
서론
이번 시간에는 사이드 프로젝트로 진행했던 2021년의 서울시 먹거리 가격정보에 대한
데이터셋으로 데이터 인사이트 및 전처리를 진행해볼 예정입니다.
출처는 서울 열린데이터 광장(https://data.seoul.go.kr/)에서 농수축산물 가격 정보를
열람했습니다. 추가적으로, 열린 데이터 광장은 인공지능 개발을 위한 공공 학습 데이터,
시민을 위한 열린 데이터를 손쉽게 활용할 수 있도록 무료로 공개하여 더 많은 연구 자료가
발전할 수 있도록 노력하고 있습니다.
독자분들도 실습을 위한 학습 데이터셋이 필요할 때, kaggle에서 영어 데이터만 읽는 것도
지쳤다면, 서울 열린데이터 광장도 추천 드립니다. 한글인 점이 매우 마음에 드네요.
시작하기에 앞서, 사용한 학습 종류는 지도학습의 회귀(Regression)모델이며,
분석에 앞서서 선형회귀 전까지 진행할 예정입니다.
차후에는 Ridge회귀, Lasso회귀, Elasticnet 회귀, LightGBM 회귀 모델링을 통해,
평균 RMSE값을 낮추는 방법을 진행할 예정입니다.
목표(Target)은 2021년 6월 이후의 각 농, 축수산물 품목별 price 에 대한 예측이며,
지역은 서울특별시 내부로만 한정됩니다. 독립변수는 price외의 피쳐들로 서울시 25개
자치구, 시장유형, 품목, 마트종류 등으로 구성됩니다.
먼저 분석 활동에 필요한 각종 라이브러리와 패키지를 호출해줍니다.
# 필요한 라이브러리 호출
# 기초
import numpy as np
import pandas as pd
# 시각화
import seaborn as sns
import matplotlib.pyplot as plt
from plotly import graph_objects as go
from plotly import express as px
# 사이킷런 분류
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import GridSearchCV
# 지도학습
# 회귀 종류
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import Lasso, ElasticNet
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
# 경고메시지 무시
import warnings
warnings.filterwarnings(action='ignore')
# 평가용
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
만약, 한글이 깨지는 현상이 발생한다면?
Jupyter notebook 한글화 작업
시각화를 할 경우, 그래프 상에서 영어가 아닌 한글 문자열들은 '□□' '□□□' 처럼
깨지는 경우가 발생합니다. 그럴 경우에는 아래 작업을 통해, 나눔바른고딕을 설치하고
넣어서, 한글의 깨짐현상을 해결할 수 있습니다.
import matplotlib.pyplot as plt
# 한글화 작업
plt.rc('font', family='NanumBarunGothic')
# 따로 구분해도 되고, 안해도 무방합니다.
plt.rcParams['font.family'] = 'NanumGothic'
간단한 시각화
# 잠깐 시각화
plt.figure(figsize=(12,7))
sns.countplot(data=df.head(6).sort_values(by = '품목 이름', ascending = True))
한글이 정상적으로 찍히는 것을 볼 수 있습니다.
다시 돌아와서, 앞서 제시했던 서울시 데이터광장에서 받은 파일을 로드해줍니다.
필자는 미리 다운받아놓은 상태입니다.
df = pd.read_csv('C:/myPyCode/data/2021_물가/생필품_농수축산물_가격_정보(2021년).csv', encoding = 'cp949')
df
몇가지 object로 된 컬럼이나 신경써야 할 특이사항이 있는지 확인해봅니다.
df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 89899 entries, 1636107 to 1724779
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 시장/마트 번호 89899 non-null int64
1 시장/마트 이름 89899 non-null object
2 품목 번호 89899 non-null int64
3 품목 이름 89855 non-null object
4 가격(원) 89899 non-null int64
5 년도-월 89899 non-null object
6 시장유형 구분(시장/마트) 코드 89899 non-null int64
7 시장유형 구분(시장/마트) 이름 89899 non-null object
8 자치구 코드 89899 non-null int64
9 자치구 이름 89899 non-null object
10 점검일자 89899 non-null object
dtypes: int64(5), object(6)
memory usage: 8.2+ MB
여기서 1열은 0열인 시장/마트 번호로 대응되고
3열은 2열인 품목 번호로 대응됩니다. 7번은 6번에 대응, 9번은 8번에 대응됩니다.
이런식으로 int형식인 컬럼을 남기려고 계획중입니다.
범주형 데이터를 one-hot encoding으로 더미데이터 변환할 수도 있지만
그 종류가 8만개가 넘어가고, 추후 중복을 제거해도 2만개가 넘어가는 수치라
남길 이유는 없었기 때문입니다.
통계적인 정보도 확인합니다.
