error(y_test, pred, squared=False)3.3466517315933677
# mae 평가
mean_absolute_error(y_test, pred)1.5145651904976076
model.score(X_trainst, y_train) # R^20.19693808002268087
일단 특별한 효과가 없습니다.
다른 모델을 소환해봅니다.
LightGBM 시도
지난번에도 활용한 LightGBM은 역시 부스팅계열 모델에서 xgboost보다도
사용감이 좋아서 안된다 싶으면 사용하는 편입니다.
import lightgbm as lgb
n_estimators, learning_rate를 비롯해 패러미터를 미리 선언해줍니다.
# 사용할 params정의
params = {"n_estimators" : [100, 500, 1000],"learning_rate" : [0.01, 0.05, 0.1, 0.3]
,"lambda_l1" : [0, 10, 20],"lambda_l2" : [0, 10, 20],"max_depth" : [5, 10, 15, 20],"subsample": [0.6, 0.8, 1]}
# LigthGBM 사용
model = lgb.LGBMRegressor(random_state = 100)
하이퍼 패러미터 튜닝에는 몇가지 고려를 했으나, 일단 결과값을
잘 뽑는 것이 목적이기 때문에 GridsearchCV와 RandomsearchCV를 고려했습니다.
이번에는 시간 최적화를 위해 후자를 사용했습니다.
# 하이퍼패러미터 튜닝?
# 랜덤서치cv 사용 - n_iter와 scoring :기본 세팅만 하고 cv를 따로 지정
new_train_model = RandomizedSearchCV(model,
param_distributions = params,
cv = 20,
random_state=100, n_jobs = -1)
이부분에서 필자가 따로 계산해 보았지만, n_iter을 따로 설정하면
시간이 기하급수적으로 늘어나고, scoring을 따로 설정하면 best score가 매우 낮거나
nan으로 뜨는 사태가 발생했습니다.
일단 cv(분할할 세트 갯수)부분만 조정했습니다. (수치는3→5→9→20)
new_train_modelRandomizedSearchCV(cv=20, estimator=LGBMRegressor(random_state=100), n_jobs=-1,
param_distributions={'lambda_l1': [0, 10, 20],
'lambda_l2': [0, 10, 20],
'learning_rate': [0.01, 0.05, 0.1, 0.3],
'max_depth': [5, 10, 15, 20],
'n_estimators': [100, 500, 1000],
'subsample': [0.6, 0.8, 1]},
random_state=100)
new_train_model.fit(X_trainst, y_train) # 시간 소요 체크RandomizedSearchCV(cv=20, estimator=LGBMRegressor(random_state=100), n_jobs=-1,
param_distributions={'lambda_l1': [0, 10, 20],
'lambda_l2': [0, 10, 20],
'learning_rate': [0.01, 0.05, 0.1, 0.3],
'max_depth': [5, 10, 15, 20],
'n_estimators': [100, 500, 1000],
'subsample': [0.6, 0.8, 1]},
random_state=100)
추가적으로 시간을 확인했습니다. cv가 3일때는 52초, cv가 5일때는 55초,
cv가 9일때는 1분 38초, cv가 20일때는 3분 34초가 소요됬습니다. (colab 기준)
이 시간단위는 훗날에도 패러미터 튜닝을 사용할 때 기준점으로 삼으려 합니다.
new_train_model.best_params_ # 최적의 패러미터를 계산{'subsample': 1,
'n_estimators': 500,
'max_depth': 20,
'learning_rate': 0.01,
'lambda_l2': 20,
'lambda_l1': 10}
best_score도 계산해 봤습니다.
new_train_model.best_score_ # 최적의 점수계산
# cv 9일때 0.3760.4703737277864305
필자가 따로 계산해 봤습니다! cv 수가 9일때는 0.376으로 조회됬었습니다.
searchcv 계열은 모두 cv_results_ 기능을 제공합니다.
세트별로 성능의 점수와 시간들을 계산해줍니다.