df.describe()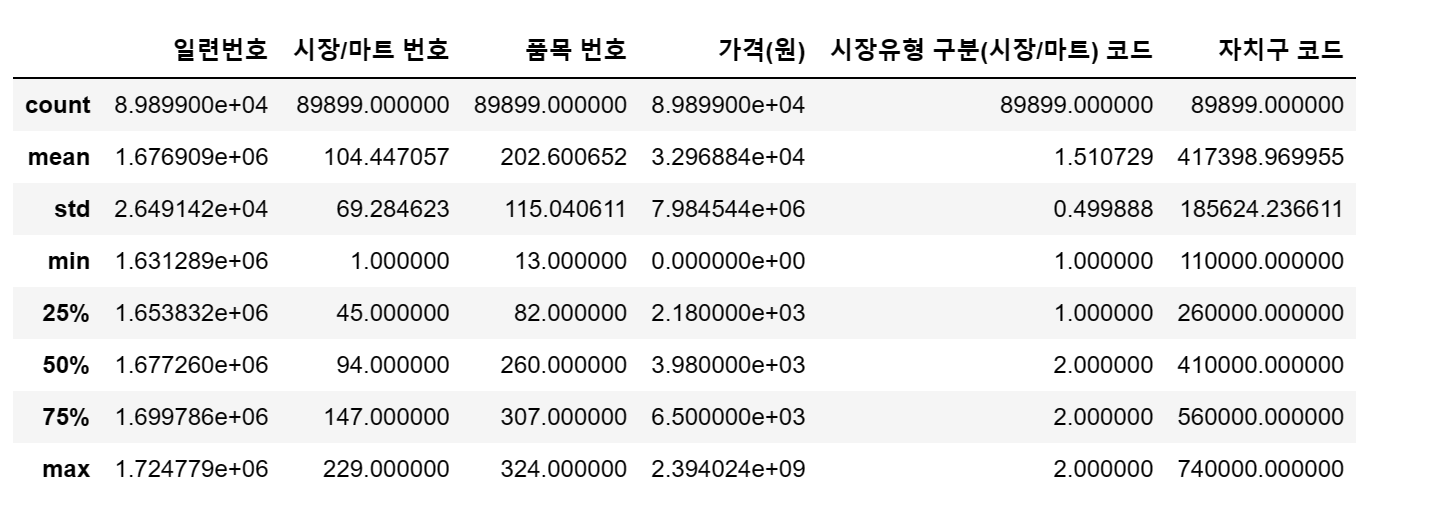
조사를 하던중, 일종의 통계담당자들의 메모장처럼 사용되던 부분이 있다는 것을
알수 있습니다. 바로 '비고' 컬럼입니다.
국내산 3마리, 수입산 3마리 등 규칙성이 전혀 없기 때문에 지워줍니다.
df.drop('비고',axis = 1, inplace = True)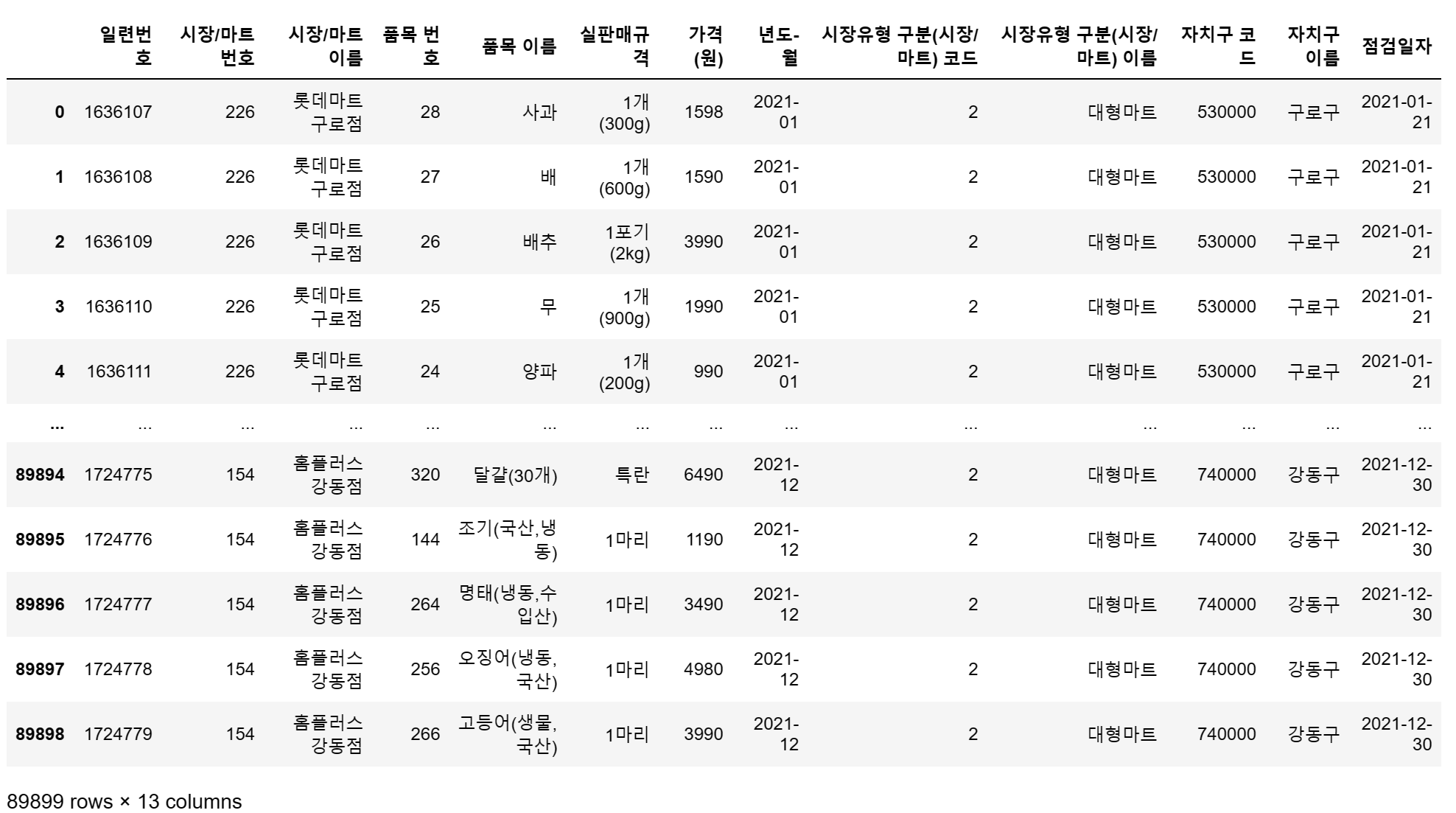
농수산물의 특징적인 부분입니다. 사과, 배, 양파처럼 다수로 묶어서 파는 상품이
있는 반면에, 조기, 명태처럼 한마리 단위로 파는 물건들도 있습니다.