# CV의 result
new_train_model.cv_results_
시리즈를 줄여서, 데이터프레임으로 조회했습니다.
# CV의 result - DF 추가
cv_result = pd.DataFrame(new_train_model.cv_results_)
cv_result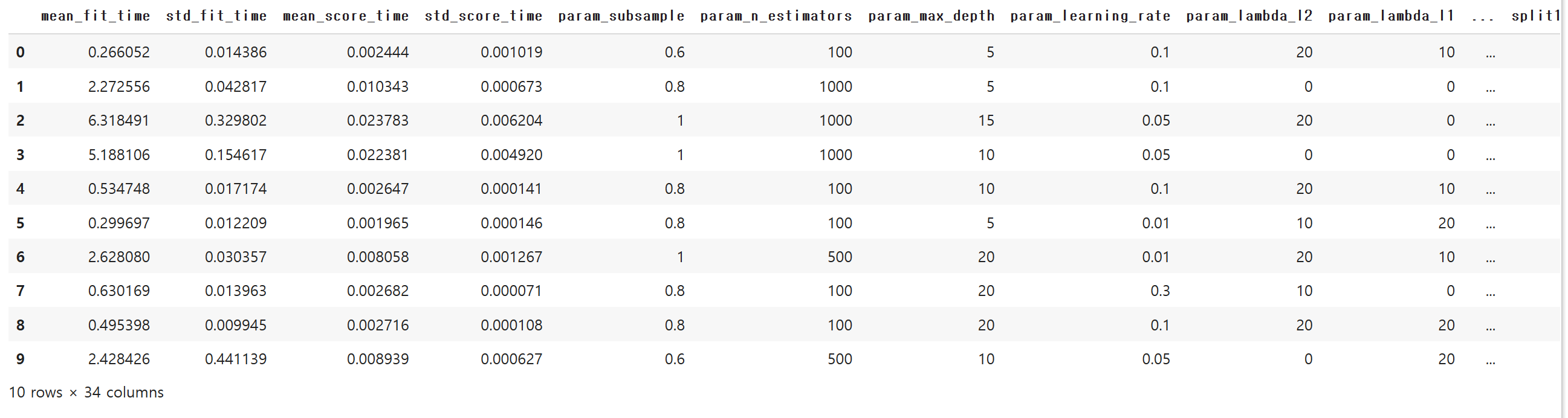
rank_test_score는 세트에 대해 수행된 성능들의 평균값을 바탕으로 한 평가 순위입니다.
이를 기준으로 다시 정렬해볼까요.
col1=cv_result.columns[33:].to_list()
col2=cv_result.columns[:33].to_list()
new_col=col1+col2
cv_result=cv_result[new_col]
cv_result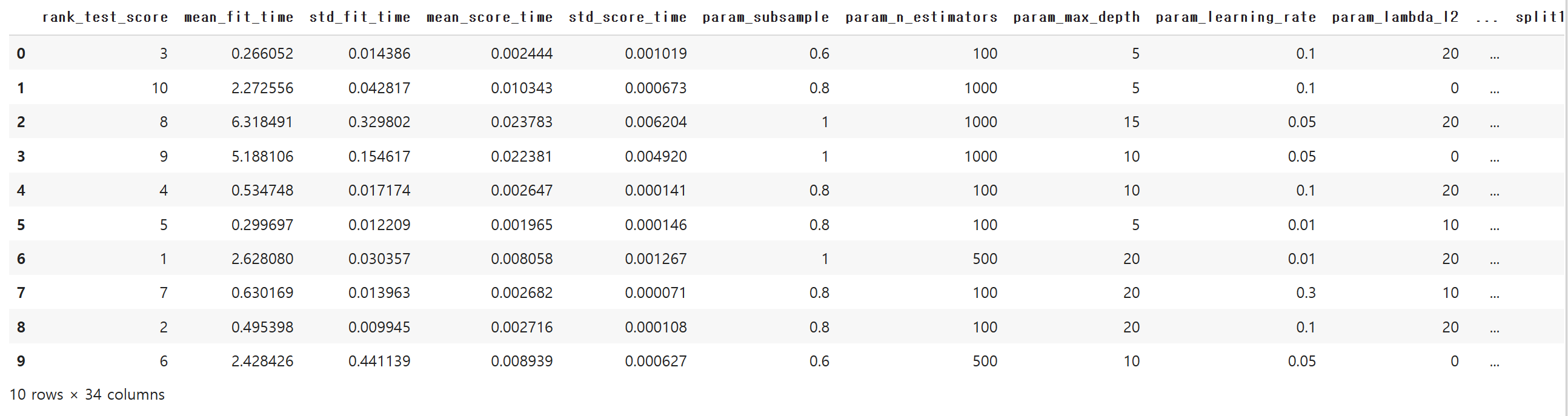
cv_result = cv_result.sort_values('rank_test_score')