심지어 쇠고기, 돼지고기 같은 품목은 단위가 gram수로 따지기 때문에 천차만별입니다.
이 모든 판매 규격들은 어떻게 처리해야 할까요?
따로 묶어줘야 할까요? 혹은 drop해야 할까요.
df.iloc[:,0:6].head(20)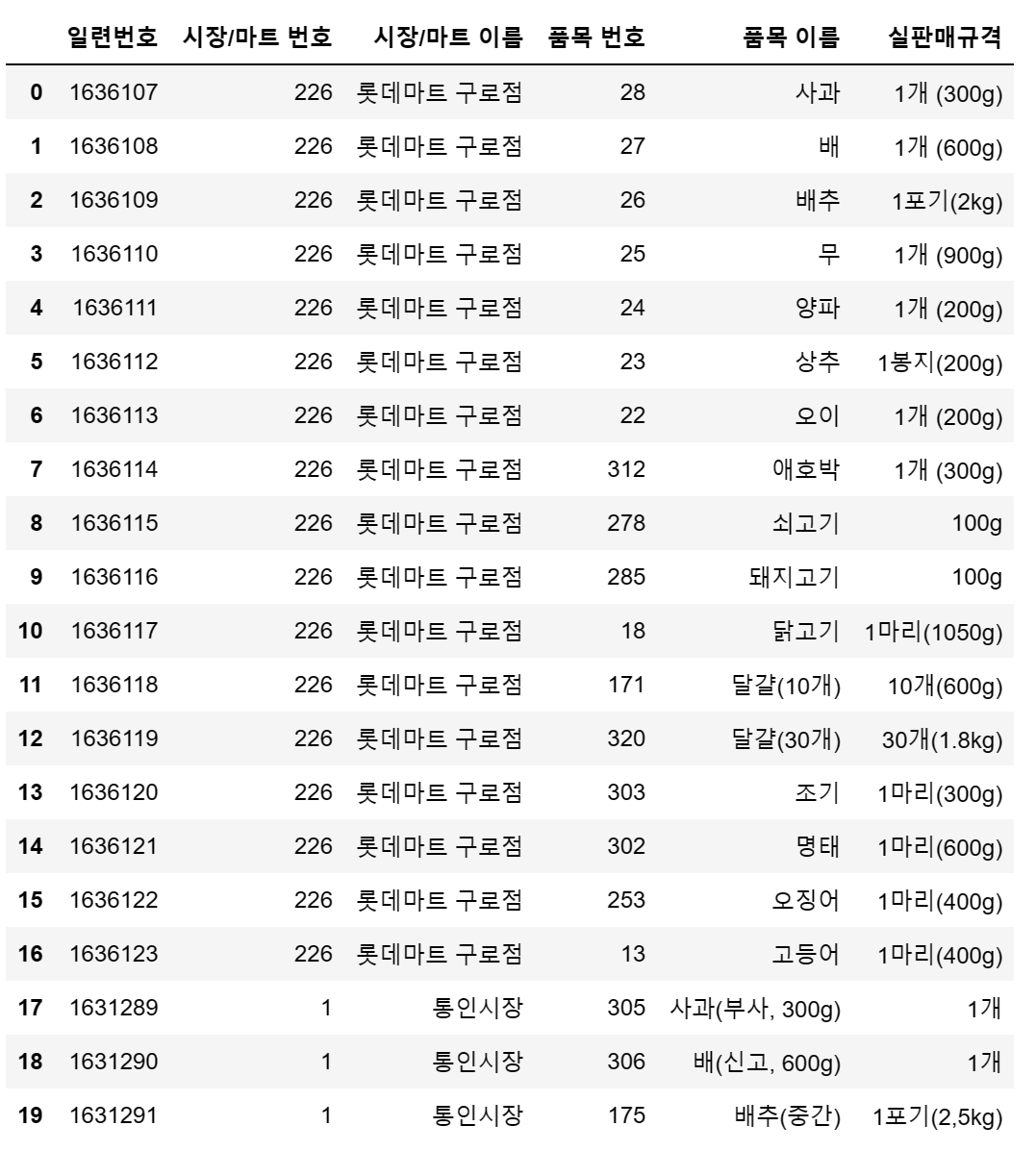
다른 컬럼들을 고려해본 결과, 품목 번호에 답이 있었습니다.
위를 주목해보면 같은 사과 1개라도 품목번호 28번 [사과]가 있는 반면에,
품목번호 305번 [사과]도 존재합니다. 이 부분에서 품목 이름도 지울 예정이기에
이름은 걱정하지 않아도 되지만 각 마트나 시장에서 따로 번호를 매긴 '품목 번호'가
존재한다는 점을 깨달았습니다. 때문에, 실판매규격도 같이 drop할 계획입니다.
df.drop('실판매규격', axis = 1, inplace = True)
실판매규격을 drop하고 다른 부분을 살펴봤습니다.