cv_result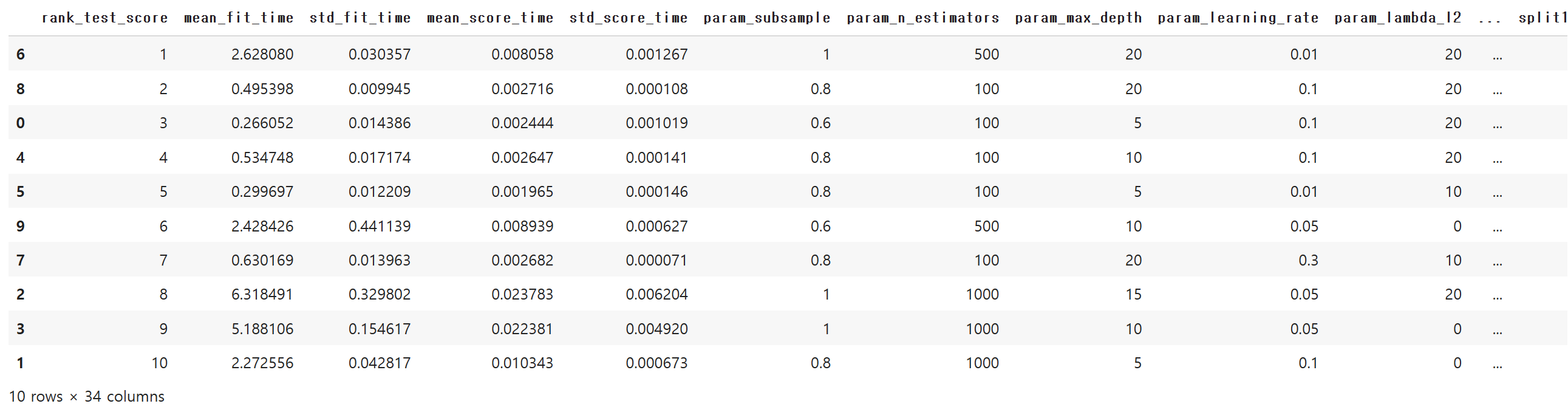
best_params_ 이외의 결과들도 보여줍니다.
12.31. 분석 종료
'머신러닝 > 지도학습' 카테고리의 다른 글
| [Feature engineering] 데이터 처리 사례_2021 서울시 농산물 가격 분석_2 (0) | 2023.01.02 |
|---|---|
| [Feature engineering] 데이터 처리 사례_2021 서울시 농산물 가격 분석_1 (0) | 2023.01.01 |
| [Machine Learning] Kaggle_데이터셋 분석_미 초소형 기업 밀도 예측 (0) | 2022.12.30 |
| [Machine Learning] Kaggle_데이터셋 분석_Video_Games_Sales.1 (0) | 2022.12.29 |
| [Machine Learning] Kaggle_연습사례 분석_Spaceship_titanic_2 (0) | 2022.12.28 |