'일련번호 ' 컬럼이 눈에 띄는데, 다른 것과 유사한 품목이 있을까요.
df = df.set_index('일련번호')
df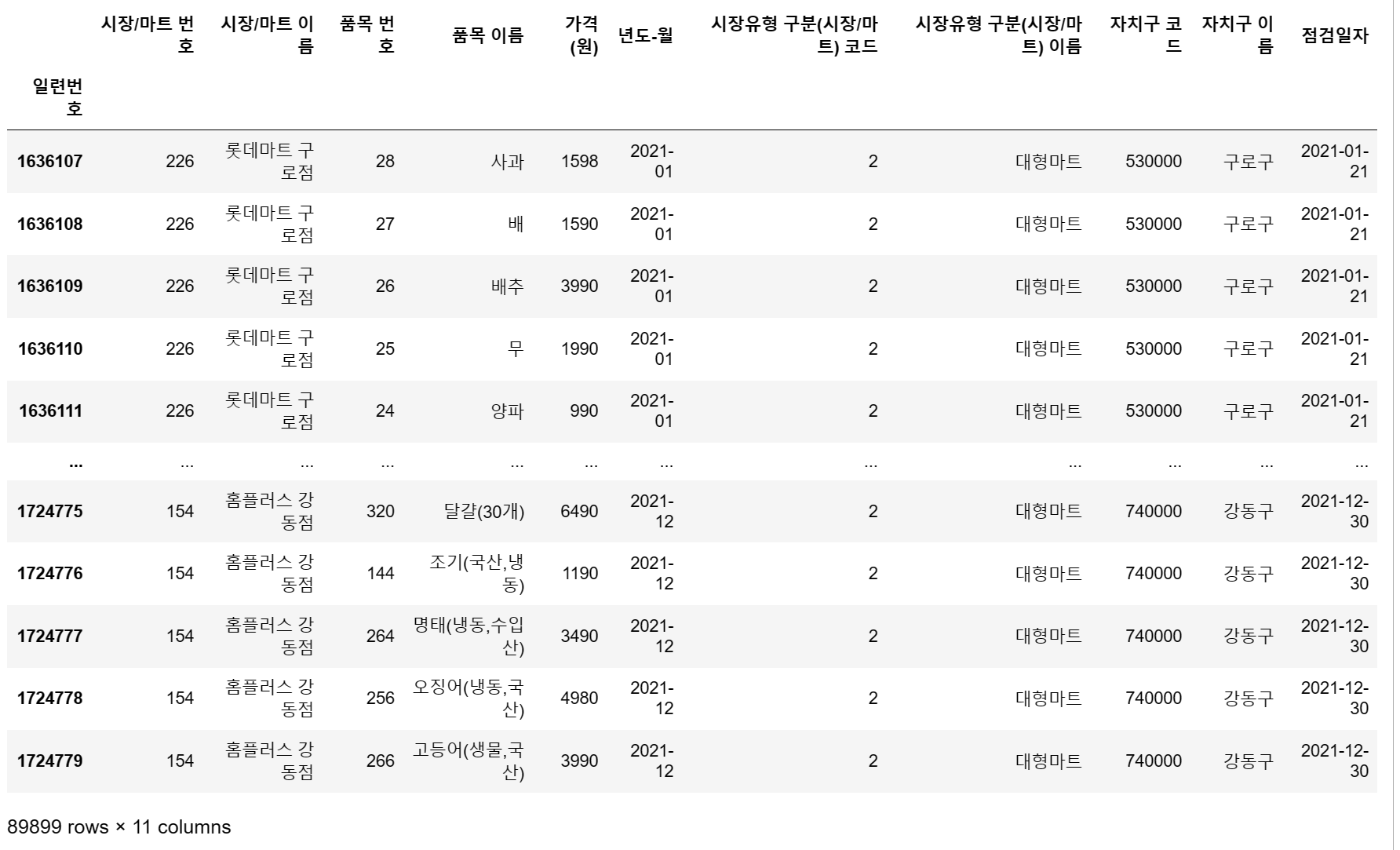
그런데 일련번호의 숫자가 1,2,3 처럼 1씩 증가하는데 비해, row의 숫자와 어딘가
다른점이 보입니다. 끝 번호가 1724779인데 1636107을 빼면 row의 총 갯수와
일치하나요?
1724779-163610788672
역시 어딘가 이상합니다.
drop_duplicates로 각 행별로 중복된 행들을 삭제해봅니다.
df2 = df.drop_duplicates() # 행 내용 전체가 중복된 경우 삭제
df2
# 실제로 삭제된 것은 데이터프레임에 모두 표시되지 않은 중복된 마트, 품목, 가격인 상품들인 것으로 예상
# 89899행 → 49187행
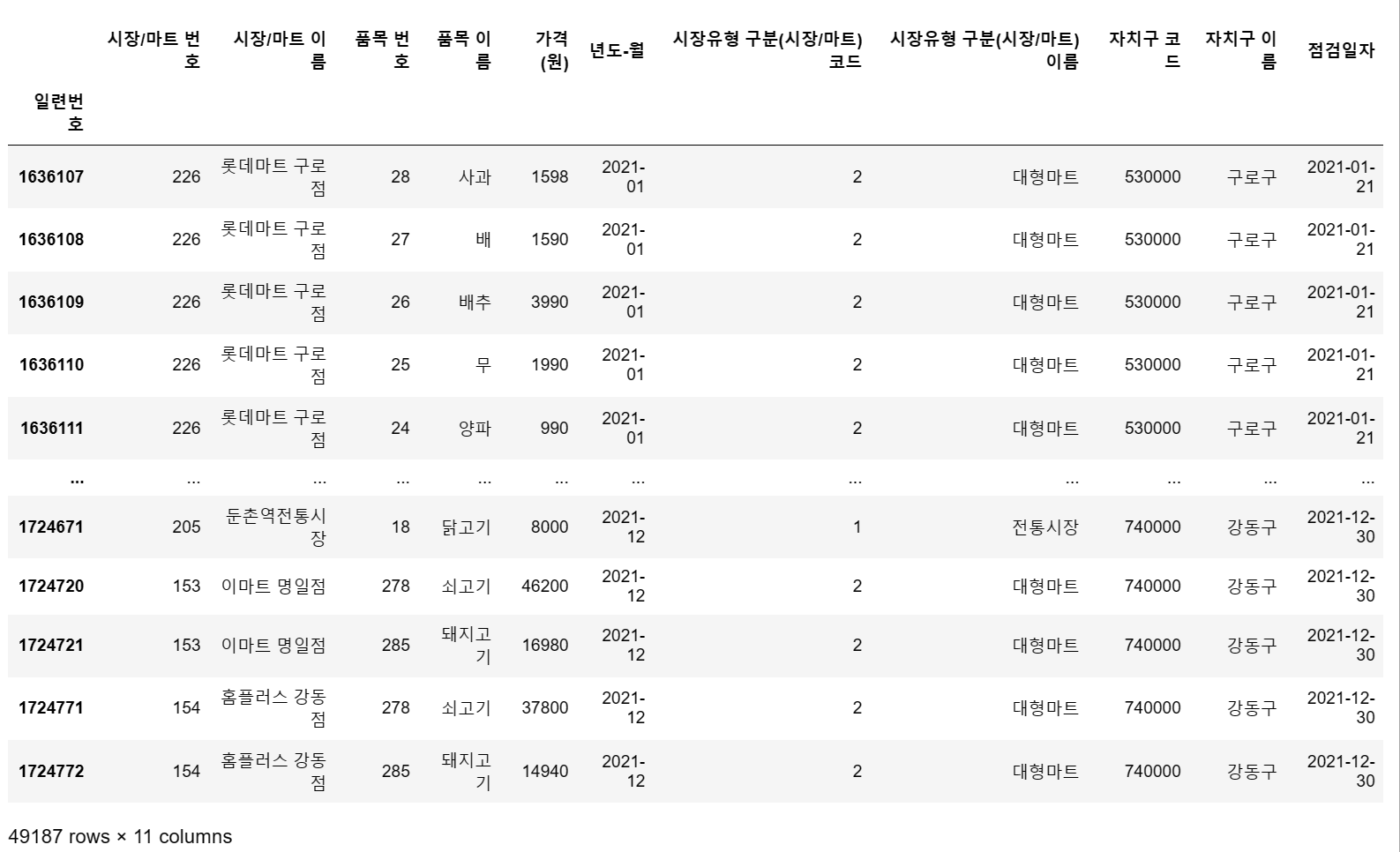
일단 혹시 몰라서 df2로 따로 선언해봅니다.
무려 4만여개에 가까운 행들이 삭제되었습니다.
이번에는 아까 일대일 대응되는 컬럼으로 확인했었던, 시장/마트 이름, 품목 이름,
자치구 이름 등을 제거해줍니다. 시장유형 구분은 시장이 1, 대형마트가 2로 구분되있습니다.
df2.drop(['시장/마트 이름','품목 이름','시장유형 구분(시장/마트) 이름','자치구 이름'], axis = 1, inplace = True)
# 행 삭제 주의df2.sort_values(by='품목 번호', ascending = True) # 품목번호 순서로 세팅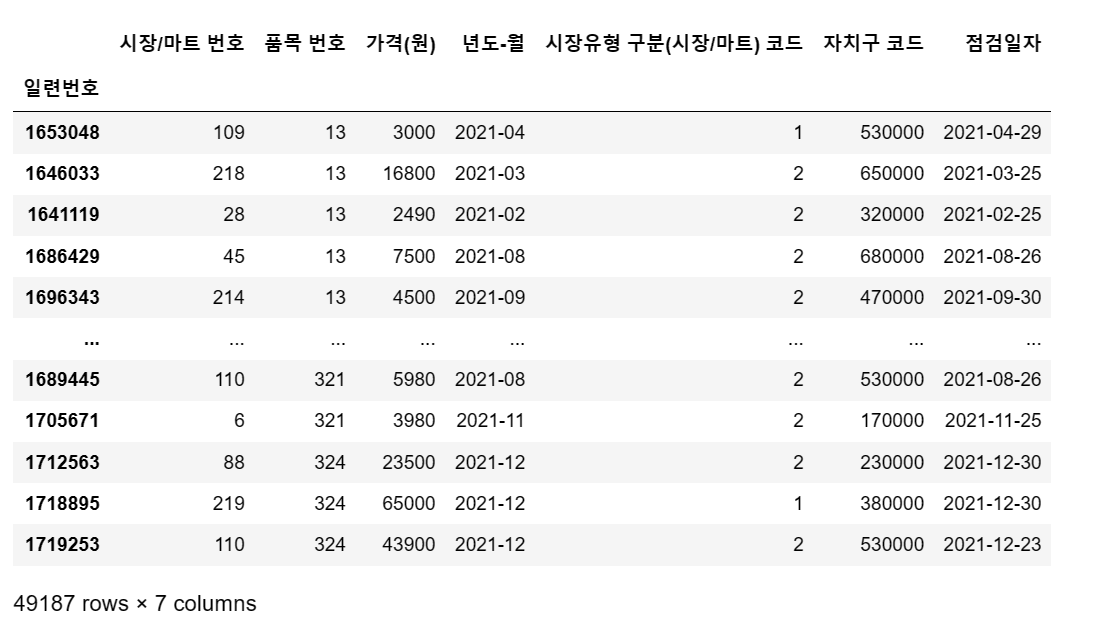
품목번호별로 오름차순 정렬했습니다.
필자가 미리 확인해본 상황에서, 가격에도 문제가 있습니다.
df3 = df2.sort_values(by='가격(원)', ascending = True)
df3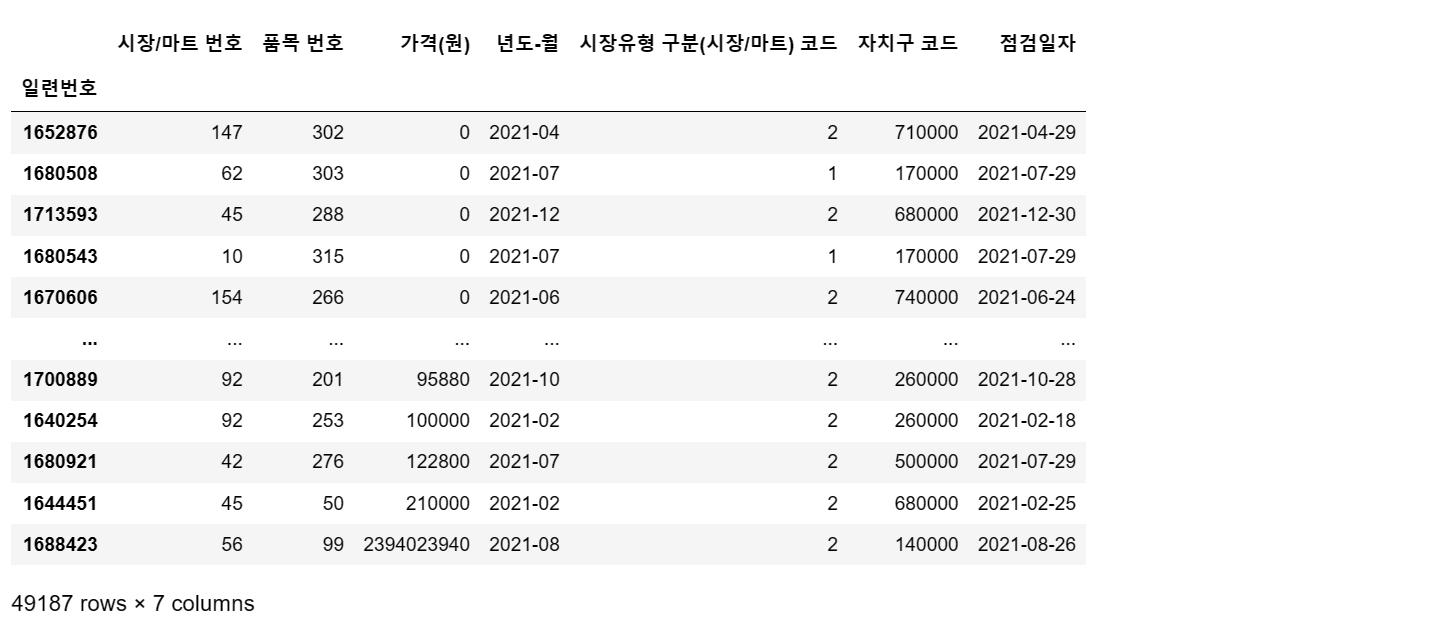
좋습니다. 시장에서 0원에 파는 물건들에는 무엇이 있을까요?
물론 없을것이라고 봅니다. 무료시식코너를 운영하지 않는한, 조사상의 결측치라고
봐야하겠습니다. 혹은 누락이겠지요.
반대로, 23억 9천만원의 상품이나 21만원짜리 먹거리는 어떤것이 있을까요?
이부분은 혹시나 희귀한 프리미엄 쇠고기나 고가의 참치 뱃살일 수도 있으니
삭제하는 것이 위험할 수도 있어 다시 확인해보았습니다.
마침, 지우지 않은 df의 데이터가 있었습니다.
df.sort_values(by='가격(원)', ascending = True) # 품목번호 순서로 세팅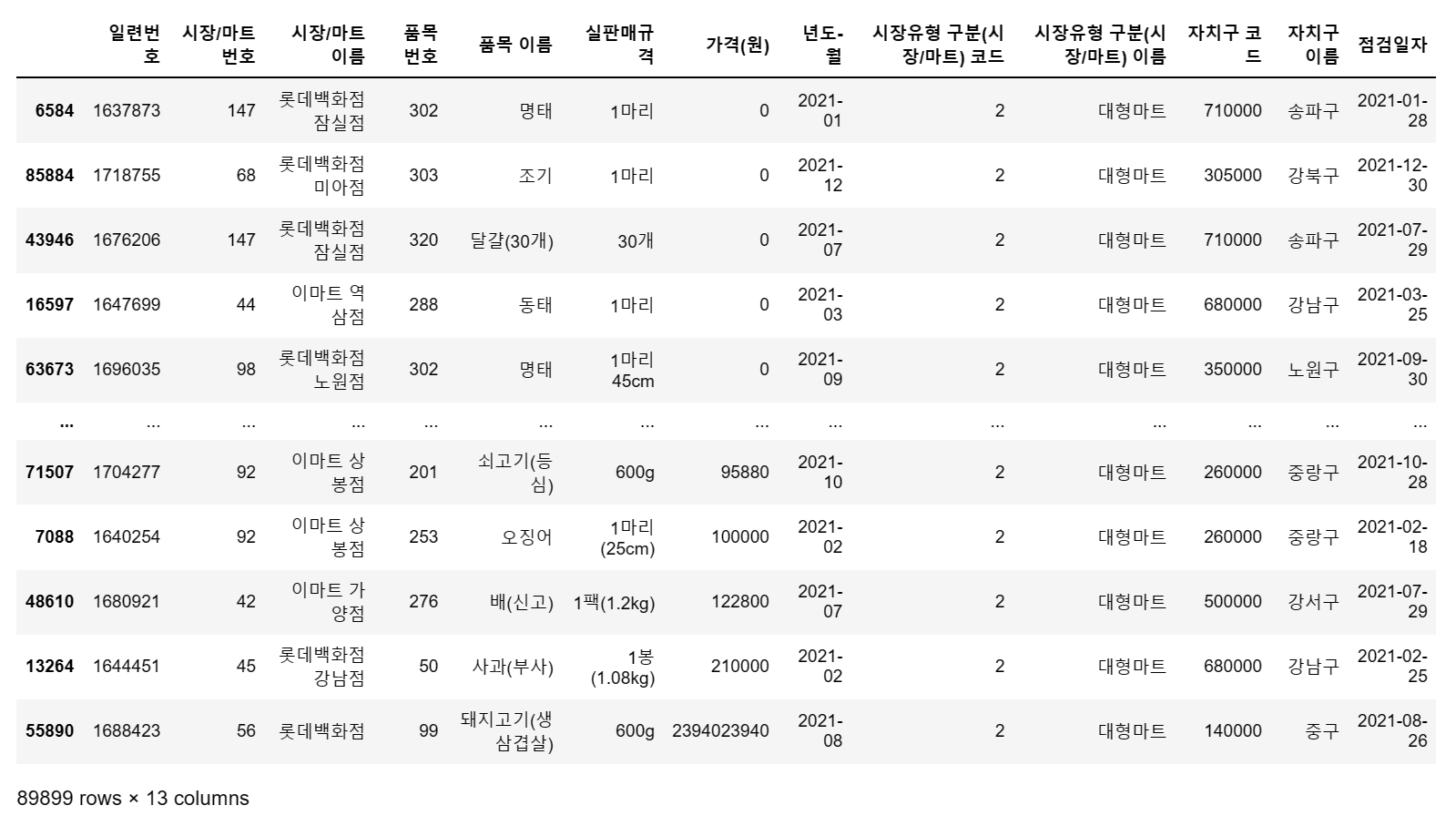
그렇습니다.
23억짜리 돼지고기 600g이라, 이건 귀하군요.
10만원짜리 오징어, 12만원의 배 1.2kg, 21만원 상당의 사과 1봉도 놀랍지만
23억의 돼지고기는 상상하기도 어렵습니다.
모두 오류로 보고 삭제해 줍니다.
df4 = df3.iloc[:49183] # 결측치 처리 대신 가격이 엄청 높은 상품들 처리
df4.info()
새로운 데이터프레임으로 선언하고, iloc으로 인덱싱했습니다.
마찬가지로, 0원으로 적혀있는 상품들도 처리해줍니다.
이과정에서는 0원짜리 상품이 총 몇개인지 알수 없기때문에,
value_counts()로 세줍니다.
df4['가격(원)'].value_counts().head(20) # 0원짜리 상품은 모두 몇개일까?4000 2071
3000 1790
2500 1596
5000 1521
2000 1490
3500 1342
1000 1137
1500 1117
6000 723
3980 678
4500 676
4980 531
7000 517
2980 515
3990 499
1980 487
6500 478
0 414
3300 403
7500 399
Name: 가격(원), dtype: int64
마침 414개인 것이 보입니다.
iloc로 행을 긁어줍니다.
df4 = df3.iloc[414:49183,:] # 0원 상품제거
df4
다음으로, 년도-월을 datetime 형식으로 바꿔줍니다.
바꿔주지 않으면 학습 시작할 때 error가 유발됩니다.
df4['년도-월'] = pd.to_datetime(df4['년도-월'])# 일련번호 삭제
# df4.reset_index()
df4.drop('일련번호', axis = 1, inplace = True) # 일련번호 삭제
#주의
df4 = df4.set_index('년도-월')
df4.sort_values(by='년도-월') # 데이터 전처리 1차 종료
# 스케일링을 할 정도의 규모인가?
df4.describe() # 특별한 이유는 없음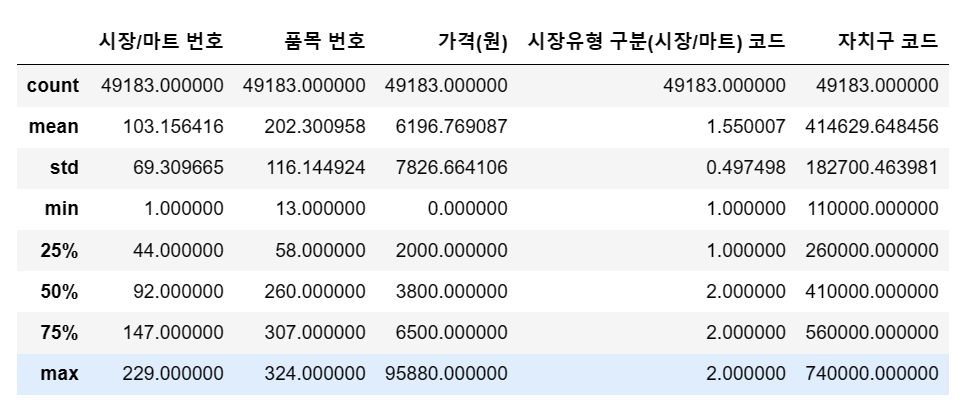
df4.indexDatetimeIndex(['2021-04-01', '2021-07-01', '2021-12-01', '2021-07-01',
'2021-06-01', '2021-06-01', '2021-02-01', '2021-03-01',
'2021-05-01', '2021-01-01',
...
'2021-11-01', '2021-10-01', '2021-11-01', '2021-09-01',
'2021-10-01', '2021-11-01', '2021-01-01', '2021-11-01',
'2021-09-01', '2021-10-01'],
dtype='datetime64[ns]', name='년도-월', length=49183, freq=None)
여기에는 날짜에 주목할만한 특징이 있습니다.
01-01, 01-02, 01-03 ~ 이렇게 아래로 내려갈수록 하루씩 날짜가 올라가는 것이 아니라,
04-01, 05-01 등 매월 1일만 날짜가 존재한다는 점이었습니다.
아마도 통계 조사원들이 매월 첫째주 첫날에 나가서 조사를 했던 것이
데이터에 영향을 미쳤다고 볼 수 있습니다.
여기서는 6월을 기준으로 훈련셋과 시험셋을 나눴습니다.
# 훈련데이터
train = df4[df4.index < '2021-06-01'] # 2021년 6월 1일 이전(1~2분기 이전 데이터)
# 테스트데이터
test = df4[df4.index >= '2021-06-01']# 2021년 6월 1일 이후(3~4분기 이전 데이터)
X_train = train.drop('가격(원)', axis=1)
y_train = train['가격(원)']
X_test = test.drop('가격(원)', axis=1)
y_test = test['가격(원)']중간정리
종속변수 y는 가격(원) 독립변수 X는 시장/마트 번호(어떤 마트인지를 나타냄),
품목 번호, 시장유형 구분(시장 vs 마트), 자치구 코드(행정구역)
model = LinearRegression()
model.fit(X_train, y_train)LinearRegression()
선형회귀 모델을 호출하고 적용했습니다.
pred = model.predict(X_test)
predarray([7246.39622378, 7246.39622378, 6144.37320598, ..., 6861.14490139,
6004.10072671, 6002.59845866])
# 테이블로 평가
comparison = pd.DataFrame({
'actual': y_test, # 실제값
'pred': pred
})
comparison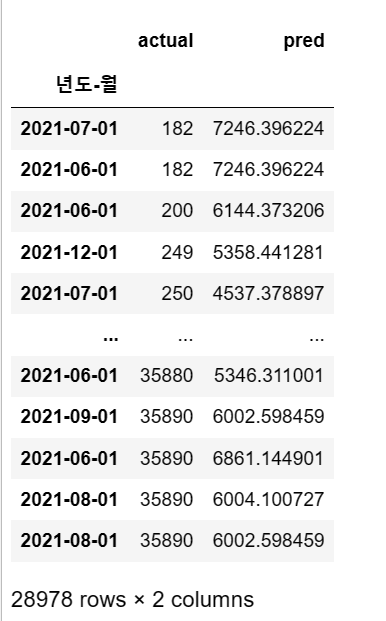
위에서 호출했던 에러 평가도 진행합니다.
# mse 평가
mean_squared_error(y_test, pred)65458879.83834545
# mae 평가
mean_absolute_error(y_test, pred)4850.060247195639
# rmse 평가
mean_squared_error(y_test, pred, squared=False)8090.666217212613
model.score(X_train, y_train) # R²
# 매우 낮은 결정계수0.02746799157007751
이 지점에서 그래프로 시각화까지 표현했으나, 근본적으로 예측값과 실제값의
관계를 예측하기 어려운 상태가 됩니다. 다시 말해, y= ax의 일차함수와 같은
선형 모델에 도달하지 않는 그래프로 묘사됩니다.
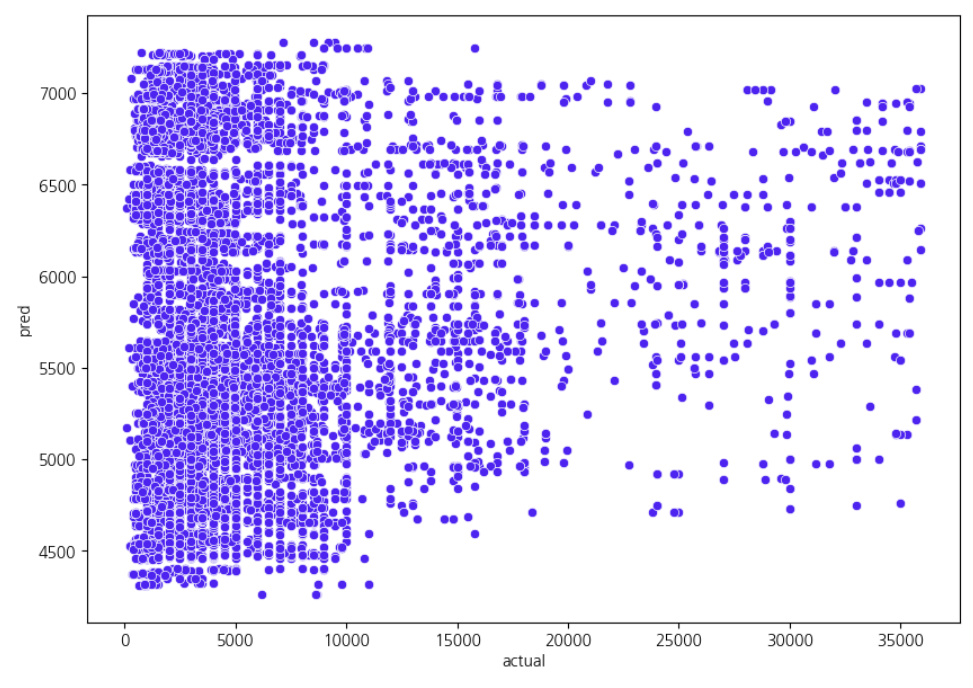
결정계수 최적화에 다가가고자 하는 노력이 다음 단계의 Ridge회귀, 결정트리, 랜덤포레스트 모델,
또한 CV를 추가한 LightGBM모델로 이어집니다.
'머신러닝 > 지도학습' 카테고리의 다른 글
| [Machine learning 평가] Pipeline 형태, Classifier의 평가지표{confusion matrix, 혼동오류, f1 score 개념} (0) | 2023.02.10 |
|---|---|
| [Feature engineering] 데이터 처리 사례_2021 서울시 농산물 가격 분석_2 (0) | 2023.01.02 |
| [Machine Learning] Kaggle_데이터셋 분석_미 초소형 기업 밀도 예측_ep.2 (0) | 2022.12.31 |
| [Machine Learning] Kaggle_데이터셋 분석_미 초소형 기업 밀도 예측 (0) | 2022.12.30 |
| [Machine Learning] Kaggle_데이터셋 분석_Video_Games_Sales.1 (0) | 2022.12.29 |



